Legibility is the product large software companies sell. Legible work is estimable, plannable, and explainable, even if it’s less efficient. Illegible work—fast patches, favors, side channels—gets things done but is invisible to executive oversight. Companies value legibility because it enables planning, compliance, and customer trust.
Small teams move faster because they remain illegible. They skip coordination rituals, roadmap alignment, and approval processes. As companies grow, this speed is sacrificed in favor of legibility. Large orgs trade efficiency for predictability.
Enterprise revenue drives the need for legibility. Large customers demand multi-quarter delivery guarantees, clear escalation paths, and process visibility. To win and retain these deals, companies adopt layers of coordination, planning, and status reporting.
Urgent problems bypass process through sanctioned illegibility. Companies create strike teams or tiger teams that skip approvals, break rules, and act fast. These teams rely on senior engineers, social capital, and informal coordination. Their existence confirms that normal processes are too slow for real emergencies.
I stay motivated on big projects by chasing visible progress. I break the work into small pieces I can see or test now, not later. I start with backends that are easy to unit test, then sprint to scrappy demos. I aim for good enough, not perfect, so I can move to the next demo. I build only what I need to use the thing myself, then iterate as real use reveals gaps.
Five takeaways: decompose into demoable chunks; write tests to create early wins; build quick demos regularly; adopt your own tool fast; loop back to improve once it works for you. Main advice: always give myself a good demo, do not let perfection block progress, optimize for momentum, build only what I need now, iterate later with purpose.
Building relationships before you need them. That random coffee with someone from the data team? Six months later, they’re your biggest advocate for getting engineering resources for your data pipeline project.
Understanding the real incentives. Your VP doesn’t care about your beautiful microservices architecture. They care about shipping features faster. Frame your technical proposals in terms of what they actually care about.
Managing up effectively. Your manager is juggling competing priorities you don’t see. Keep them informed about what matters, flag problems early with potential solutions, and help them make good decisions. When they trust you to handle things, they’ll fight for you when it matters
Creating win-win situations. Instead of fighting for resources, find ways to help other teams while getting what you need. It doesn’t have to be a zero-sum game.
Being visible. If you do great work but nobody knows about it, did it really happen? Share your wins, present at all-hands, write those design docs that everyone will reference later.
The article is a practical tour of lossless compression, focusing on how common schemes balance three levers: compression ratio, compression speed, and decompression speed. It explains core building blocks like LZ77 and Huffman coding, then dives into DEFLATE as used by gzip, before comparing speed and ratio tradeoffs across Snappy, LZ4, Brotli, and Zstandard. It also highlights implementation details from Go’s DEFLATE, and calls out features like dictionary compression in zstd.
Treat it as a data-flow problem. Centralize logging through one pipeline and one library. Make it the only way to emit logs and the only way to view them.
Transform data early. Favor minimization, then redaction; consider tokenization or hashing; treat masking as last resort. Apply before crossing trust boundaries or logger calls.
Introduce domain primitives for secrets. Stop passing raw strings. Give secrets types/objects that default to safe serialization and require explicit unwraps.
Use read-once wrappers. Allow a single, intentional read; any second read throws. This turns accidental logging into a loud failure in tests and staging.
Own the log formatter. Enforce structured JSON. Traverse objects, drop risky paths (e.g., headers, request, response.body), redact known fields, and block generic .toString().
Add taint checking. Mark sources (decrypt, DB reads, request bodies). Forbid sinks (logger). Whitelist sanitizers (tokenize). Run in CI and on large diffs; expect rules to evolve.
Test like a pessimist. Capture stdout/stderr; fail tests on unredacted secrets. In prod, redact; in tests, error. Cover hot paths that produce “kitchen sinks.”
Scan on the pipeline. Use secret scanners in CI and at the log ingress. Prefer sampling per-log-type over a flat global rate so low-volume types still get scanned.
Insert a pre-processor hop. Put Vector/Fluent Bit between emitters and storage to redact, drop, tokenize, and sample for heavy scanners before persistence.
Invest in people. Teach “secret vs sensitive,” publish paved paths, and make it safe and fast to report leaks.
Lay the foundation. Align on a definition of “secret,” move to structured logs, and consolidate emit/view into one pipeline. Expect to find more issues at first; that’s progress.
Map the data flow. Draw sources, sinks, and side channels. Include front-end analytics, ALB/NGINX access logs, error trackers, and any bypasses of your main path.
Fortify chokepoints. Put most controls where all logs must pass: the library, formatter, CI taint rules, scanners, and the pre-processor. Pull teams onto the paved path.
Apply defense-in-depth. Pair every preventative with a detective one step downstream. If formatter redacts, scanners verify. If types prevent, tests break on regressions.
Plan response and recovery. When a leak happens: scope, restrict access, stop the source, clean stores and indexes, restore access, run a post-mortem, and harden to prevent recurrence.
Ruud van Asseldonk’s article The YAML Document from Hell critiques YAML as overly complex and error-prone compared to JSON. Through detailed examples, he shows how YAML’s hidden features, ambiguous syntax, and inconsistent versioning can produce confusing or dangerous outcomes, making it risky for configuration files.
Key Takeaways
YAML’s complexity stems from numerous features and a large specification, unlike JSON’s simplicity and stability.
Ambiguous syntax such as 22:22 may be parsed as a sexagesimal number in YAML 1.1 but as a string in YAML 1.2.
Tags (!) and aliases (*) can lead to invalid documents or even security risks, since untrusted YAML can trigger arbitrary code execution.
The “Norway problem” highlights how literals like no or off become false in YAML 1.1, leading to unexpected values.
Non-string keys (e.g., on) may be parsed as booleans, creating inconsistent mappings across parsers and languages.
Unquoted strings resembling numbers (e.g., 10.23) are often misinterpreted as numeric values, corrupting intended data.
YAML version differences (1.1 vs 1.2) mean the same file may parse differently across tools, causing portability issues.
Popular libraries like PyYAML or Go’s yaml use hybrid or outdated interpretations, making reliable parsing difficult.
The abundance of edge cases (63+ string syntaxes) makes YAML unpredictable and fragile in real-world use.
Author’s recommendation: avoid YAML when correctness and predictability are critical, and prefer simpler formats like JSON.
If you were to build your own database today, not knowing that databases exist already, how would you do it? In this post, we'll explore how to build a key-value database from the ground up.
Cross-platform automated activity tracker with watchers for active window titles and AFK detection. Data stored locally; JSONL and SQLite via modules. Add aw-watcher-input to count keypresses and mouse movement without recording the actual keys.
Take a break and relax
Workrave is a free program that assists in the recovery and prevention of Repetitive Strain Injury (RSI). It monitors your keyboard and mouse usage and using this information, it frequently alerts you to take microbreaks, rest breaks and restricts you to your daily computer usage.
It’s a personal “ADHD wiki” by Roman Kogan: short, plain-language pages that explain common adult ADHD patterns (e.g., procrastination, perfectionism, prioritizing, planning), with concrete coping tips and meme-style illustrations; sections include ideas like “Body Double” and “False Dependency Chain.”
Low quality data causes measurable cognitive decline in LLMs
The authors report that continually pretraining on junk data leads to statistically meaningful performance drops, with Hedges' g > 0.3 across reasoning, long context understanding, and safety.
This suggests that data quality alone, holding training scale constant, can materially degrade core capabilities of a model. Actionable insight: data going into continual pretraining is not neutral, and "more data" is not automatically better.
Study tests 11 data formats for LLM table comprehension using GPT-4.1-nano on 1,000 records and 1,000 queries. Accuracy varies by format. Markdown-KV ranks highest at 60.7 percent, CSV and JSONL rank lowest near mid 40s. Higher accuracy costs more tokens, Markdown-KV uses about 2.7 times CSV. Markdown tables offer a balance of readability and cost. Use headers and consider repeating them for long tables. Results are limited to one model and one dataset. Try format transforms in your pipeline to improve accuracy, and validate on your own data.
I built a useful AI assistant using a single SQLite memories table and a handful of cron jobs running on Val.town. It sends my wife and me daily Telegram briefs powered by Claude, and its simplicity makes it both reliable and fun to extend.
The system centers on one memories table and a few scheduled jobs. Each day’s brief combines next week’s dated items and undated background entries.
I wrote small importers that run hourly or weekly: Google Calendar events, weather updates, USPS Informed Delivery OCR via Claude, Telegram and email messages, and even fun facts.
Everything runs entirely on Val.town — storage, HTTP endpoints, scheduled jobs, and email.
The assistant delivers a daily summary to Telegram and answers ad hoc reminders or queries on demand.
I designed a “butler” persona and a playful admin UI through casual “vibe coding.”
Instead of starting with a complex agent or RAG setup, I focused on simple, inspectable building blocks, planning to add RAG only when needed.
I shared all the code on Val.town for others to fork, though it’s not a packaged app.
What Are the AI Darwin Awards?
Named after Charles Darwin's theory of natural selection, the original Darwin Awards celebrated those who "improved the gene pool by removing themselves from it" through spectacularly stupid acts. Well, guess what? Humans have evolved! We're now so advanced that we've outsourced our poor decision-making to machines.
The AI Darwin Awards proudly continue this noble tradition by honouring the visionaries who looked at artificial intelligence—a technology capable of reshaping civilisation—and thought, "You know what this needs? Less safety testing and more venture capital!" These brave pioneers remind us that natural selection isn't just for biology anymore; it's gone digital, and it's coming for our entire species.
Because why stop at individual acts of spectacular stupidity when you can scale them to global proportions with machine learning?
This methodology provides a structured approach for collaborating with AI systems on software development projects. It addresses common issues like code bloat, architectural drift, and context dilution through systematic constraints and validation checkpoints.
The writeup explains how to make AI coding agents productive in large, messy codebases by treating context as the main engineering surface. The core method is frequent intentional compaction: repeatedly distilling findings, plans, and decisions into short, structured artifacts, keeping the active window lean, using side processes for noisy exploration, and resetting context to avoid drift. The piece sits alongside a YC talk and HumanLayer tools that operationalize these practices for teams.
Create progress.md to track objective, constraints, plan, decisions, next steps.
Keep a short spec.md with intent, interfaces, acceptance checks.
Work in small verifiable steps; open tiny PRs with one change each.
Reset context often; reload only spec and latest progress.md.
Leave headroom in context; do not fill the window to max.
Use side scratchpads or subagents for noisy searches; paste back only distilled facts.
Prefer simple, fast tokenization with a cached peek and a rewindable savepoint instead of building token arrays or trees. See Tiny C Compiler’s one-pass design for inspiration: Tiny C Compiler documentation.
Parse expressions without an AST using a right-recursive, precedence-aware function that sometimes returns early when the parent operator has higher precedence. This is equivalent in spirit to Pratt or precedence-climbing parsing. A clear tutorial: Simple but Powerful Pratt Parsing.
When a later token retroactively changes meaning, rewind to a saved scanner position and re-parse with the new mode rather than maintaining an AST.
Start with a trivial linear IR using value numbers and stack slots so you can get codegen working early.
Treat variables as stack addresses in the naive IR, but in the optimized pipeline treat variables as names bound to prior computations, not places in memory.
Generate control flow with simple labels and conditional branches, then add else, while, and defer by re-parsing the relevant scopes from savepoints to emit the missing pieces.
Inline small functions by jumping to the callee’s source, parsing it as a scope, and treating a return as a jump to the end of the inlined region.
Move to a Sea-of-Nodes SSA graph as the optimization IR so that constant folding, CSE, and reordering fall out of local rewrites. Overview and history: Sea of nodes on Wikipedia and Cliff Click’s slide deck: The Sea of Nodes and the HotSpot JIT.
Hash-cons nodes to deduplicate identical subgraphs and attach temporary keep-alive pins while constructing; remove pins to let unused nodes free. A hands-on reference implementation: SeaOfNodes/Simple.
Represent control with If nodes that produce projections, merge with Region nodes, and merge values with Phi nodes. A compact SSA primer: Static single-assignment form and LLVM PHI example: SSA and PHI in LLVM IR.
Convert the Sea-of-Nodes graph back to a CFG using Global Code Motion; then eliminate Phi by inserting edge moves. Foundational paper: Global Code Motion / Global Value Numbering.
Build a dominator tree and schedule late to avoid hoisting constants and work into hot blocks. A modern overview of SSA placement and related algorithms: A catalog of ways to generate SSA.
Prefer local peephole rewrites applied continuously as you build the graph; ensure the rewrite set is confluent enough to terminate. A readable walkthrough with code and GCM illustrations: Sea of Nodes by Fedor Indutny.
Keep memory effects simple at first by modeling loads, stores, and calls on a single control chain; only add memory dependence graphs once everything else is stable.
For debug info, insert special debug nodes that capture in-scope values at control points so later scheduling and register allocation can still recover variable locations.
Expect tokenizer speed to matter when you rely on rewinds; invest in fast scanning and cached peek results.
In language design, favor unique top-level keywords so you can pre-scan files, discover declarations, and compile procedure bodies in parallel.
Know the current landscape. Sea-of-Nodes is widely used, but some engines have moved away for language-specific reasons; see V8’s 2025 write-up: Land ahoy: leaving the Sea of Nodes.
Expression parsing without an AST, with early return on higher-precedence parent
// precedence: larger = binds tighter. e.g., '*' > '+' intprec(TokenKind op); bool parse_expr(Scanner* S,int parent_prec, Value* out); // parse a primary or unary, then loop binary ops of >= parent_prec bool parse_expr(Scanner* S,int parent_prec, Value* out){ Value lhs; if(!parse_unary_or_primary(S,&lhs))return false; for(;;){ Token op =peek(S); if(!is_binary(op.kind))break; int myp =prec(op.kind); if(myp <= parent_prec)break;// go-left-sometimes: return to parent consume(S);// eat operator Value rhs; if(!parse_expr(S, myp,&rhs))return false; lhs =emit_binop(op.kind, lhs, rhs);// compute or build IR } *out = lhs; return true; }
Rewind on forward knowledge
Savepoint sp =mark(&scanner); Value v; bool ok =parse_expr(&scanner,-1,&v); if(ok &&peek(&scanner).kind == TOK_DOLLAR){ consume(&scanner); rewind(&scanner, sp); set_mode(EXPR_MODE_DOLLAR_PLUS);// switch semantics ok =parse_expr(&scanner,-1,&v);// re-parse }
Toy linear IR with value numbers and stack slots
// vN are SSA-like value numbers, but we spill everything initially. intv_lit(int64_t k);// emit literal -> v# intv_addr(StackSlot s);// address-of a local -> v# intv_load(int v_addr);// load [v_addr] -> v# voidv_store(int v_addr,int v_val);// store v_val -> [v_addr] voidbr_eqz(int v_cond, Label target);
Phi and region construction at a merge
int then_x =build_then(...);// returns value number int else_x =build_else(...); Region r =new_region(); int phi_x =new_phi(r, then_x, else_x);// SSA merge point bind_var(env,"x", phi_x);
Global code motion back to a CFG and Phi removal
// For each block that flows into region R with phi v = phi(a from B1, b from B2): // insert edge moves at end of predecessors, then kill phi. emit_in(B1,"mov v <- a"); emit_in(B2,"mov v <- b"); remove_phi(R, v);
Tokenizer performance matters because you will peek and rewind frequently.
Ensure your rewrite set terminates; run to a fixed point in release builds and assert progress stops.
Keep memory ordering strict at first by threading loads, stores, and calls on the control chain; only then add memory dependence edges.
Dominance and latest safe placement are key for late scheduling; compute the dominator tree over the finalized CFG and sink work accordingly. Background: Code motion.
Sea-of-Nodes is powerful but not universal; language and runtime constraints may push you toward different IRs, as V8 discusses here: Land ahoy: leaving the Sea of Nodes.
Use vibe coding for throwaway and legacy work, not for core craftsmanship.
Name the mode: agentic coding vs vibe coding, and pick deliberately.
Prefer small local code over extra dependencies when the task is tiny.
Use AI to replace low-value engineering, not engineers.
"You still need to know how code works if you want to be a coder."
I keep the skill floor high. If I feel the tool exceeding my understanding, I stop, turn off the agent, and read. I ask chat to teach, not to substitute thinking. I refuse the comfort of not knowing because comfort in ignorance is corrosive. If the tool is better than me at the task, I train until that is no longer true, then use the tool as a multiplier rather than a crutch.
"The majority of code we write is throwaway code."
I point vibe coding at disposable work: scripts, scaffolding, glue, UI boilerplate, exploratory benchmarks. I optimize for speed, learning, and deletion, not polish. Good code solves the right problem and does not suck to read; here I bias the first trait and accept that readability is optional when the artifact is destined to be forgotten. I ship, test the idea, and freely discard because throwing it away never hurts.
"Agentic coding is using prompts that use tools to then generate code. Vibe coding is when you don't read the code after."
I name the mode so I do not confuse capabilities with habits. Agentic flows can plan edits across a repo; vibe coding is a behavior choice to stop reading and just prompt. If I neither know nor read the code, I am stuck. If I know the code and sometimes choose not to read it for low-stakes tasks, I am fast. Clear terms prevent hype and let me pick the right tool for the job.
"You cant be mad at vibe coding and be mad at left-pad."
For tiny problems, I keep ownership by generating a few lines locally instead of importing yet another dependency with alien opinions. When a package bites, patching generated local code is easier than vendoring the world. Vibe coding solves the same pain that excessive deps create, but without surrendering control of the codebase.
"Vibe coding isn't about replacing engineers. Its about replacing engineering."
I aim AI at the low-value engineering I never wanted to do: a quick SVG->PNG converter in the browser, a square image maker for YouTube previews, lightweight benchmarking harnesses. These are small, tailor-made tools that unlock output with near-zero ceremony. Experts remain essential for the hard parts; AI just clears the gravel so we can climb.
I used to treat leadership like armor. Stand in front. Be strong. Say yes. Keep moving. Then my own body called time. One night my heart raced past 220. The doctor said drive in. The nurse called an ambulance. It was not a heart attack, but it was close enough to stop me. That was the day I learned burnout is an invisible injury. You look fine. You are not.
The signs were there for weeks. I stopped sleeping. I lost motivation. My focus frayed. I snapped at home. I withdrew. My personality shifted. People saw the change before I did. If you notice this in yourself or in a colleague, ask the simple question: are you OK. That question can be the lifeline.
The causes were obvious in hindsight. Too much work, all channels open, phone always on. Unclear expectations I filled with extra effort. A culture that prized speed over quality. Isolation. Perfectionism. I tried to deliver 100 percent on everything. That is expensive in hours and in health. Ask what is good enough. Leave room to breathe.
Recovery was not heroic. It was slow and dull and necessary. I accepted that I was sick even if no one could see it. I told people. That made everyday life less awkward and it cut the shame. My days became simple: wake, breakfast, long walk, read, sleep, repeat. Minus 20 or pouring rain, I walked. Some days I felt strong and tried to do too much. The next day I crashed. I learned to pace. Think Amundsen, not Scott. Prepare. March the same distance in bad weather and good. Quality every day beats bursts and collapses.
Talking helped. Family, colleagues, a professional if you need it. Do not keep it inside. Burnout is now a described syndrome of unmanaged work stress. You are not unique in this, and that is a relief. The earlier you talk, the earlier you can turn. There are stages. I hit the last one. You do not need to.
Returning to work took time. Six months from ambulance to office. Do not sprint back. Start part time. Expect bumps. Leaders must make space for this. Do not load the diesel engine on a frozen morning. Warm it first. If you lead, build a ramp, not a wall.
I changed how I use time. I own my calendar. I block focus time before other people fill my week. I add buffers between meetings. I add travel time. I prepare on purpose. I ask why I am needed. I ask what is expected. If there is no answer, I decline. I say no when I am tired or when I will not add value. I reschedule when urgency is fake. Many meetings become an email or a short call when you ask the right question.
I changed how I care for the basics. I set realistic goals. I move every day. Long walks feed the brain. I go to bed on time. I protect rest. I learned to say no and to hold the line. I built places to recharge. For me it is a cabin and a fire. Quiet. Books. Music. You find your own battery and you guard it.
I changed how I lead. Psychological safety is not a slide. It is daily behavior. We build trust. We keep confidences. We invite dissent and keep respect. We cheer good work and we say the missing word: thank you. Recognition costs little and pays back a culture where people speak up before they break. I aim for long term quality over quick gains. The 20 mile march beats the sprint for the next quarter. Greatness is choice and discipline, not luck.
I dropped the mask. Pretending to be superhuman drains energy you need for the real work. I am the same person at home and at work. I can be personal. I can admit fear. I can cry. That honesty gives others permission to be human too. It also prevents the slow leak of acting all day.
On motivation, I look small and near. You do not need fireworks every morning. You need a reason. Clean dishes. A solved bug. A customer who can sleep because the system is stable. Ask why. Ask it again. Clear purpose turns effort into progress. When the honeymoon buzz fades, purpose stays.
If you are early on this path, take these moves now. Notice the signs. Talk sooner. Cut the always-on loop. Define good enough. Pace like Amundsen. If you are coming back, ramp slowly and let others help. If you lead, design conditions for health: time to think, time to rest, time to do quality work. Own the calendar. Guard the buffers. Reward preparation. Thank people. And remember the simplest goal. Wake up. You are here. Build from there.
Key Takeaways – The Real Bottleneck in Software Development (and How AI Should Actually Help)
Writing code was never the bottleneck – Shipping slow isn’t because typing is slow. Code reviews, testing, debugging, knowledge transfer, coordination, and decision-making are the real pace-setters.
Processes kill speed when misused – Long specs, excessive meetings, and rigid “research → design → spec → build → ship” flows often lock in bad assumptions before real user feedback happens.
Prototype early, prototype often – Fast, rough builds are a cheap way to learn if an idea is worth pursuing. The goal is insight, not production-grade quality at first.
Optimize for “time to next realization” – The fastest path from assumption to new learning wins. Use prototypes to expose wrong assumptions before investing heavily.
Throwaway code vs. production code – Treat them differently. Throwaway code is for learning, experiments, and iteration; production code is for maintainability and scale. Confusing the two makes AI tools look worse than they are.
AI’s best use is speeding up iteration, not replacing devs – Let AI help create quick prototypes, test tech approaches, and refine concepts. Don’t just use it to auto-generate bloated specs or production code you don’t understand.
Bad specs cost more than slow typing – If research and design start from faulty assumptions, all the downstream work is wasted. Prototypes fix this by providing a working reference early.
Smaller teams + working prototypes = better communication – Three people iterating on a small demo is more effective than 20 people debating a massive spec.
Culture shift needed – Many engineers and PMs resist prototypes, clinging to big upfront design. This causes conflict when AI makes rapid prototyping possible.
Fun matters – Iterating on ideas with quick feedback loops is engaging. Endless Jira tickets and reviewing AI-generated slop are not.
Main warning – If AI tools only make it easier to produce large amounts of code without improving understanding, you slow down the real bottleneck: team alignment and decision-making.
1. Organize by feature folders, not by technical layer
Group controllers, views, view models, client assets, and tests by feature to increase cohesion and make adding or removing a feature localized. This applies equally to MVC, Razor Pages, Blazor, and React front ends.
2. Treat warnings as errors
Fail the build on warnings to keep the codebase clean from day 1. Prefer project-wide MSBuild setting. For full coverage across tasks, also use the CLI switch.
3. Prefer structured logging with Serilog via ILogger, enrich with context
Use structured properties rather than string concatenation, enrich logs with correlation id, user id, request url, version, etc. Always program against ILogger and configure Serilog only in bootstrap.
Code:
// Program.cs Log.Logger = new LoggerConfiguration() .Enrich.FromLogContext() .WriteTo.Console() .CreateLogger(); builder.Host.UseSerilog((ctx, lc) => lc .ReadFrom.Configuration(ctx.Configuration)); // In a handler/service public Task Handle(Guid userId) { _logger.LogInformation("Retrieving user {@UserId}", userId); return Task.CompletedTask; }
4. Distinguish logs vs metrics vs audits; store audits in your primary data store
Keep developer-focused logs separate from business metrics; store audit trails where loss is unacceptable in your transactional store, not only in logs. Security and compliance often require retention beyond default log windows.
5. Secure by default with a global fallback authorization policy
Make endpoints require authentication unless explicitly opted out by AllowAnonymous or a policy override.
8. Inject options as a POCO by registering the Value
Keep Options pattern at the edges and inject your settings class directly to consumers by registering the bound value; use IOptionsSnapshot when settings can change per request.
Code:
// Program.cs builder.Services.Configure<MyAppSettings>(builder.Configuration.GetSection("MyApp")); builder.Services.AddSingleton(sp => sp.GetRequiredService<IOptions<MyAppSettings>>().Value); // Consumer public sealed class WidgetService(MyAppSettings settings) { ... }
9. Favor early returns and keep the happy path at the end
Minimize nesting, return early for error and guard cases, and let the successful flow be visible at the bottom of a method for readability.
10. Adopt the new XML solution format .slnx
The new .slnx format is human-readable XML, reduces merge conflicts, and is supported by the dotnet CLI and Visual Studio.
11. Add HTTP security headers
Enable CSP, X-Frame-Options, Referrer-Policy, Permissions-Policy, etc., or use a helper package with sane defaults. Test with securityheaders.com.
Code:
// Using NetEscapades.AspNetCore.SecurityHeaders app.UseSecurityHeaders(policies => policies.AddDefaultSecurityHeaders() .AddContentSecurityPolicy(b => b.BlockAllMixedContent()));
12. Build once, deploy many; prefer trunk-based development
Use a single long-lived main branch, short-lived feature branches, and promote the same build artifact through environments.
14. Write automated tests; prefer xUnit, upgrade to v3
Automated tests improve speed and reliability. xUnit v3 is current and supports the new Microsoft testing platform.
16. Log EF Core SQL locally by raising the EF category to Information
Enable Microsoft.EntityFrameworkCore.Database.Command at Information to see executed SQL. Use only for development.
17. CI/CD and continuous deployment with feature toggles; ship in small batches
Aim for pipelines that deploy green builds to production; replace manual checks with automated tests; use feature flags to keep unfinished work dark.
A high-level tour of Programming in Modern C with a Sneak Peek into C23 (by Dawid Zalewski) shows how C remains alive and evolving. The talk focuses on practical, post-C99 techniques, especially useful in systems and embedded work. It demonstrates idioms that improve clarity, safety, and ergonomics without giving up low-level control.
Topics covered
Modern initialization
Brace and designated initializers, empty initialization {} in C23, and mixed positional and designated forms.
Arrays
Array designators, rules for inferred array size, and guidance on when to avoid variable-length arrays as storage while still using VLA syntax to declare function parameter bounds.
Pointer and API contracts
Sized array parameters T a[n], static qualifiers like T a[static 3] to require valid elements, and const char *static 1 to enforce non-null strings.
Multidimensional data
Strongly typed pointers to VLA-shaped arrays for natural a[i][j] indexing and safer sizeof expressions.
Compound literals
Creating unnamed lvalues to reassign structs, pass inline structs to functions, and zero objects succinctly.
Macro patterns
Named-argument style wrappers around compound literals, simple defaults, _Generic for ad-hoc overloading by type, and a macro trick for argument-count dispatch.
Memory layout
Flexible array members for allocating a header plus payload in one contiguous block, reducing double-allocation pitfalls.
C23 highlights
New keywords for bool, true, and false, the nullptr constant, auto type inference in specific contexts, a note on constexpr, and current compiler support caveats.
I spend my time writing code that gets real work done, and I rely on aggressive code reuse. In C that means I bring a better replacement for the C standard library to the party.
Key advice for writing C
Build your own reusable toolkit. My answer was stb: single-file, public-domain utilities that replace weak parts of libc.
Use dynamic arrays and treat them like vectors. I use macros so that arr[i] works and capacity/length live in bytes before the pointer.
Prefer hash tables and dynamic arrays by default. They make small programs both simpler and usually faster.
Be pragmatic with the C standard library. Use printf, malloc, free, qsort; avoid footguns like gets and be careful with strncpy and realloc.
Handle realloc safely. Assign to a temp pointer first, then swap it back if allocation succeeds.
Do not cache dynamic array lengths. It is a source of bugs when the array grows or shrinks.
Accept small inefficiencies if they improve iteration speed. Optimize only when it affects the edit-run loop or output.
Workflow and productivity
Remove setup friction. I keep a single quick.c workspace I can open, type, build, and run immediately.
Automate the boring steps. I have a one-command install that copies today’s build into my bin directory.
Write tiny, disposable tools. 5 to 120 minute utilities solve real problems now and often get reused later.
Favor tools that make easy things easy. Avoid frameworks that only make complicated things possible but make simple things tedious.
Keep programs single-file when you can. Deployment matters for speed and reuse.
Code reuse and licensing philosophy
Make reuse non-negotiable. I do not want to rewrite the same helper twice.
Ship as single-header libraries and make them easy to drop in. Easy to deploy, easy to use, easy to license.
Public domain licensing removes friction for future me and everyone else.
Language and ecosystem perspective
C can be great for small programs if you fix the library problem and streamline your workflow.
Conciseness matters. Shorter code usually means faster writing and iteration.
I choose C over dynamic languages for these tasks because my toolkit gives me comparable concision with better control.
API and library design principles
Simple, focused APIs with minimal surface area.
Make the common path trivial. Optional flexibility is fine, but do not tax the simple case.
Prefer data and functions over deep hierarchies or heavy abstractions.
The real question isn’t whether you’ll make mistakes; it’s what you do after.
I recently read “Good Inside” by Dr. Becky Kennedy, a parenting book that completely changed how I think about this. She talks about how the most important parenting skill isn’t being perfect — it’s repair. When you inevitably lose your patience with your kid or handle something poorly, what matters most is going back and fixing it. Acknowledging what happened, taking responsibility, and reconnecting.
Sound familiar? Because that’s what good management is about too.
Think about the worst manager you ever had. I bet they weren’t necessarily the ones who made the most mistakes. But they were probably the ones who never acknowledged them. Who doubled down when they were wrong. Who let their ego prevent them from admitting they didn’t have all the answers.
Cate Hall explains how increasing your “surface area”―the combination of doing meaningful work and making it visible―invites more serendipity. By writing, attending events, joining curated communities, and reaching out directly, you raise the probability that unexpected opportunities will find you.
Key Takeaways
Luck is not random; it grows when valuable work is paired with consistent public sharing.
Publishing ideas extends your reach indefinitely; a single post can keep generating inquiries for years.
Showing up at meetups, conferences, or gatherings multiplies chance encounters that can turn into collaborations.
Curated communities act as quality filters, putting you in front of people who already share your interests and standards.
Thoughtful, high‑volume cold outreach broadens your network and seeds future partnerships.
Deep expertise built on genuine passion attracts attention and referrals more naturally than broad generalism.
Balance is critical: “doing” without “telling” hides impact, while “telling” without substance destroys credibility.
Serendipity compounds over time; treat visibility efforts as long‑term investments, not quick wins.
Track views, replies, and introductions to identify which activities generate the most valuable contacts.
Most engineers have a complicated relationship with their managers. And by “complicated,” I mean somewhere between mild annoyance and seething resentment. Having been on both sides of this — more than a decade as an engineer before switching to management — I’ve experienced this tension from every angle.
Here’s the uncomfortable truth: engineers often have good reasons to be frustrated with their managers. But understanding why this happens is the first step toward fixing (or just coping with?) it.
Let me walk you through the most common management anti-patterns that make engineers want to flip tables — and stick around, because I’ll also share what the best managers do differently to actually earn their engineers’ respect.
If you’re an engineer, you’ll probably nod along thinking “finally, someone gets it.” If you’re a manager, well… you might recognize yourself in here. And that’s okay — awareness is the first step.
Bad engineers think their job is to write code. Good engineers know their job is to ship working software that adds real value to users.
Bad engineers dive straight into implementation. Good engineers first ask “why?”. They know that perfectly executed solutions to the wrong problems are worthless. They’ll push back — not to be difficult, but to find the simplest path to real value. “Can we ship this in three parts instead of one big release?” “What if we tested the riskiest assumption first?”
Bad engineers work in isolation, perfecting their code in darkness. Good engineers share early and often. They’ll throw up a draft PR after a few hours with “WIP – thoughts on this approach?” They understand that course corrections at 20% are cheap; but at 80% are expensive.
Bad engineers measure their worth by the complexity of their solutions. They build elaborate architectures for simple problems, write clever code that requires a PhD to understand, and mistake motion for progress. Good engineers reach for simple solutions first, write code their junior colleagues can maintain, and have the confidence to choose “boring” technology that just works.
Bad engineers treat code reviews as battles to be won. They defend every line like it’s their firstborn child, taking feedback as personal attacks. Good engineers see code reviews differently — they’re opportunities to teach and learn, not contests. They’ll often review their own PR first, leaving comments like “This feels hacky, any better ideas?” They know that your strengths are your weaknesses, and they want their teammates to catch their blind spots.
Bad engineers say yes to everything, drowning in a sea of commitments they can’t keep. Good engineers have learned the art of the strategic no. “I could do that, but it means X won’t ship this sprint. Which is more important?”.
Bad engineers guard knowledge like treasure, making themselves indispensable through obscurity. Good engineers document as they go, pair with juniors, and celebrate when someone else can maintain their code. They know job security comes from impact, not from being a single point of failure.
Bad engineers chase the newest framework, the hottest language, the latest trend. They’ve rewritten the same app four times in four different frameworks. Good engineers are pragmatists. They’ll choose the tech that the team knows, the solution that can be hired for, the approach that lets them focus on the actual problem.
Bad engineers think in absolutes — always DRY, never compromise, perfect or nothing. Good engineers know when to break their own rules, when good enough truly is good enough, and when to ship the 80% solution today rather than the 100% solution never.
Bad engineers write code. Good engineers solve problems. Bad engineers focus on themselves. Good engineers focus on their team. Bad engineers optimize for looking smart. Good engineers optimize for being useful.
The best engineers I’ve worked with weren’t necessarily the smartest — they were simply the most effective. And effectiveness isn’t about perfection. It’s about progress.
The SecureAnnex blog post “Mellow Drama: Turning Browsers Into Request Brokers” investigates a JavaScript library called Mellowtel, which is embedded in hundreds of browser extensions. This library covertly leverages user browsers to load hidden iframes for web scraping, effectively creating a distributed scraping network. The behavior weakens security protections like Content-Security-Policy, and participants include Chrome, Edge, and Firefox users—nearly one million installations in total. SecureAnnex traces this operation to Olostep, a web scraping API provider.
Takeaways:
Widespread involuntary participation
Mellowtel is embedded in 245 browser extensions across Chrome, Edge, and Firefox, with around 1 million active installations as of July 2025.
Library functionality explained
The script activates during user inactivity, strips critical security headers, injects hidden iframes, parses content via service workers, and exfiltrates data to AWS Lambda endpoints.
Monetization-driven inclusion
Developers integrated Mellowtel to monetize unused bandwidth. The library operates silently using existing web access permissions.
Olostep’s connection
Olostep, run by Arslan Ali and Hamza Ali, appears to be behind Mellowtel and uses it to power their scraping API for bypassing anti-bot defenses.
Security implications
Removing headers like Content-Security-Policy and X-Frame-Options increases risk of XSS, phishing, and internal data leaks, especially in corporate settings.
Partial takedown by browser vendors
Chrome, Edge, and Firefox have begun removing some affected extensions, but most remain available and active.
Shady transparency practices
Some extensions vaguely mention monetization or offer small payments, but disclosures are often misleading or obscured.
Mitigation and detection guidance
Users should audit installed extensions, block traffic to request.mellow.tel, and restrict iframe injection and webRequest permissions.
Community-driven defense
Researchers like John Tuckner are sharing IOCs and YARA rules to detect compromised extensions and raise awareness.
Broader security trend
This incident exemplifies a growing class of browser-based supply chain attacks using benign-looking extensions as distributed scraping nodes.
Did you ever wonder how QR codes work? You've come to the right place! This is an interactive explanation that we've written for a workshop at 37C3, but you can also use it on your own. You will learn:
The anatomy of QR codes
How to decode QR codes by hand (using our cheat sheet)
I build external scaffolding so my brain has fewer places to drop things: memory lives in a single todo list, and the one meta habit is to open it every morning; projects get their own entries so half-read books and half-built ideas do not evaporate; I keep the list pinned on the left third of the screen so it is always in my visual field. I manage energy like voltage: early morning is for the thing I dread, mid-day is for creative work, later is for chores; when I feel avoidance, I treat procrastination by type—do it scared for anxiety, ask a human to sit with me for accountability, and write to think when choice paralysis hits; timers manufacture urgency to start and, importantly, to stop so one project does not eat the day. I practice journaling across daily, weekly, monthly, yearly reviews to surface patterns and measure progress; for time, I keep a light calendar for social and gym blocks and add explicit travel time so I actually leave; the todo list holds the fine-grained work, the calendar holds the big rocks.
On the ground I favor task selection by shortest-first, with exceptions for anything old and for staying within the active project; I do project check-ins—even 15 minutes of reading the code or draft—to refresh caches so momentum is cheap; I centralize inboxes by sweeping mail, chats, downloads, and bookmarks into the list, run Inbox Zero so nothing camouflages, and declare bankruptcy once to reset a swampy backlog. I plan first, do later so mid-task derailments do not erase intent—walk the apartment, list every fix, then execute; I replace interrupts with polling by turning on DND and scheduling comms passes; I do it on my own terms by drafting scary emails in a text editor or mocking forms in a spreadsheet before pasting; I watch derailers like morning lifting, pacing, or music and design around them; I avoid becoming the master of drudgery who optimizes the system but ships nothing; when one task blocks everything, I curb thrashing by timeboxing it daily and moving other pieces forward; and I pick tools I like and stick to one, because one app is better than two and building my own is just artisan procrastination.
ADHD, productivity, todo list, journaling, energy management, procrastination, timers, inbox zero, task selection, planning, timeboxing, focus, tools
Flat subscriptions cannot scale
The assumption that margins would expand as LLMs became cheaper is flawed. Users always want the best model, which keeps a constant price floor.
AI Subscriptions Get Short Squeezed
Token usage per task is exploding
Tasks that used ~1k tokens now often consume 100k or more due to long reasoning chains, browsing, and planning.
Unlimited plans are collapsing
Anthropic announced weekly rate limits for Claude subscribers starting August 28, 2025.
Anthropic news update
Heavy users (“inference whales”) break economics
Some Claude Code customers consumed tens of thousands of dollars in compute while only paying $200/month.
The Register reporting
Shift toward usage credits
Cursor restructured pricing: Pro plans now include credits with at-cost overages, plus a new $200 Ultra tier.
Cursor pricing page
Here’s What You’re Going to Learn
First, we’ll explore how to genuinely achieve a 10x productivity boost—not through magic, but through deliberate practices that amplify AI’s strengths while compensating for its weaknesses.
Next, I’ll walk you through the infrastructure we use at Julep to ship production code daily with Claude’s help. You’ll see our CLAUDE.md templates, our commit strategies, and guardrails.
Most importantly, you’ll understand why writing your own tests remains absolutely sacred, even (especially) in the age of AI. This single principle will save you from many a midnight debugging sessions.
Steve Yegge brilliantly coined the term CHOP—Chat-Oriented Programming in a slightly-dramatic-titled post “The death of the junior developer”. It’s a perfect, and no-bs description of what it’s like to code with Claude.
There are three distinct postures you can take when vibe-coding, each suited to different phases in the development cycle:
AI as First-Drafter: Here, AI generates initial implementations while you focus on architecture and design. It’s like having a junior developer who can type at the speed of thought but needs constant guidance. Perfect for boilerplate, CRUD operations, and standard patterns.
AI as Pair-Programmer: This is the sweet spot for most development. You’re actively collaborating, bouncing ideas back and forth. The AI suggests approaches, you refine them. You sketch the outline, AI fills in details. It’s like pair programming with someone who has read every programming book ever written but has never actually shipped code.
AI as Validator: Sometimes you write code and want a sanity check. AI reviews for bugs, suggests improvements, spots patterns you might have missed. Think of it as an incredibly well-read code reviewer who never gets tired or cranky.
Instead of crafting every line, you’re reviewing, refining, directing. But—and this cannot be overstated—you remain the architect. Claude is your intern with encyclopedic knowledge but zero context about your specific system, your users, your business logic.
Model Context Protocol (MCP) helps AI apps connect with different tools and data sources more easily. Usually, if many apps need to work with many tools, each app would have to build a custom connection for every tool, which becomes complicated very quickly. MCP fixes this by creating one common way for apps and tools to talk. Now, each app only needs to understand MCP, and each tool only needs to support MCP.
An AI app that uses MCP doesn't need to know how each platform works. Instead, MCP servers handle the details. They offer tools the AI can use, like searching for files or sending emails, as well as prompts, data resources, and ways to request help from the AI model itself. In most cases, it's easier to build servers than clients.
The author shares a simple example: building an MCP server for CKAN, a platform that hosts public datasets. This server allows AI models like Claude to search and analyze data on CKAN without any special code for CKAN itself. The AI can then show summaries, lists of datasets, and even create dashboards based on the data.
MCP has become popular because it gives a clear and stable way for AI apps to work with many different systems. But it also adds some extra work. Setting up MCP takes time, and using too many tools can slow down AI responses or lower quality. MCP works best when you need to integrate many systems, but may not be necessary for smaller, controlled projects where fine-tuned AI models already perform well.
ai integration, model context protocol, simple architecture, ckan, open data, ai tools, tradeoffs, protocol design
The Architecture Overview - Started as a README. "Here's what this thing probably does, I think."
The Technical Considerations - My accumulated frustrations turned into documentation. Every time Claude had trouble, we added more details.
The Workflow Process - I noticed I kept doing the same dance. So I had Claude write down the steps. Now I follow my own instructions like they're sacred text. They're not. They're just what happened to work this time.
The Story Breakdown - Everything in 15-30 minute chunks. Why? Because that's roughly how long before Claude starts forgetting what we discussed ten minutes ago. Like a goldfish with a PhD.
It's like being a professional surfer on an ocean that keeps changing its physics. Just when you think you understand waves, they start moving sideways. Or backwards. Or turning into birds.
This is either terrifying or liberating, depending on your relationship with control.
This approach uses C macros combined with struct designated initializers to mimic optional, default, and named parameters in C, something the language does not natively support.
Core Idea
Separate mandatory and optional parameters
Mandatory arguments are given as normal function parameters.
Optional parameters are bundled into a struct with sensible defaults.
Designated initializers for named parameter-like syntax
You can specify only the fields you want to override, in any order.
Unspecified fields automatically keep the default values.
Macro wrapper to simplify usage
The macro accepts the mandatory arguments and any number of struct field assignments for optional parameters.
Inside the macro, a default struct is created and then overridden with user-provided values.
The article "Parse, Don’t Validate AKA Some C Safety Tips" by Lelanthran expands on the concept of converting input into strong types rather than merely validating it as plain strings. It demonstrates how this approach, when applied in C, reduces error-prone code and security risks. The post outlines three practical benefits: boundary handling with opaque types, safer memory cleanup via pointer‑setting destructors, and compile‑time type safety that prevents misuse deeper in the codebase.
Key Takeaways:
Use Strong, Opaque Types for Input
Instead of handling raw char *, parse untrusted input into dedicated types like email_t or name_t.
This restricts raw input to the system boundary and ensures all later code works with validated, structured data.
Reduce Attack Surface
Only boundary functions see untrusted strings; internal functions operate on safe, strongly typed data.
This prevents deeper code from encountering malformed or malicious input.
Enforce Correctness at Compile Time
With distinct types, the compiler prohibits misuse, such as passing an email_t* to a function expecting a name_t*.
What would be a runtime bug becomes a compiler error.
Implement Defensive Destructors
Design destructor functions to take a double pointer (T **) so they can free and then set the pointer to NULL.
This prevents double‑free errors and related memory safety issues.
Eliminate Internal String Handling
By centralizing parsing near the system entry and eliminating char * downstream, code becomes safer and clearer.
Once input is parsed, the rest of the system works with well-typed data only.
Tags: Emacs, Emacs Lisp, Elisp, Programming, Text Editor, Customization, Macros, Buffers, Control Flow, Pattern Matching
A comprehensive guide offering a conceptual overview of Emacs Lisp to help users effectively customize and extend Emacs.
Emphasizes the importance of understanding Emacs Lisp for enhancing productivity and personalizing the Emacs environment.
Covers foundational topics such as evaluation, side effects, and return values.
Explores advanced concepts including macros, pattern matching with pcase, and control flow constructs like if-let*.
Discusses practical applications like buffer manipulation, text properties, and function definitions.
Includes indices for functions, variables, and concepts to facilitate navigation.
This resource is valuable for both beginners and experienced users aiming to deepen their understanding of Emacs Lisp and leverage it to tailor Emacs to their specific workflows.
This package generates pretty, responsive, websites from .org files and your choice of Emacs themes. You can optionally specify a header, footer, and additional CSS and JS to be included. To see the default output, for my chosen themes and with no header, footer or extras, view this README in your browser here. If you’re already there, you can find the GitHub repo here.
Define clear, long-term project goals: dependability, extendability, team scalability, and sustained velocity before writing any code, so every subsequent decision aligns with these objectives. Dependability keeps software running for decades; extendability welcomes new features without rewrites; team scalability lets one person own each module instead of forcing many into one file; sustained velocity prevents the slowdown that occurs when fixes trigger more breakage. Listing likely changes such as platform APIs, language toolchains, hardware, shifting priorities, and staff turnover guides risk mitigation and keeps the plan realistic.
Encapsulate change inside small black-box modules that expose only a stable API, allowing one engineer to own, test, and later replace each module without disturbing others. Header-level boundaries cut meeting load, permit isolated rewrites, and match task difficulty to developer experience by giving complex boxes to seniors and simpler ones to juniors.
Write code completely and explicitly the first time, choosing clarity over brevity to prevent costly future rework. Five straightforward lines now are cheaper than one clever shortcut that demands archaeology years later.
Shield software from platform volatility by funnelling all OS and third-party calls through a thin, portable wrapper that you can port once and reuse everywhere. A tiny demo app exercises every call, proving a new backend before millions of downstream lines even compile.
Build reusable helper libraries for common concerns such as rendering, UI, text, and networking, starting with the simplest working implementation but designing APIs for eventual full features so callers never refactor. A bitmap font renderer, for example, already accepts UTF-8, kerning, and color so a future anti-aliased engine drops in invisibly.
Keep domain logic in a UI-agnostic core layer and let GUIs or headless tools interact with that core solely through its published API. A timeline core powers both a desktop video editor and a command-line renderer without duplicating logic.
Use plugin architectures for both user features and platform integrations, loading optional capabilities from separate binaries to keep the main build lean and flexible. In the Stellar lighting tool, every effect and even controller input ships as an external module, so missing a plugin merely disables one function, not the whole app.
Migrate legacy systems by synchronizing them through adapters to a new core store, enabling gradual cut-over while exposing modern bindings such as C, Python, and REST. Healthcare events recorded in the new engine echo to the old database until clinics finish the transition.
Model real-time embedded systems as a shared authoritative world state that edge devices subscribe to, enabling redundancy, simulation, and testing without altering subscriber code. Sensors push contacts, fuel, and confidence scores into the core; wing computers request only the fields they need, redundant cores vote for fault tolerance, and the same channel feeds record-and-replay tools for contractors.
Design every interface, file format, and protocol to be minimal yet expressive, separating structure from semantics so implementations stay simple and evolvable. Choosing one primitive such as polygons, voxels, or text avoids dual support, keeps loaders small, and lets any backend change without touching callers.
Prefer architectures where external components plug into your stable core rather than embedding your code inside their ecosystems, preserving control over versioning and direction. Hosting the plugin point secures compatibility rules and leaves internals free to evolve.
Focus on making actual games and software people use, not tech demos of rotating cubes; he observes most showcases are rendering stress tests instead of finished games.
Prioritize design because top-selling Steam games succeed on gameplay design, not just graphics; he cites "Balatro" competing with "Civilization 7".
Always ask "What do we do that they don't?" to define your product’s unique hook; he references the Sega Genesis ad campaign as an example of aspirational marketing.
Start from a concrete player action or interaction (e.g., connecting planets in "Slipways", rewinding time in "Braid") rather than from story or vibe.
Use genres as starting templates to get an initial action set, then diverge as you discover your own twist; he compares "Into the Breach" evolving from "Advance Wars".
Skip paper prototyping for video games; rely on the computer to run simulations and build low-friction playable prototypes instead.
Prototype with extremely low-fidelity art and UI; examples include his own early "Moose Solutions" and the first "Balatro" mockups.
Beat blank-page paralysis by immediately putting the first bad version of a feature into the game without overthinking interactions; iterate afterward.
Let the running game (the simulation) reveal what works; you are not Paul Atreides, you cannot foresee every system interaction.
Move fast in code: early entities can just be one big struct; do not over-engineer ECS or architecture in prototypes.
Use simple bit flags (e.g., a u32) for many booleans to get minor performance without heavy systems.
Combine editor and game into one executable so you can drop entities and test instantly; he shows his Cave Factory editor mode.
Do not obsess over memory early; statically allocate big arenas, use scratch and lifetime-specific arenas, and worry about optimization later.
Never design abstractions up front; implement features, notice repetition, and then compress into functions/structs (Casey Muratori’s semantic compression).
Avoid high-friction languages/processes (Rust borrow checking, strict TDD) during exploration; add safety and tests only after proving people want the product.
Do not hire expensive artists during prototyping; you will throw work away. Bring art in later, like Jonathan Blow did with "Braid".
Spend real money on capsule/storefront art when you are shipping because that is your storefront on Steam.
Keep the team tiny early; people consume time and meetings. If you collaborate, give each person a clear lane.
Build a custom engine only when the gameplay itself demands engine-level control (examples: "Fez" rotation mechanic, "Noita" per-pixel simulation).
If you are tinkering with tech (cellular automata, voxel sims), consciously pivot it toward a real game concept as the Noita team did.
Cut distractions; social media is a time sink. Optimize for the Steam algorithm, not Twitter likes.
Let streamers and influencers announce and showcase your game instead of doing it yourself to avoid social media toxicity.
Do not polish and ship if players are not finishing or engaging deeply; scrap or rework instead of spending on shine.
Tie polish and art budget to gameplay hours and depth; 1,000-hour games like Factorio justify heavy investment.
Shipping a game hardens your tech; the leftover code base becomes your engine for future projects.
Low-level programming is power, but it must be aimed at a marketable design, not just technical feats.
Play many successful indie games as market research; find overlap between what you love and what the market buys.
When you play for research, identify the hook and why people like it; you do not need to finish every game.
Treat hardcore design like weight training; alternate intense design days with lighter tasks (art, sound) to recover mentally.
Prototype while still employed; build skills and a near-complete prototype before quitting.
Know your annual spending before leaving your job; runway is meaningless without that number.
Aim for a long runway (around two years or more) to avoid the high cost of reentering the workforce mid-project.
Do not bounce in and out of jobs; it drains momentum.
Save and invest to create a financial buffer (FIRE-style) so you can focus on games full time.
Maintain full control and ownership of your tech to mitigate platform risk (Unity’s policy changes are cited as a cautionary tale).
Stanford research group has conducted a multi‑year time‑series and cross‑sectional study on software‑engineering productivity involving more than 600 companies
Current dataset: over 100,000 software engineers, dozens of millions of commits, billions of lines of code, predominantly from private repositories
Late last year analysis of about 50,000 engineers identified roughly 10 percent as ghost engineers who collect paychecks but contribute almost no work
Study team members include Simon (former CTO of a 700‑developer unicorn), a Stanford researcher active since 2022 on data‑driven decision‑making, and Professor Kasinski (Cambridge Analytica whistleblower)
A 43‑developer experiment showed self‑assessment of productivity was off by about 30 percentile points on average; only one in three developers ranked themselves within their correct quartile
The research built a model that evaluates every commit’s functional change via git metadata, correlates with expert judgments, and scales faster and cheaper than manual panels
At one enterprise with 120 developers, introducing AI in September produced an overall productivity boost of about 15–20 percent and a marked rise in rework
Across industries gross AI coding output rises roughly 30–40 percent, but net average productivity gain after rework is about 15–20 percent
Median productivity gains by task and project type: low‑complexity greenfield 30–40 percent; high‑complexity greenfield 10–15 percent; low‑complexity brownfield 15–20 percent; high‑complexity brownfield 0–10 percent (sample 136 teams across 27 companies)
AI benefits low‑complexity tasks more than high‑complexity tasks and can lower productivity on some high‑complexity work
For high‑popularity languages (Python, Java, JavaScript, TypeScript) gains average about 20 percent on low‑complexity tasks and 10–15 percent on high‑complexity tasks; for low‑popularity languages (Cobol, Haskell, Elixir) assistance is marginal and can be negative on complex tasks
Productivity gains decline sharply as codebase size grows from tens of thousands to millions of lines
LLM coding accuracy drops as context length rises: performance falls from about 90 percent at 1 k tokens to roughly 50 percent at 32 k tokens (NoLIMA paper)
Key factors affecting AI effectiveness: task complexity, project maturity, language popularity, codebase size, and context window length
James Eastham shares hard‑won lessons on maintaining and evolving event‑driven systems after the initial excitement fades. Using a plant‑based pizza app as a running example (order → kitchen → delivery), he covers how to version events, test asynchronous flows, ensure idempotency, apply the outbox pattern, build a generic test harness, and instrument rich observability (traces, logs, metrics). The core message: your events are your API, change is inevitable, and reliability comes from deliberate versioning, requirements‑driven testing, and context‑rich telemetry.
Key Takeaways (9 items)
Treat events as first‑class APIs; version them explicitly (e.g. type: order.confirmed.v1) and publish deprecation dates so you never juggle endless parallel versions.
Adopt a standard event schema (e.g. CloudEvents) with fields for id, time, type, source, data, and data_content_type; this enables compatibility checks, idempotency, and richer telemetry. https://cloudevents.io
Use the outbox pattern to atomically persist state changes and events, then have a worker publish from the outbox; test that both the state row and the outbox row exist, not just your business logic.
Build a reusable test harness subscriber: spin up infra locally (Docker, Aspire, etc.), inject commands/events, and assert that expected events actually appear on the bus; poll with SLO‑aligned timeouts to avoid flaky tests.
Validate event structure at publish time with schema checks (JSON Schema, System.Text.Json contract validation) to catch breaking changes before they hit the wire.
Test unhappy paths: duplicate deliveries (at‑least‑once semantics), malformed payloads, upstream schema shifts, and downstream outages; verify DLQs and idempotent handlers behave correctly.
Instrument distributed tracing plus rich context: technical (operation=send/receive/process, system=kafka/sqs, destination name, event version) and business (order_id, customer_id) so you can answer unknown questions later. See OpenTelemetry messaging semantic conventions: https://opentelemetry.io/docs/specs/semconv/messaging
Decide when to propagate trace context vs use span links: propagate within a domain boundary, link across domains to avoid 15‑hour monster traces from batch jobs.
Monitor the macro picture too: queue depth, message age, in‑flight latency, payload size shifts, error counts, and success rates; alert on absence of success as well as presence of failure.
This talk by Sean from OpenAI explores the paradigm shift from code-centric software development to intent-driven specification writing. He argues that as AI models become more capable, the bottleneck in software creation will no longer be code implementation but the clarity and precision with which humans communicate their intentions. Sean advocates for a future where structured, executable specifications—not code—serve as the core professional artifact. Drawing on OpenAI’s model specification (Model Spec), he illustrates how specifications can guide both human alignment and model behavior, serving as trust anchors, training data, and test suites. The talk concludes by equating specification writing with modern programming and calls for new tooling—like thought-clarifying IDEs—to support this transition.
Code is Secondary; Communication is Primary
Only 10–20% of a developer's value lies in the code they write; the remaining 80–90% comes from structured communication—understanding requirements, planning, testing, and translating intentions.
Effective communication will define the most valuable programmers of the future.
Vibe Coding Highlights a Shift in Workflow
“Vibe coding” with AI models focuses on expressing intent and outcomes first, letting the model generate code.
Yet, developers discard the prompt (intent) and keep only the generated code—akin to version-controlling a binary but shredding the source.
Specifications Align Humans and Models
Written specs clarify, codify, and align intentions across teams—engineering, product, legal, and policy.
OpenAI’s Model Spec (available on GitHub) exemplifies this, using human-readable Markdown that is versioned, testable, and extensible.
Specifications Outperform Code in Expressing Intent
Code is a lossy projection of intention; reverse engineering code does not reliably recover the original goals or values.
A robust specification can generate many artifacts: TypeScript, Rust, clients, servers, docs, even podcasts—whereas code alone cannot.
Specs Enable Deliberative Alignment
Using techniques like deliberative alignment, models are evaluated and trained using challenging prompts linked to spec clauses.
This transforms specs into both training and evaluation material, reinforcing model alignment with intended values.
This talk, titled "Branding Your Types", is delivered by Theo from the Danish Broadcasting Corporation. It explores the concept of branded types in TypeScript—a compile-time technique to semantically differentiate values of the same base type (e.g., different kinds of string or number) without runtime overhead.
Theo illustrates how weak typing with generic primitives like string can introduce subtle and costly bugs, especially in complex codebases where similar-looking data (e.g., URLs, usernames, passwords) are handled inconsistently.
The talk promotes a mindset of parsing, not validating—emphasizing data cleaning and refinement at the edges of systems, ensuring internal business logic can remain clean, type-safe, and predictable.
Generic Primitives Are Dangerous
Treating all strings or numbers the same can lead to bugs (e.g., swapped username and password). Using string to represent IDs, dates, booleans, or URLs adds ambiguity and increases cognitive load.
Use Branded Types for Clarity and Safety
TypeScript allows developers to brand primitive types with compile-time tags (e.g., Username, Password, RelativeURL) to distinguish otherwise identical types. This prevents bugs by catching misused values during compilation.
No Runtime Cost, Full Type Safety
Branded types are purely a TypeScript feature; they vanish during transpilation. You get stronger type guarantees without impacting performance or runtime behavior.
Protect Your Business Logic with Early Parsing
Don’t validate deep within your core logic. Instead, parse data from APIs or forms as early as possible. Converting "dirty" input into refined types early allows the rest of the code to assume correctness.
Parsing vs. Validation
Inspired by Alexis King’s blog post “Parse, Don’t Validate”, Theo stresses that parsing should transform unstructured input into structured, meaningful types. Validations check, but parsing commits and transforms.
Use types to encode guarantees
Replace validate(x): boolean with parse(x): Result<T, Error>. This enforces correctness via types, ensuring only valid data proceeds through the system.
Parse at the boundaries
Parse incoming data at the system’s edges (e.g. API handlers), and keep the rest of the application logic free from unverified values.
Avoid repeated validation logic
Parsing once eliminates the need for multiple validations in different places, reducing complexity and inconsistency.
Preserve knowledge through types
Using types like Maybe or Result lets you carry the status of values through your code rather than flattening them prematurely.
Demand strong input, return flexible output
Functions should accept well-formed types (e.g. NonEmptyList<T>) and return optional or error-aware outputs.
Capitalize on language features
Statically typed languages (e.g. Haskell, Elm, TypeScript) support defining precise types that embed business rules—use them.
Structured data beats flags
Avoid returning booleans to indicate validity. Instead, return parsed data or detailed errors to make failures explicit.
Better testing and fewer bugs
Strong input types reduce the number of test cases needed and prevent entire categories of bugs from entering the system.
Design toward domain modeling
Prefer domain-specific types like Email, UUID, or URL rather than generic strings—improves readability and safety.
Applicable across many languages
Though examples come from functional programming, the strategy works in many ecosystems—Elm, Haskell, Kotlin, TypeScript, etc.
Parse, Don’t Validate
The Parse, Don’t Validate approach emphasizes transforming potentially untrusted or loosely-structured data into domain-safe types as early as possible in a system. This typically happens at the "edges"—where raw input enters from the outside world (e.g. HTTP requests, environment variables, or file I/O). Instead of validating that the data meets certain criteria and continuing to use it in its original form (e.g. raw string or any), this pattern calls for parsing: producing a new, enriched type that encodes the constraints and guarantees. For example, given a JSON payload containing an email field, you wouldn’t just check whether the email is non-empty or contains “@”; you'd parse it into a specific Email type that can only be constructed from valid input. This guarantees that any part of the system which receives an Email value doesn’t need to perform checks—it can assume the input is safe by construction.
The goal of parsing is to front-load correctness and allow business logic to operate under safe assumptions. This leads to simpler, more expressive, and bug-resistant code, especially in strongly-typed languages. Parsing typically returns a result type (like Result<T, Error> or Option<T>) to indicate success or failure. If parsing fails, the error is handled at the boundary. Internally, the program deals only with parsed, safe values. This eliminates duplication of validation logic and prevents errors caused by invalid data slipping past checks. It also improves the readability and maintainability of code, as type declarations themselves serve as documentation for business rules. This approach does not inherently enforce encapsulation or behavior within types—it’s more about asserting the shape and constraints of data as early and clearly as possible. Parsing can be implemented manually (e.g. via custom functions and type guards) or with libraries (like zod, io-ts, or Elm’s JSON decoders).
Value Objects
The Value Object pattern, originating from Domain-Driven Design (DDD), is focused on modeling business concepts explicitly in the domain layer. A value object is an immutable, self-contained type that represents a concept such as Money, Email, PhoneNumber, or Temperature. Unlike simple primitives (string, number), value objects embed both data and behavior, enforcing invariants at construction and encapsulating domain logic relevant to the value. For instance, a Money value object might validate that the currency code is valid, store amount and currency together, and expose operations like add or convert. Value objects are compared by value (not identity), and immutability ensures they are predictable and side-effect free.
The key distinction in value objects is that correctness is enforced through encapsulation. You can't create an invalid Email object unless you bypass the constructor or factory method (which should be avoided by design). This encapsulated validation is often combined with private constructors and public factory methods (tryCreate, from, etc.) to ensure that the only way to instantiate a value object is through validated input. This centralizes responsibility for maintaining business rules. Compared to Parse, Don’t Validate, value objects focus more on modeling than on data conversion. While parsing is concerned with creating safe types from raw data, value objects are concerned with expressing the domain in a way that’s aligned with business intent and constraints.
In practice, value objects may internally use a parsing step during construction, but they emphasize type richness and encapsulated logic. Where Parse, Don’t Validate advocates that you return structured types early for safety, Value Objects argue that you return behavior-rich types for expressiveness and robustness. The two can—and often should—be used together: parse incoming data into value objects, and rely on their methods and invariants throughout your core domain logic. Parsing is about moving from unsafe to safe. Value objects are about enriching the safe values with meaning, rules, and operations.
Range library for C++14/17/20. This code was the basis of a formal proposal to add range support to the C++ standard library. That proposal evolved through a Technical Specification, and finally into P0896R4 "The One Ranges Proposal" which was merged into the C++20 working drafts in November 2018.
About
Ranges are an extension of the Standard Template Library that makes its iterators and algorithms more powerful by making them composable. Unlike other range-like solutions which seek to do away with iterators, in range-v3 ranges are an abstraction layer on top of iterators.
Range-v3 is built on three pillars: Views, Actions, and Algorithms. The algorithms are the same as those with which you are already familiar in the STL, except that in range-v3 all the algorithms have overloads that take ranges in addition to the overloads that take iterators. Views are composable adaptations of ranges where the adaptation happens lazily as the view is iterated. And an action is an eager application of an algorithm to a container that mutates the container in-place and returns it for further processing.
Views and actions use the pipe syntax (e.g., rng | adapt1 | adapt2 | ...) so your code is terse and readable from left to right.
Summary: Building Rock-Solid Encrypted Applications – Ben Dechrai
Ben Dechrai walks through building a secure chat application, starting with plain-text messages and evolving to an end-to-end encrypted, multi-device system. He explains how to apply AES symmetric encryption, Curve25519 key pairs, and Diffie-Hellman key exchange. The talk covers how to do secure key rotation, share keys across devices without leaks, scale encrypted messaging systems without data bloat, and defend against metadata analysis.
Key Insights
Encryption is mandatory
Regulatory frameworks like GDPR allow fines up to €20 million or 4% of annual global revenue. See GDPR Summary – EU Commission
Encrypt the symmetric key for each participant
Encrypt the actual message once with AES, then encrypt the AES key for each recipient using their public key. This avoids the large ciphertext problem seen in naive PGP-style encryption.
Rotate ephemeral keys regularly for forward secrecy
Generate a new key pair for each chat session and rotate keys on time or message count to ensure Perfect Forward Secrecy. See Cloudflare on Perfect Forward Secrecy
Use Diffie-Hellman to agree on session keys securely
Clients can agree on a shared secret without sending it over the wire. This makes it possible to use symmetric encryption without needing to exchange the key. See Wikipedia: Diffie–Hellman Key Exchange
Use QR codes to securely pair devices
When onboarding a second device (e.g. laptop + phone), generate keys locally and transfer only a temporary public key via QR. Use it to establish identity without a central login.
Mask metadata to avoid traffic analysis
Even encrypted messages can leak patterns through metadata. Pad messages to fixed sizes, send decoy traffic, and let all clients pull all messages to make inference harder.
Adopt battle-tested protocols like Signal
Don’t invent your own protocol if you're building secure messaging. The Signal Protocol already solves identity, authentication, and key ratcheting securely. See Signal Protocol Specification
Store only ciphertext and public keys on servers
All decryption happens on the device. Retaining private keys or decrypted messages is risky unless legally required. Private key loss or compromise must only affect a small slice of messages, not entire histories.
I built 1,000 architects using AI—each with a name, country, skillset, and headshot
I asked a language model to make me architect profiles. I told it their gender, country, and years of experience. Then I got it to generate a photo too. I used tools like DALL-E and ChatGPT to get realistic images.
They all designed the same web app—based on a spec for a startup called Loom Ventures
I created a pretend company and asked for a functional spec (nothing too crazy—blogs, search, logins, some CMS). Then I gave that spec to every AI architect and asked each to give me a full software design in Markdown.
I made them battle it out, tournament style, until we found “the best” design
At first, designs were grouped and reviewed by four other architects (randomly picked). The best ones moved on to knockout rounds. In the final round, the last two designs were judged by all remaining architects.
The reviews weren’t just random—they had reasons and scores
Each reviewer gave a score out of 100 and explained why. I asked them to be clear, compare trade-offs, and explain how well the design met the client's needs. The reviews came out in JSON so I could process them easily.
Experience and job titles really affected scores
If a design said it was written by a “junior” architect, it got lower marks—even if the content was decent. When I removed the titles and re-ran reviews, scores jumped by 15%. So even the AIs showed bias.
Early mistakes in the prompt skewed my data badly
My first example profile included cybersecurity, and the AI just kept making cyber-focused architects. Nearly all designs were security-heavy. I had to redo everything with simpler prompts and let the model be more creative.
The best designs added diagrams, workflows, and Markdown structure
The winning entries used flowcharts (Mermaid), ASCII diagrams, and detailed explanations. They felt almost like something you’d see in a real architecture doc. A lot better than a wall of plain text.
Personas from different countries mentioned local laws
That was cool. The architects from Australia talked about the APP (privacy laws). The ones from Poland mentioned GDPR. That means the AI was paying attention to the persona’s background.
Software 3.0 builds on earlier paradigms: It extends Software 1.0 (explicit code) and Software 2.0 (learned neural networks) by allowing developers to program using prompts in natural language.
Prompts are the new source code: In Software 3.0, well-crafted prompts function like programs and are central to instructing LLMs on what to do, replacing large parts of traditional code.
LLMs act as computing platforms: Language models serve as runtime engines, available on demand, capable of executing complex tasks, and forming a new computational substrate.
Feedback loops are essential: Effective use of LLMs involves iterative cycles—prompt, generate, review, and refine—to maintain control and quality over generated outputs.
Jagged intelligence introduces unpredictability: LLMs can solve complex problems but often fail on simple tasks, requiring human validation and cautious deployment.
LLMs lack persistent memory: Since models don’t retain long-term state, developers must handle context management and continuity externally.
“Vibe coding” accelerates prototyping: Rapid generation of code structures via conversational prompts can quickly build scaffolds but should be used cautiously for production-grade code.
Security and maintainability remain concerns: Generated code may be brittle, insecure, or poorly understood, necessitating rigorous testing and oversight.
Multiple paradigms must coexist: Developers should blend Software 1.0, 2.0, and 3.0 techniques based on task complexity, clarity of logic, and risk tolerance.
Infrastructure reliability is critical: As LLMs become central to development workflows, outages or latency can cause significant disruption, underscoring dependency risks.
When self-centered car dealer Charlie Babbitt learns that his estranged father's fortune has been left to an institutionalized older brother he never knew, Raymond, he kidnaps him in hopes of securing the inheritance. What follows is a transformative cross-country journey where Charlie discovers Raymond is an autistic savant with extraordinary memory and numerical skills. The film’s uniqueness lies in its sensitive portrayal of autism and the emotional evolution of a man reconnecting with family through empathy and acceptance.
Leonard Shelby suffers from short-term memory loss, unable to form new memories after a traumatic event. He relies on Polaroid photos and tattoos to track clues in his obsessive search for his wife's killer. Told in a non-linear, reverse chronology that mirrors Leonard’s disoriented mental state, the film uniquely immerses the viewer in the protagonist’s fractured perception, making the mystery unravel in a mind-bending and emotionally charged fashion.
Henry Roth, a commitment-phobic marine veterinarian in Hawaii, falls for Lucy Whitmore, a woman with anterograde amnesia who forgets each day anew after a car accident. To win her love, he must make her fall for him again every day. The film blends romantic comedy with neurological drama, and its charm comes from turning a memory disorder into a heartfelt and humorous exploration of persistence, love, and hope.
Database performance optimization includes caching, read replicas, and CQRS but involves complexity and eventual consistency trade-offs.
Microservices address team and scalability issues but require careful handling of inter-service communication, fault tolerance, and increased operational complexity.
Modular monoliths, feature flags, blue-green deployments, and experimentation libraries like Scientist effectively mitigate deployment risks and complexity.
This talk peels back the hype around microservices and asks why our bold leap into dozens—or even hundreds—of tiny, replaceable services has sometimes left us tangled in latency, brittle tests and orchestration nightmares. Drawing on the 1975 Fundamental Theory of Software Engineering, the speaker reminds us that splitting a problem into “manageably small” pieces only pays off if those pieces map to real business domains and stay on the right side of the intramodule vs intermodule cost curve. Through vivid “death star” diagrams and anecdotes of vestigial “restaurant hours” APIs, we see how team availability, misunderstood terminology and the lure of containers have driven us toward the anti-pattern of nano-services.
The remedy is framed via the 4+1 architectural views and a return to purpose-first design: start with a modular monolith until your domain boundaries—and team size—demand independent services; adopt classic microservices for clear subdomains owned by two-pizza teams; or embrace macroservices when fine-grained services impose too much overhead. By aligning services to business capabilities, designing for failure, and choosing process types per the 12-factor model, we strike the balance where cognitive load is low, deployments stay smooth and each component remains genuinely replaceable.
Tags: microservices, modular monolith, macroservices, bounded context, domain storytelling, 4+1 architecture, service granularity, team topologies
Understand that time is your most valuable asset because, unlike energy and money, you cannot create more of it; recognizing time’s finite nature shifts your mindset to treat each moment as critical.
When the number of tasks exceeds your capacity, you experience task saturation, which leads to decreased cognitive ability and increased stress; acknowledging this helps you avoid inefficiency and negative self-perception.
Apply the “subtract two” rule by carrying out two fewer tasks than you believe you can handle simultaneously; reducing your focus allows you to allocate more resources to each task and increases overall productivity.
Use operational prioritization by asking, “What is the next task I can complete in the shortest amount of time?”; this elementary approach leverages time’s objectivity to build momentum and confidence as you rapidly reduce your task load.
In high-pressure or dangerous situations, focus on executing the next fastest action—such as seeking cover—because immediate, simple decisions create space and momentum for subsequent choices that enhance survival.
Combat “head trash,” the negative self-talk that arises when you’re overwhelmed, by centering on the next simplest task; staying grounded in rational, achievable actions prevents emotional derailment and keeps you moving forward.
Practice operational prioritization consistently at home and work so that when you reach task saturation, doing the next simplest thing becomes an automatic response; repeated drilling transforms this method into a reliable tool that fosters resilience and peak performance.
Tags: time management, task saturation, operational prioritization, productivity, decision making, CIA methods, cognitive load, stress management, momentum, next-task focus, head trash, high-pressure situations, survival mindset, resource allocation, time as asset
“with a PC keyboard. it bridges an electrical circuit to send a signal to your computer.” As typing evolved from mechanical typewriters to touchscreen apps, “software has become increasingly developed to serve its creators more than the users.” In many popular keyboards, “it sends everything you typed in that text field to somebody else's computer,” and “they say they may then go and train AI models on your data.” Even disabling obvious data-sharing options doesn’t fully stop collection—“in swift key there's a setting to share data for ads personalization and it's enabled by default.”
FUTO Keyboard addresses this by offering a fully offline experience: “it's this modern keyboard that has a more advanced auto correct,” and “the app never connects to the internet.” It provides “Swipe to Type,” “Smart Autocorrect,” “Predictive Text,” and “Offline Voice Input.” Its source code is under the “FUTO Source First License 1.1,” and it guarantees “no data collected” and “no data shared with third parties.”
privacy, offline, swipe typing, voice input, open source
Dude, I’ve just been thinking a lot about how much we rely on the internet — like, way too much. Social media, video games, just endless scrolling — it’s all starting to feel like we’re letting the internet run our lives, you know? And yeah, I’m not saying we need to go full Amish or anything — there’s definitely real meaning you can find online, I’ve made some of my closest friends here. But we can’t keep letting it eat up all our time and attention. I’ve been lucky, my parents didn’t let me get video games as a kid, so I learned early on to find value outside of screens. But even now, it’s so easy to get sucked into that doom-scrolling hole — like, one minute you’re checking YouTube, and suddenly three hours are gone. We’ve gotta train ourselves, catch those moments, and build real focus again. It's not about quitting everything cold turkey, unless that works for you — it’s about moderation and making sure you’ve got stuff in your life that isn’t just online.
internet dependence, social media, balance, personal growth, generational habits
I’ve been thinking a lot about something I call change energy. Everyone’s got a different threshold for how much change they can handle — their living situation, work, even what they eat. Too much stability feels boring, but too much change feels overwhelming. It’s all about where you sit on that spectrum.
For me, I don’t love moving, I burn out fast while traveling, but when it comes to my work, I need some change to stay engaged — not so much that everything’s new every day, but not so little that it gets stale. Developers usually sit on the lower end of that spectrum at work: stuck in old codebases, hungry for something fresh, constantly exploring new frameworks and tools because they’re not hitting their change threshold on the job.
Creators, though? It’s the opposite. We’re maxed out every single day. Every video has to be new, every thumbnail, every format — constant change. So any extra change outside of the content feels like too much. That’s why I didn’t adopt Frame.io for over a year, even though I knew it would help — I simply didn’t have the change energy to spare.
This difference is why creator tools are hard to sell to great creators: they're already burning all their change energy on making content. Meanwhile, great developers still have room to try new tools and get excited about them. That realization made us shift from creator tools to dev tools — because that’s where the most excited, curious people are.
meaningful quotes:
"Humans need some level of stability in their lives or they feel like they’re going insane."
"Most great developers are looking for more change. Most great creators are looking for less change."
"Good creators are constantly trying new things with their content, so they’re unwilling to try new things anywhere else."
"We need to feel this mutual excitement. We need to be excited about what we're building and the people that we're showing it to need to be excited as well."
Michael Howard reflects on 25 years of writing Writing Secure Code, sharing insights from his career at Microsoft and the evolution of software security. He emphasizes that while security features do not equate to secure systems, the industry has made significant progress in eliminating many simple vulnerabilities, such as basic memory corruption bugs. However, new threats like server-side request forgery (SSRF) have emerged, highlighting that security challenges continue to evolve. Howard stresses the enduring importance of input validation, noting it remains the root cause of most security flaws even after two decades.
He advocates for a shift away from C and C++ towards memory-safe languages like Rust, C#, Java, and Go, citing their advantages in eliminating classes of vulnerabilities tied to undefined behavior and memory safety issues. Tools like fuzzing, static analysis (e.g., CodeQL), and GitHub's advanced security features play critical roles in identifying vulnerabilities early. Ultimately, Howard underscores that secure code alone isn’t sufficient; compensating controls, layered defenses, threat modeling, and continuous learning are essential. Security storytelling, he notes, remains a powerful tool for driving cultural change within organizations.
Quotes:
“Um, I hate JavaScript. God, I hate JavaScript. There are no words to describe how much I hate JavaScript.”
Context: Michael Howard expressing his frustration with JavaScript during a live fuzzing demo.
“This thing is dumber than a bucket of rocks.”
Context: Describing the simplicity of a custom fuzzer that nonetheless found serious bugs in seconds.
“If you don’t ask, it’s like being told no.”
Context: The life lesson Michael learned when he decided to invite Bill Gates to write the foreword for his book.
“Security features does not equal secure features.”
Context: Highlighting the gap between adding security controls and truly building secure systems.
“All input is evil until proven otherwise.”
Context: A core principle from Writing Secure Code on why rigorous input validation remains critical.
“It’s better to crash an app than to run malicious code. They both suck, but one sucks a heck of a lot less.”
Context: Advocating for secure-by-default defenses that fail safely rather than enable exploits.
“45 minutes later, he emailed back with one word, ‘absolutely.’”
Context: Bill Gates’s rapid, enthusiastic response to writing the second-edition foreword.
“I often joke that I actually know nothing about security. I just know a lot of stories.”
Context: Emphasizing the power of storytelling to make security lessons memorable and drive action.
Caught in a heavy downpour but grateful to be warm and dry inside, the speaker dives into a list of surprisingly useful tools. First is Webcam Eyes, a 200-line shell script that effortlessly mounts most modern cameras as webcams—especially useful for recording with tools like ffmpeg. After testing on multiple Canon and Sony cameras, it proved flawless. Next up is Disk, a colorful, graph-based alternative to df, offering cleaner output and useful export options like JSON and CSV, written in Rust and only marginally slower.
The Pure Bash Bible follows—a compendium of bash-only alternatives to common scripting tasks typically handled by external tools. It emphasizes performance and optimization for shell scripts. Then comes Zephyr, a nested X server useful for window manager development, poorly-behaved applications, or sandboxing within X11. Finally, a patch for cp and mv brings progress bars to these core utilities—helpful when rsync isn’t an option, even if coreutils maintainers deemed these tools “feature complete.”
tools, shell scripting, webcams, disk utilities, bash, X11, developer tools
Overview
The speaker has completed yet another database migration—this time to Convex—and hopes it’s the last. After five grueling years of building and maintaining a custom sync engine and debugging for days on end, they finally reached a setup they trust for their T3 Chat application.
Original Local-First Architecture
IndexedDB + Dexi: Entire client state (threads, messages) was serialized with SuperJSON, gzipped, and stored as one blob. Syncing required blobs to be re-zipped and uploaded whole, leading to race conditions (only one tab at a time), performance bottlenecks, and edge-case bugs in Safari.
Upstash Redis: Moved to Upstash with key patterns like message:userId:uuid, but querying thousands of keys on load proved unsustainable.
PlanetScale + Drizzle: Spun up a traditional SQL schema in two days. Unfortunately, the schema stored only a single SuperJSON field, bloating data and preventing efficient relational queries.
Required Capabilities
Eliminate IndexedDB’s quirks.
One source of truth (no split brain between client and server).
Instant optimistic UI updates for renames, deletions, and new messages.
Resumable AI-generation streams.
Strong signed-out experience.
Unblock the engineering team by offloading sync complexity.
Rejected Alternatives
Zero (Replicache): Required Postgres + custom WebSocket infra and separate schema definitions in SQL, client, and server permissions layers.
Other SDKs/ORMs: All suffered from duplicate definitions and didn’t fully solve client-as-source issues or resumable streams.
Why Convex Won
TypeScript-first application database: Single schema file, no migrations for shape changes.
Permissions in code: Easily enforce row-level security in TS handlers.
Live queries: Any mutation (e.g. updating a message’s title) immediately updates all listeners without manual cache management.
Refactored Message Flow
Create mutations in Convex for new user and assistant messages before calling the AI.
Stream SSE from /api/chat to the client for optimistic token-by-token rendering.
Chunked writes: Instead of re-writing the entire message on every token, batch updates to Convex every 500 ms (future improvement: use a streamId field and Vercel’s resumable-stream helper).
Title generation moved from brittle SSE event parsing & IndexedDB writes to a simple convex.client.mutation('chat/updateTitle', { threadId, title }). The client auto-refreshes via live query.
Migration Path
Feature flag: Users opt into the Convex beta via a settings toggle.
Chunked data import: Server-side Convex mutations ingest threads (500 per chunk), messages (100 per chunk), and attachments from PlanetScale.
Cookie & auth handling: Adjusted HttpOnly, Expires, and JWT parsing (switched from a custom-sliced ID to the token’s subject field) to ensure WebSocket authentication and avoid Brave-specific bugs.
Major Debugging Saga
A rare Open-Auth library change caused early users’ tokens to carry user:… identifiers instead of numeric Google IDs. Only by logging raw JWT fields and collaborating with an early adopter could this be traced—and fixed by reading the subject claim directly.
Outcomes & Benefits
Eliminated IndexedDB’s instability and custom sync engine maintenance.
Unified schema and storage in Convex for all client and server state.
Robust optimistic updates and live data subscriptions.
Resumable AI streams via planned streamId support.
Improved signed-out flow using Convex sessions.
Team now free to focus on product features rather than sync orchestration.
Next Steps
Migrate full user base.
Integrate resumable-stream IDs into messages for fault-tolerant AI responses.
Monitor Convex search indexing improvements under high write load.
Celebrate the end of database migrations—at least until the next big feature!
The Windows Start Menu has a deep history that mirrors the evolution of Microsoft's operating systems. Beginning with the command-line MS-DOS interface in 1981 and the basic graphical MS-DOS Executive in Windows 1.0, Microsoft gradually developed more user-friendly navigation systems. Windows 3.1's Program Manager introduced grouped icons for application access, but the major breakthrough came with Windows 95, which debuted the hierarchical Start Menu. Inspired by the Cairo project, this menu featured structured sections like Programs, Documents, and Settings, designed for easy navigation on limited consumer hardware.
Subsequent versions saw both visual and technical advancements: NT4 brought Unicode support and multithreading; XP introduced the iconic two-column layout with pinned and recent apps; Vista added search integration and the Aero glass aesthetic; and Windows 7 refined usability with taskbar pinning. Windows 8's touch-focused Start Screen alienated many users, leading to a partial rollback in 8.1 and a full restoration in Windows 10, which blended traditional menus with live tiles. Windows 11 centered the Start Menu, removing live tiles and focusing on simplicity.
Technically, the Start Menu operates as a shell namespace extension managed by Explorer.exe, using Win32 APIs and COM interfaces. It dynamically enumerates shortcuts and folders via Shell Folder interfaces, rendering content through Windows' menu systems. A personal anecdote from developer Dave Plamer highlights an attempted upgrade to the NT Start Menu's sidebar using programmatic text rendering, which was ultimately abandoned in favor of simpler bitmap graphics due to localization complexities. This story underscores the blend of technical ambition and practical constraints that have shaped the Start Menu's legacy.
windows history, start menu, user interface design, microsoft development, operating systems, windows architecture, software engineering lessons
Tags: AI, application development, history, chatbots, neural networks, Markov models, GPT, large language models, small language models, business automation, agents, speech recognition, API integration.
Timeouts:
In distributed systems, waiting indefinitely leads to resource exhaustion, degraded performance, and cascading failures. Timeouts establish explicit limits on how long your system waits for responses, preventing unnecessary resource consumption (e.g., tied-up threads, blocked connections) and ensuring the system remains responsive under load.
Purpose: Timeouts help maintain system stability, resource efficiency, and predictable performance by immediately freeing resources from stalled or unresponsive requests.
Implementation: Clearly define timeout thresholds aligned with realistic user expectations, network conditions, and system capabilities. Even asynchronous or non-blocking architectures require explicit timeout enforcement to prevent resource saturation.
Challenges: Selecting appropriate timeout durations is complex—timeouts that are too short risk prematurely dropping legitimate operations, while excessively long durations cause resource waste and poor user experience. Dynamically adjusting timeouts based on system conditions adds complexity but improves responsiveness.
Tips:
Regularly monitor and adjust timeout values based on actual system performance metrics.
Clearly document timeout settings and rationale to facilitate maintenance and future adjustments.
Avoid overly aggressive or overly conservative timeouts; aim for a balance informed by real usage patterns.
Retries:
Transient failures in distributed systems are inevitable, but effective retries allow your application to gracefully recover from temporary issues like network glitches or brief service disruptions without manual intervention.
Purpose: Retries improve reliability and user experience by automatically overcoming short-lived errors, reducing downtime, and enhancing system resilience.
Implementation: Implement retries using explicit retry limits to prevent repeated attempts from overwhelming system resources. Employ exponential backoff techniques to progressively delay retries, minimizing retry storms. Introducing jitter (randomized delays) can further reduce the risk of synchronized retries.
Challenges: Differentiating between transient errors (which justify retries) and systemic problems (which do not) can be difficult. Excessive retries can compound problems, causing resource contention, performance degradation, and potential system-wide failures. Retries also introduce latency, potentially affecting user experience.
Tips:
Set clear maximum retry limits to prevent endless retry loops.
Closely monitor retry attempts and outcomes to identify patterns that signal deeper system issues.
Use exponential backoff and jitter to smooth retry load, avoiding spikes and cascades in resource use.
Idempotency:
Safely retrying operations depends heavily on idempotency—the principle that repeating the same operation multiple times yields the exact same outcome without unintended side effects. This is similar to repeatedly pressing an elevator button; multiple presses don't summon additional elevators, they simply confirm your original request.
Purpose: Idempotency guarantees safe and predictable retries, preventing duplicated transactions, unintended state changes, and inconsistent data outcomes.
Implementation Approaches:
Unique Request IDs: Assign each request a unique identifier, allowing the system to recognize and manage duplicate requests effectively.
Request Fingerprinting: Generate unique "fingerprints" (hashes) for requests based on key attributes (user ID, timestamp, request content) to detect and safely handle duplicates. Fingerprints help differentiate legitimate retries from genuinely new operations, mitigating risks of duplication.
Naturally Idempotent Operations: Architect operations to inherently produce identical outcomes upon repeated execution, using methods such as stateless operations or RESTful idempotent verbs (e.g., PUT instead of POST).
Challenges: Achieving true idempotency is complex when operations involve external resources, mutable states, or multiple integrated services. Fingerprinting accurately without false positives is challenging, and maintaining idempotency alongside rate-limiting or throttling mechanisms requires careful system design.
Tips:
Clearly mark operations as idempotent or non-idempotent in API documentation, helping developers and maintainers understand system behaviors.
Combine multiple idempotency strategies (unique IDs and fingerprints) for higher reliability.
Regularly validate and review idempotency mechanisms in real-world production conditions.
Ensure robust logging and tracing to monitor idempotency effectiveness, catching issues early.
I want to show you why multi-version concurrency control outdoes locking in distributed databases. By giving each transaction its own snapshot, we never make readers and writers wait on each other, cutting way down on coordination across replicas. I also rely on carefully synchronized physical clocks to get rid of any need for a central version authority, which increases both scalability and availability. This approach hits the sweet spot of guaranteeing read-after-write consistency while still letting us scale horizontally. I am building on David Reed's groundbreaking 1979 work, which underscores how versions help capture consistent states without heavy synchronization. Sure, we need to manage older versions for ongoing transactions, but that is a fair trade-off for the performance and consistency we gain. All in all, versioning is the right choice if you want a fast, truly distributed database system.
Tags: distributed systems, consensus algorithm, Raft, leader election, log replication, fault tolerance, data consistency, state machine replication, system reliability, interactive visualization
The Raft consensus algorithm ensures distributed systems achieve fault-tolerant data consistency through leader-based log replication and leader election mechanisms.
Raft decomposes consensus into leader election and log replication to simplify understanding.
Leader election occurs when the current leader fails, with nodes voting based on log up-to-dateness.
The leader handles client requests, appending entries to its log and replicating them to followers.
Entries are committed once a majority acknowledges them, ensuring consistency across nodes.
Raft enforces safety properties like election safety, leader append-only, log matching, leader completeness, and state machine safety.
it provides an interactive visualization of the Raft algorithm, making complex distributed system concepts more accessible.
The article presents an optimized C# implementation of the blocked Floyd-Warshall algorithm to solve the all-pairs shortest path problem, leveraging CPU cache, vectorization, and parallel processing for enhanced performance.
Explanation of CPU cache levels (L1, L2, L3) and their impact on algorithm performance
Detailed comparison between standard and blocked Floyd-Warshall algorithms
Implementation of vectorization techniques to process multiple data points simultaneously
Utilization of parallel processing to distribute computations across multiple CPU cores
Experimental results demonstrating significant performance improvements with the optimized approach
This article is important as it provides practical insights into enhancing algorithm efficiency through hardware-aware optimizations, offering valuable guidance for developers aiming to improve computational performance.
The article explores using Jaccard similarity and MinHash techniques to identify approximately duplicate documents efficiently in large datasets.
Jaccard similarity measures the overlap between two sets as the size of their intersection divided by the size of their union.
MinHash approximates Jaccard similarity by hashing document features and comparing the minimum hash values.
Combining multiple MinHash values enables detection of near-duplicate documents with high probability.
This method scales well, making it useful for large-scale text processing tasks.
This article is interesting because it introduces efficient, scalable methods for detecting near-duplicate documents—an essential challenge in managing large text datasets.
Welcome to Learn Yjs — an interactive tutorial series on building realtime collaborative applications using the Yjs CRDT library.
This very page is an example of a realtime collaborative application. Every other cursor in the garden above is a real live person reading the page right now. Click one of the plants to change it for everyone else!
Learn Yjs starts with the basics of Yjs, then covers techniques for handling state in distributed applications. We’ll talk about what a CRDT is, and why you’d want to use one. We’ll get into some of the pitfalls that make collaborative applications difficult and show how you can avoid them. There will be explorable demos and code exercises so you can get a feel for how Yjs really works.
Tags: local-first, data synchronization, resilient sync, CRDT, offline data processing, end-to-end encryption, data exchange format, peer-to-peer communication, data resilience, technology evolution
The article proposes a resilient data synchronization method for local-first applications, enabling offline data processing and secure synchronization using simple, technology-agnostic protocols.
Introduces a continuous log system where each client records changes sequentially, ensuring data consistency.
Separates large binary data (assets) from content changes to optimize synchronization efficiency.
Highlights benefits such as independent data retrieval, immediate detection of missing data, and compatibility with various storage systems, including file systems and online services.
Discusses potential enhancements like data compression, cryptographic methods for rights management, and implementing logical clocks for improved data chronology.
This article is important as it addresses the challenges of data synchronization in local-first applications, offering a robust solution that enhances data resilience and user autonomy.
The article discusses implementing Movable Tree CRDTs in collaborative environments, addressing challenges like node movement conflicts and cycle prevention.
Concurrent operations such as node deletion and movement can lead to conflicts.
Moving the same node under different parents requires careful conflict resolution strategies.
Concurrent movements causing cycles necessitate specific handling to maintain tree integrity.
Understanding these challenges is crucial for developers working on collaborative applications that manage hierarchical data structures, ensuring data consistency and system reliability.
CR-SQLite is a SQLite extension enabling seamless merging of independently modified databases using Conflict-Free Replicated Data Types (CRDTs).
multi-master replication and partition tolerance
offline editing and automatic conflict resolution
real-time collaboration by merging independent edits
Integrates with JavaScript environments, including browser and Node.js
This project is important because it tackles the challenges of syncing distributed databases, making it easier to build collaborative, offline-first apps.
In other words, you can write to your SQLite database while offline. I can write to mine while offline. We can then both come online and merge our databases together, without conflict.
In technical terms: cr-sqlite adds multi-master replication and partition tolerance to SQLite via conflict free replicated data types (CRDTs) and/or causally ordered event logs.
CRDTs are a class of data structures that automatically resolve conflicts in distributed systems, allowing for seamless data synchronization across multiple points without centralized coordination. They're designed for environments where network partitions or latency make constant communication impractical but have since found more generalised use due to their simplicity and elegance.
They're incredibly useful when it comes to developing robust, distributed applications that require real-time collaboration. They enable multiple users to work concurrently on the same dataset, with guarantees of eventual consistency, eliminating the need for complex conflict resolution logic. Does your application need offline support? Good news: you get that for free, too!
The concept was formalised in 2011 when a group of very smart researchers came together and presented a paper on the topic; initially motivated by collaborative editing and mobile computing, but its adoption has spread to numerous other applications in the years that followed.
OK, sold. How do I get started?
The answer, surprisingly, is "very easily". Given its meteoric adoption rate in recent years, some excellent, battle-tested projects have appeared and taken strong hold in the community. Let's take a look at a couple: (...)
The goal of this book is to document commonly-known and lesser-known methods of doing various tasks using only built-in bash features. Using the snippets from this bible can help remove unneeded dependencies from scripts and in most cases make them faster. I came across these tips and discovered a few while developing neofetch, pxltrm and other smaller projects.
The snippets below are linted using shellcheck and tests have been written where applicable. Want to contribute? Read the CONTRIBUTING.md. It outlines how the unit tests work and what is required when adding snippets to the bible.
See something incorrectly described, buggy or outright wrong? Open an issue or send a pull request. If the bible is missing something, open an issue and a solution will be found.
Webcamize allows you to use basically any modern camera as a webcam on Linux—your DSLR, mirrorless, camcorder, point-and-shoot, and even some smartphones/tablets. It also gets many webcams that don't work out of the box on Linux up and running in a flash.
JavaScript was created in 1995 by Brendan Eich at Netscape to make websites more interactive. He built the first version in just ten days. It was first called Mocha, then LiveScript, and finally JavaScript to take advantage of Java’s popularity.
It became a standard language through ECMAScript and expanded beyond browsers. Node.js allowed JavaScript to run on servers, and later Deno was introduced to fix some of Node.js’s issues.
JavaScript, history, Brendan Eich, Netscape, ECMAScript, Node.js, Deno, web development
Tags: ECMAScript, JavaScript, ES4, Programming Languages, Type Systems, Interfaces, Classes, Static Typing, Language Evolution, Web Development
ECMAScript 4 was an ambitious but ultimately abandoned update to JavaScript, introducing features like classes, interfaces, and static typing that were later adopted in ES6 and TypeScript.
ES4 aimed to modernize JavaScript with features such as classes, interfaces, and static typing, but its complexity and backward incompatibility led to its abandonment.
Proposed features included class declarations with access modifiers, interfaces, nominal typing with union types, generics, and new primitive types like byte, int, and decimal.
The like keyword was introduced to allow structural typing, providing flexibility in type checking.
ES4's package system and triple-quoted strings were early attempts at modularity and improved string handling.
Flash ActionScript 3 implemented many ES4 concepts, serving as a practical example of the proposed features.
Understanding ES4's history provides insight into JavaScript's evolution and the challenges of balancing innovation with compatibility in language design.
The SQLite File Format Viewer offers an interactive exploration of SQLite database internals, detailing page structures, B-tree organization, and schema representation.
Page Structure: SQLite databases are divided into fixed-size pages (512 to 65536 bytes), each serving specific roles such as B-tree nodes, freelist entries, or overflow storage.
Database Header: The first 100 bytes of the database file contain critical metadata, including page size, file format versions, and schema information.
Freelist Management: Unused pages are tracked in a freelist, allowing efficient reuse of space without immediate file size reduction.
B-Tree Organization: Tables and indexes are stored using B-tree structures, facilitating efficient data retrieval and storage.
Overflow and Pointer Map Pages: Large records utilize overflow pages, while pointer map pages assist in managing auto-vacuum and incremental vacuum processes.
This tool is valuable for developers and database administrators seeking a deeper understanding of SQLite's storage mechanisms, aiding in optimization and troubleshooting efforts.
Tags: bookmarking, web snapshots, offline access, browser extensions, digital archiving, web preservation, Omnom, GitHub, Firefox, Chrome
Omnom is a tool that enables users to create and manage self-contained snapshots of bookmarked websites for reliable offline access and sharing.
Omnom ensures saved pages remain accessible even if the original content changes or is removed.
The platform offers browser extensions for Firefox and Chrome to facilitate bookmarking and snapshot creation.
A read-only demo is available, with the full project hosted on GitHub.
Users can explore public bookmarks and snapshots through the Omnom interface.
This article is significant as it introduces a solution for preserving web content, addressing challenges related to content volatility and ensuring consistent access to information.
Tags: WebTUI, Typography, HTML Elements, CSS Styling, Headings, Lists, Blockquotes, Inline Elements, Custom Markers, Typography Block
WebTUI – A CSS Library That Brings the Beauty of Terminal UIs to the Browser
Tracking Capitol Hill politicians' trades can provide valuable insights for your investment research — and we offer you a free solution to do just that.
CapitolTrades.com is the industry leading resource for political investor intelligence, and a trusted source for media outlets such as the Wall Street Journal and the New York Times.
Each problem about your system is special. And each problem can be explained through contextual development experiences. Glamorous Toolkit enables you to build such experiences out of micro tools. Thousands of them ... per system. It's called Moldable Development.
This service lets you create answer files (typically named unattend.xml or autounattend.xml) to perform unattended installations of both Windows 10 and Windows 11, including 24H2. Answer files generated by this service are primarily intended to be used with Windows Setup run from Windows PE to perform clean (rather than upgrade) installations.
A man has managed to power his home for eight years with a system using more than 1,000 recycled laptop batteries. This ingenious project, based on the use of electronic waste, has proven to be an environmentally friendly and economical solution, without the need to even replace batteries over the years.
This system also uses solar panels, which were the origin of his renewable energy project that he started a long time ago and which has been enough for him to live during this time.
I finally built a Raspberry Pi project my wife loves: an e-ink train and weather tracker! If you want to build one yourself, the Github & instructions are here.
Tags: TypeScript, Japanese Grammar, Type-Level Programming, Language Learning, Domain-Specific Language, Compiler Verification, Educational Tool, AI-Assisted Learning, Grammar Verification, Open Source
Typed Japanese is a TypeScript library that models Japanese grammar rules at the type level, enabling the construction and verification of grammatically correct Japanese sentences within TypeScript's type system.
By creating a domain-specific language (DSL) based on Japanese grammar, it allows developers to express and validate Japanese sentences using TypeScript's compiler. The project also explores the potential for AI-assisted language learning by providing structured formats for grammar analysis, which can be verified through TypeScript's type checker to improve correctness.
This innovative approach bridges programming and linguistics, offering a unique tool for both developers and language learners to understand and apply Japanese grammar rules programmatically.
Every month or so, a new blog article declaring the near demise of CSV in favor of some "obviously superior" format (parquet, newline-delimited JSON, MessagePack records etc.) find its ways to the reader's eyes. Sadly those articles often offer a very narrow and biased comparison and often fail to understand what makes CSV a seemingly unkillable staple of data serialization.
It is therefore my intention, through this article, to write a love letter to this data format, often criticized for the wrong reasons, even more so when it is somehow deemed "cool" to hate on it. My point is not, far from it, to say that CSV is a silver bullet but rather to shine a light on some of the format's sometimes overlooked strengths.
CSV is dead simple
The specification of CSV holds in its title: "comma separated values". Okay, it's a lie, but still, the specification holds in a tweet and can be explained to anybody in seconds: commas separate values, new lines separate rows. Now quote values containing commas and line breaks, double your quotes, and that's it. This is so simple you might even invent it yourself without knowing it already exists while learning how to program.
Of course it does not mean you should not use a dedicated CSV parser/writer because you will mess something up.
CSV is a collective idea
No one owns CSV. It has no real specification (yes, I know about the controversial ex-post RFC 4180), just a set of rules everyone kinda agrees to respect implicitly. It is, and will forever remain, an open and free collective idea.
eli represents the culmination of more than 15 years of designing and implementing embedded Lisp interpreters in various languages.
It all began with a craving an embedded Lisp for personal projects, but evolved into one of the deepest rabbit holes I've had the pleasure of falling into.
Visual explanations of core machine learning concepts
Machine Learning University (MLU) is an education initiative from Amazon designed to teach machine learning theory and practical application.
As part of that goal, MLU-Explain exists to teach important machine learning concepts through visual essays in a fun, informative, and accessible manner.
Peer-to-peer file transfers in your browser
Cooked up by Alex Kern & Neeraj Baid while eating Sliver @ UC Berkeley.
Using WebRTC, FilePizza eliminates the initial upload step required by other web-based file sharing services. Because data is never stored in an intermediary server, the transfer is fast, private, and secure.
A hosted instance of FilePizza is available at file.pizza.
My friend and I spent three years turning old Lenovo ThinkPad 11e Chromebooks, which were considered junk, into a fully functional video wall. We repurposed the displays from 10 Chromebooks, synchronized video playback using a custom web app called c-sync, and tackled countless hardware and software challenges along the way. The project involved removing firmware restrictions, installing Linux, and using tools like coreboot to make the laptops boot directly to a web page displaying synchronized video segments.
#troubleshooting, #problem-solving, #mindset, #learning
I see troubleshooting as the one skill that never gets outdated. It’s about finding the cause of a problem in any system by stepping back, understanding how things flow, and comparing what should happen with what actually does. I start by checking that I’m working on the right part of the system and then form a clear idea of the issue before diving in.
I use a method that involves testing parts of the system one by one, gathering as much real-time data as possible, and cutting through noise. I form hypotheses, rule out common failure points, and test my ideas by isolating or disconnecting subsystems. This approach helps me avoid wasted effort and speeds up finding the true problem, even when things seem tangled.
I also believe that the best fixes come from learning from each mistake. I write down what I discover, rely on practical testing, and keep my work simple. By respecting the system and knowing when to ask for help or replace only what’s necessary, I turn challenges into opportunities to get better at troubleshooting every time.
Developers are taught early on to eliminate code duplication, but this piece argues that premature abstraction is often a bigger danger. Abstracting too early — before understanding how requirements evolve — can lead to bloated, unmanageable code that's harder to change than the original duplication. The post uses a real-world scenario involving bonus calculations to show how well-meaning abstractions become convoluted as requirements change gradually over time. Each small, isolated addition to a shared function seems harmless, but the end result is a mess of parameters and conditionals no one wants to touch.
The author advocates for deferring abstraction until true patterns emerge, emphasizing that superficial similarities often mask fundamentally different needs. Instead of rushing to DRY out code at the first sign of repetition, developers should wait until they have enough insight into what varies and what remains constant. The takeaway: duplication can be an honest, maintainable choice until a meaningful, stable abstraction naturally reveals itself.
software design, programming principles, DRY, abstraction, code maintenance, real-world development
People often say you should live so your future self won’t have regrets on their deathbed. But the article argues this is flawed thinking. The version of you on your deathbed is not living a full life anymore and can't see the whole picture clearly. That self is focused on recent memories, feels differently about risks, and doesn’t have to deal with long-term consequences.
We also misunderstand our past selves, thinking we know why we made certain choices. But those decisions made sense back then, even if they don't match who we are now. It's better to focus on what makes life good today—like meaningful work, good relationships, and purpose—rather than chasing an imagined regret-free future.
Visualizes and compares fixed window, sliding window, and token bucket rate-limiting algorithms, analyzing their pros, cons, and real-world applications to guide choosing the right strategy.
Fixed window resets counters each interval; simple and predictable but allows bursts at window edges and has timezone issues.
Sliding window refills per request for smoother traffic distribution; efficient approximations remove heavy timestamp storage while balancing control and performance.
Token bucket refills tokens at a constant rate, supporting bursts and enforcing average rates; flexible yet harder to communicate limits.
Implementation tips: use persistent stores (e.g., Redis), fail open on datastore errors, choose sensible keys (user ID, IP), and expose HTTP 429 with x-ratelimit headers.
This comparative review clarifies how each algorithm manages traffic, aiding developers in selecting and implementing effective throttling mechanisms.
Martin Sustrik explains how bureaucracies often create environments where responsibility becomes untraceable. These “accountability sinks” occur when rigid systems take precedence over individual judgment, making it nearly impossible to determine who made a decision or why. One example is the destruction of a shipment of squirrels at Schiphol Airport in 1999, where strict adherence to policy overrode common sense, and no one could be held directly responsible.
Sustrik warns that such systems can suppress initiative and slow down meaningful action. Still, he notes that not all formal structures are flawed — the problem arises when they prevent people from acting with ownership. Good systems should balance structure with personal responsibility, allowing people to act while still being accountable for their choices.
...Holocaust researchers keep stressing one point: The large-scale genocide was possible only by turning the popular hatred, that would otherwise discharge in few pogroms, into a formalized administrative process.
For example, separating the Jews from the rest of the population and concentrating them at one place was a crucial step on the way to the extermination.
In Bulgaria, Jews weren't gathered in ghettos or local "labor camps", but rather sent out to rural areas to help at farms. Once they were dispersed throughout the country there was no way to proceed with the subsequent steps, such as loading them on trains and sending them to the concentration camps...
Observability 2.0 challenges the traditional three pillars approach by unifying metrics, logs, and traces into a single, context-rich data model called wide events. Instead of pre-aggregating metrics or parsing logs after the fact, this model treats raw, high-cardinality event data as the source of truth—capturing full system context upfront and allowing dynamic, retrospective computation of metrics and traces. This shift addresses key pain points of observability 1.0: data silos, redundant storage, loss of granularity, and the slow feedback loop of static instrumentation.
GreptimeDB is built explicitly for this new paradigm. It ingests wide events directly, supports real-time queries, materialized views, and triggers for alerts, and scales elastically using disaggregated storage and columnar formats. Crucially, it remains backward-compatible with existing tools like Grafana and PromQL while enabling ad-hoc, high-dimensional analysis without the complexity of traditional pre-aggregation pipelines. This design turns observability from a fragmented stack into a unified system for both real-time monitoring and deep analytics.
Tags: observability, wide events, high cardinality, high dimensionality, context-rich logging, distributed tracing, OpenTelemetry, debugging unknown unknowns, structured logging, application monitoring
Wide events are context-rich, high-dimensional logs emitted per service request, enabling deep observability and effective debugging of unforeseen issues beyond the capabilities of traditional logs and metrics.
Wide events capture comprehensive data per request, including user details, request metadata, database queries, cache operations, and headers, all linked by a unique request ID.
They facilitate correlation of events across services, aiding in identifying root causes of issues that traditional logs and metrics might miss.
Unlike traditional observability tools, wide events allow for ad-hoc querying across any dimension without pre-aggregation, enhancing flexibility in data analysis.
Implementing wide events can be achieved through custom logging or by leveraging distributed tracing frameworks like OpenTelemetry, which standardize context propagation and span creation.
Effective tooling for wide events should support fast, flexible querying, raw data access, and affordability, ensuring comprehensive observability without excessive costs.
Wide events complement rather than replace traditional metrics, offering deeper insights into application behavior, especially for complex or unexpected issues.
As an example, this commonly occurs when implementing a feature to let users delete something. The easy way is to just delete the row from the database, and maybe that's all that the current UI design call for. In this situation, regardless of the requested feature set, as engineers we should maintain good data standards and store:
who deleted it
how they deleted it (with what permission)
when
why (surrounding context, if possible)
In general, these are some useful fields to store on almost any table:
created_at
updated_at
deleted_at (soft deletes)
created_by etc
permission used during CRUD
This practice will pay off with just a single instance of your boss popping into a meeting and going "wait do we know why that thing was deleted, the customer is worried...".
Applications of Zero One Many. If the requirements go from saying “we need to be able to store an address for each user”, to “we need to be able to store two addresses for each user”, 9 times out of 10 you should go straight to “we can store many addresses for each user”
Versioning. This can apply to protocols, APIs, file formats etc.
Logging. Especially for after-the-fact debugging, and in non-deterministic or hard to reproduce situations, where it is often too late to add it after you become aware of a problem.
Strong engineers must take positions in technical discussions, even with partial confidence, to guide teams effectively and prevent poor decisions.
Remaining non-committal can lead to less-informed individuals making critical decisions, potentially resulting in suboptimal outcomes.
Fear of being wrong often drives engineers to avoid commitment, but this behavior can be perceived as cowardice and may burden others with decision-making responsibilities.
Managers prefer engineers who provide decisive input; excessive caveats can frustrate leadership and shift decision-making burdens upward.
While making incorrect decisions occasionally is acceptable, consistently avoiding commitment can damage credibility and trust.
In dysfunctional environments where estimates are penalized unfairly, reluctance to commit is understandable and not criticized.
This article underscores the importance of decisive leadership in engineering roles, highlighting how taking informed stances fosters trust and drives effective team outcomes.
Companies often neglect fixing longstanding software bugs due to bureaucratic hurdles and shifting priorities.
Bugs not tied to immediate business objectives are deprioritized as "tech debt" and added to the backlog.
High staff turnover leads to loss of institutional knowledge, causing unresolved issues to become relics of the past.
Fear of unintended consequences in legacy systems deters developers from implementing even simple fixes, as "the risk of breaking something far outweighs the reward of fixing a non-critical bug."
Financial incentives focus on new features over user experience improvements, as companies "optimize for metrics that show up on quarterly earnings calls, not for goodwill or user experience."
This article highlights the systemic challenges within large organizations that hinder effective software maintenance, emphasizing that the issue lies in "the system that treats user experience as an afterthought."
The article provides a comprehensive overview of continuous probability concepts, contrasting them with discrete probability, and explores foundational topics essential for understanding probabilistic models.
Introduces random variables, distinguishing between discrete (countable outcomes) and continuous (uncountable outcomes) variables
Explains the difference between probability mass functions (PMFs) and probability density functions (PDFs)
Discusses cumulative distribution functions (CDFs) and their relation to PDFs
Covers joint and marginal distributions, and the concept of dependence
Defines expectation, variance, and covariance with mathematical clarity
Introduces the Dirac delta function for modeling point probabilities in continuous distributions
This article is valuable for building a strong foundation in probability theory, especially for advanced applications in statistics and data science.
A comprehensive guide demystifying equity compensation, providing essential insights into stock options, RSUs, and their tax implications for employees and employers in private U.S. companies.
Explains various equity types: restricted stock, stock options (ISOs and NSOs), and RSUs, detailing their structures and differences
Discusses vesting schedules, including cliffs and acceleration clauses, and their impact on ownership and taxation
Highlights tax considerations, such as the 83(b) election, AMT, and timing of exercises, emphasizing potential financial consequences
Addresses the significance of fair market value (FMV) and 409A valuations in determining equity worth and tax liabilities
Provides guidance on evaluating equity offers, understanding dilution, and making informed decisions during fundraising events
Emphasizes the importance of seeking professional advice and understanding legal documents to avoid costly mistakes
This guide is crucial for anyone involved in startup equity, offering clarity on complex topics and aiding in making informed financial and career decisions.
Equity compensation is the practice of granting partial ownership in a company in exchange for work. In its ideal form, equity compensation aligns the interests of individual employees with the goals of the company they work for, which can yield dramatic results in team building, innovation, and longevity of employment. Each of these contributes to the creation of value—for a company, for its users and customers, and for the individuals who work to make it a success.
Using OpenAI’s o3 model, the author discovered CVE-2025-37899, a previously unknown use-after-free vulnerability in the Linux kernel’s SMB implementation, specifically in the ksmbd logoff handler. This bug arises when concurrent threads access a shared sess->user structure: one thread frees it during session logoff without proper synchronization, while another may still access it, leading to memory corruption or a denial of service. Remarkably, this finding emerged not from advanced agentic frameworks, but through straightforward API use, highlighting o3’s emergent capability in reasoning about complex concurrency issues in kernel code.
As part of evaluating o3, the author benchmarked it against another known use-after-free bug in the Kerberos authentication path (CVE-2025-37778). While o3 found this bug in 8 out of 100 runs (compared to Claude Sonnet 3.7's 3/100), it also surfaced the novel CVE-2025-37899 when analyzing all SMB command handlers together. This discovery suggests LLMs like o3 are beginning to deliver meaningful, non-trivial insights in real-world vulnerability research and could significantly augment expert workflows despite current false positive rates.
What is also interesting:
If you’re interested, the code to be analysed is here as a single file, created with the files-to-prompt tool.
The final decision is what prompt to use. You can find the system prompt and the other information I provided to the LLM in the .prompt files in this Github repository.
To run the query I then use the llm tool (github) like:
# Svelte Documentation for LLMs > Svelte is a UI framework that uses a compiler to let you write breathtakingly concise components that do minimal work in the browser, using languages you already know — HTML, CSS and JavaScript. ## Documentation Sets - [Abridged documentation](https://svelte.dev/llms-medium.txt): A shorter version of the Svelte and SvelteKit documentation, with examples and non-essential content removed - [Compressed documentation](https://svelte.dev/llms-small.txt): A minimal version of the Svelte and SvelteKit documentation, with many examples and non-essential content removed - [Complete documentation](https://svelte.dev/llms-full.txt): The complete Svelte and SvelteKit documentation including all examples and additional content ## Individual Package Documentation - [Svelte documentation](https://svelte.dev/docs/svelte/llms.txt): This is the developer documentation for Svelte. - [SvelteKit documentation](https://svelte.dev/docs/kit/llms.txt): This is the developer documentation for SvelteKit. - [the Svelte CLI documentation](https://svelte.dev/docs/cli/llms.txt): This is the developer documentation for the Svelte CLI. ## Notes - The abridged and compressed documentation excludes legacy compatibility notes, detailed examples, and supplementary information - The complete documentation includes all content from the official documentation - Package-specific documentation files contain only the content relevant to that package - The content is automatically generated from the same source as the official documentation
The study revealed that AI chatbots actually created new job tasks for 8.4 percent of workers, including some who did not use the tools themselves, offsetting potential time savings. For example, many teachers now spend time detecting whether students use ChatGPT for homework, while other workers review AI output quality or attempt to craft effective prompts.
I made my AI think harder by making it argue with itself repeatedly. It works stupidly well
CoRT enhances AI performance by enabling recursive self-evaluation and selection among generated responses.
CoRT (Chain of Recursive Thoughts) prompts AI models to iteratively generate multiple responses, evaluate them, and select the most suitable one.
The process involves the AI determining the number of "thinking rounds" needed, generating three alternative responses per round, evaluating all responses, and selecting the best one.
This method was tested with Mistral 3.1 24B, resulting in significant improvements in programming tasks.
The repository includes a web UI for user interaction and is licensed under MIT, encouraging open-source collaboration.
Tags: AI, software design, system prompts, user prompts, agent builders, automation, AI-native applications, email assistants, generative AI, prompt engineering, product design, LLM agents, user customization, productivity tools, software paradigms, AI integration, old world thinking, AI Slop, horseless carriages, agent tools, security models, prompt injection, user experience, task automation, personalization
I noticed something interesting the other day: I enjoy using AI to build software more than I enjoy using most AI applications--software built with AI.
When I use AI to build software I feel like I can create almost anything I can imagine very quickly. AI feels like a power tool. It's a lot of fun.
Many AI apps don't feel like that. Their AI features feel tacked-on and useless, even counter-productive.
Most AI features in today’s apps feel ineffective because they’re built on outdated assumptions about how software should work. Instead of rethinking design from the ground up, many teams just bolt AI onto traditional interfaces, leading to frustrating experiences like Gmail’s draft-writing assistant that produces stiff, formal emails no one would actually send. The problem isn’t that the AI models aren’t capable — it’s that the apps constrain them with one-size-fits-all instructions hidden from users.
A better approach is to let users define how these AI agents behave by writing and editing their own “System Prompts” — reusable instructions that teach the model to act in the user’s voice and style. This flips the traditional developer-user relationship on its head: instead of relying on fixed software behavior set by developers, users directly shape how their tools work. The essay argues that the most powerful AI products won’t be fixed agents but agent builders — platforms that help users easily create and maintain agents that automate the work they don’t want to do.
LLM powered coding tools are not replacements for developers but powerful exoskeletons that shift focus from mechanical typing to strategic vision: they shrink weeks of implementation into minutes while making clear that defining business intent and rigorous architectural oversight have never mattered more. In my view seasoned engineers who treat AI as a collaborative partner (delegating boilerplate patterns while personally steering novel or high stakes components) will outperform both solo humans and stand alone AI by harnessing combined strategic judgment and computational horsepower. This centaur style collaboration proves that tomorrow’s top developers will distinguish themselves not by typing speed but by architectural thinking, pattern recognition and the confidence to scrap and rewrite code whenever required.
AI-generated code, while efficient, must be critically evaluated to prevent the accumulation of technical debt and ensure maintainable, high-quality software.
"Vibe coding," which involves using AI to generate code based on minimal prompts, can lead to fragile and unmaintainable software if not properly managed
Neglecting thorough testing and review of AI-generated code increases the risk of introducing bugs and security vulnerabilities
Developers should not rely solely on AI outputs; instead, they must apply their expertise to validate and refine the code
Proper documentation and understanding of AI-generated code are essential to facilitate future maintenance and scalability
This article is important as it underscores the necessity of maintaining professional standards in software development, even when leveraging advanced AI tools, to ensure the delivery of reliable and sustainable software solutions.
Tags: Claude Code, agentic coding, best practices, CLAUDE.md, prompt engineering, context management, tool configuration, iterative workflows, AI coding assistants, Anthropic
Claude Code is a flexible command-line tool designed for agentic coding, offering customizable workflows and deep integration with project-specific contexts.
Utilize CLAUDE.md files to provide Claude with essential project information, such as common commands, code style guidelines, and testing instructions
Strategically place CLAUDE.md files in directories to ensure relevant context is automatically included during sessions
Regularly refine CLAUDE.md content to enhance instruction adherence, employing emphasis techniques like "IMPORTANT" or "YOU MUST" for critical guidelines
Leverage the '#' command to dynamically update CLAUDE.md files during development, facilitating real-time documentation
Configure Claude's tool access to align with project requirements, ensuring safe and efficient operations
Incorporate planning steps before code generation by instructing Claude to outline its approach, allowing for review and adjustments
Use the Escape key to interrupt Claude's processes, preserving context and enabling redirection or modification of tasks
This article is significant as it provides practical strategies for optimizing the use of Claude Code, enhancing productivity and collaboration in software development environments.
Turns Codebase into Easy Tutorial
Ever stared at a new codebase written by others feeling completely lost? This project analyzes GitHub repositories and creates beginner-friendly tutorials explaining exactly how the code works - all powered by AI! Our intelligent system automatically breaks down complex codebases into digestible explanations
Geoffrey Litt developed a personal AI assistant, "Stevens," using a single SQLite table and cron jobs to manage daily tasks and communications.
Stevens compiles daily briefs—including calendar events, weather forecasts, mail notifications, and reminders—sent via Telegram
The system operates on Val.town, utilizing its capabilities for storage, scheduling, and communication
A single SQLite table, termed the "notebook," stores all relevant data entries, both dated and undated
Data is ingested through various importers: Google Calendar API, weather API, OCR-processed USPS mail, and user inputs via Telegram or email
The Claude API generates the daily brief, incorporating relevant entries from the notebook
The architecture is designed for easy extensibility, allowing additional data sources to be integrated seamlessly
This article illustrates how a minimalist approach can yield a functional and customizable AI assistant, emphasizing the potential of combining simple tools with thoughtful design.
Tags: AI progress, AI benchmarks, AI applications, AI limitations, AI industry, AI startups, AI evaluation, AI generalization, AI model performance
Recent AI model advancements appear impressive in benchmarks but show limited practical improvement in real-world applications.
Newer AI models (like GPT-4) often do not outperform older ones (like GPT-3.5) in startup use-cases.
Benchmark improvements may reflect training on benchmarks rather than genuine generalization.
Suspicion that OpenAI might train directly on benchmark datasets, leading to overfitting.
Models seem to do better at pretending to know things, not actually knowing them better.
Economic productivity and value-add from newer models are not clearly increasing.
The field may be overhyping progress based on synthetic or cherry-picked metrics.
There's growing concern over whether current AI evaluation tools are meaningful for real-world deployment.
GPT-4 performance in many tasks is mostly identical to GPT-3.5 in business settings.
Many claims about major leaps forward are contradicted by practical user experience.
This article is important as it challenges dominant narratives about AI progress and raises critical questions about how we measure and interpret advancement in the field.
Type-in programs from the original 101 BASIC Computer Games, in their original DEC and Dartmouth dialects. No, this is not the same as BASIC Computer Games.
Nice, the command pw.exe chead "Ace of Aces (1986)(U.S.ch8"
Will create C header file, like:
0x00,0x6c,0xc6,0xc6,0xee,0xc6,0xc6,0x00,// A 0x00,0xdc,0xc6,0xfc,0xc6,0xc6,0xfc,0x00,// B 0x00,0x6c,0xc6,0xc0,0xc0,0xc6,0x6c,0x00,// C 0x00,0xdc,0xc6,0xc2,0xc2,0xc6,0xdc,0x00,// D 0x00,0xde,0xc0,0xfc,0xc0,0xc0,0xde,0x00,// E 0x00,0xde,0xc0,0xfc,0xc0,0xc0,0xc0,0x00,// F 0x00,0x6c,0xc6,0xc0,0xce,0xc6,0x6c,0x00,// G 0x00,0xc6,0xc6,0xde,0xc6,0xc6,0xc6,0x00,// H 0x00,0x7e,0x18,0x18,0x18,0x18,0x7e,0x00,// I 0x00,0x06,0x06,0x06,0xc6,0xc6,0x6c,0x00,// J 0x00,0xcc,0xd8,0xf0,0xd8,0xcc,0xc6,0x00,// K 0x00,0xc0,0xc0,0xc0,0xc0,0xc0,0xfe,0x00,// L 0x00,0xc2,0x66,0x98,0xc2,0xc6,0xc6,0x00,// M 0x00,0xc6,0x66,0x96,0xca,0xc4,0xc2,0x00,// N 0x00,0x28,0xc6,0xc6,0xc6,0xc6,0x28,0x00,// O 0x00,0xec,0xc6,0xc6,0xec,0xc0,0xc0,0x00,// P 0x00,0x6c,0xc6,0xc6,0xd6,0xca,0x6c,0x04,// Q 0x00,0xec,0xc6,0xc6,0xec,0xcc,0xc6,0x00,// R
Blue95 is a modern and lightweight desktop experience that is reminiscent of a bygone era of computing. Based on Fedora Atomic Xfce with the Chicago95 theme.
A curious quirk of TypeScript’s type system is that it is Turing-complete which has led some developers to implement apps entirely in the type system. One such developer has spent eighteen months producing 177 terabytes of types to get 1993’s Doom running with them. Ridiculous and amazing in equal measure, he ▶️ explains the project in this widely lauded 7-minute video.
Code review often feels like a minefield, sparking friction and conflict. But there’s a better way. Instead of rigid comments through software, engage in real-time, face-to-face discussions. This human touch helps diffuse tension and builds trust. Imagine a dynamic duo: one writes code while the other offers instant feedback, cutting down misunderstandings.
When reviewing textually, be mindful. Don’t nitpick style. Instead, frame comments to add value. Questions and suggestions work better than criticisms. Highlight what’s right, too; positive reinforcement matters. If you’re feeling hurt by feedback, remember that it’s often well-intentioned. Moving past ego, and embracing constructive dialogue, leads to superior code and stronger relationships.
Mastering this art isn’t just about writing better code; it’s about being the teammate you’d want to work with. Understanding people and relationships is key. With kindness, respect, and genuine collaboration, you can transform code review from a dreaded chore into a meaningful, productive experience.
A good way to think about code review is as a process of adding value to existing code. So any comment you plan to make had better do exactly that. Here are a few ways to phrase and frame the different kinds of reactions you may have when reviewing someone else’s code:
Not my style. Everyone has their own style: their particular favourite way of naming things, arranging things, and expressing them syntactically. If you didn’t write this code, it won’t be in your style, but that’s okay. You don’t need to comment about that; changing the code to match your style wouldn’t add value to it. Just leave it be.
Don’t understand what this does. If you’re not sure what the code actually says, that’s your problem. If you don’t know what a particular piece of language syntax means, or what a certain function does, look it up. The author is trying to get their work done, not teach you how to program.
Don’t understand why it does that. On the other hand, if you can’t work out why the code says what it says, you can ask a question: “I’m not quite clear what the intent of this is. Is there something I’m not seeing?” Usually there is, so ask for clarification rather than flagging it as “wrong”.
Could be better. If the code is basically okay, but you think there’s a better way to write it that’s not just a style issue, turn your suggestion into a question. “Would it be clearer to write…? Do you think X is a more logical name for…? Would it be faster to re-use this variable, or doesn’t that matter here?”
Something to consider. Sometimes you have an idea that might be helpful, but you’re not sure. Maybe the author already thought of that idea and rejected it, or maybe they just didn’t think of it. But your comment could easily be interpreted as criticism, so make it tentative and gentle: “It occurred to me that it might be a slight improvement to use a sync.Pool here, but maybe that’s just overkill. What do you think?”
Don’t think this is right. If it seems to you like the code is incorrect, or shouldn’t be there, or there’s some code missing that should be there, again, make it a question, not a rebuke. “Wouldn’t we normally want to check this error? Is there some reason why it’s not necessary here?” If you’re wrong, you’ve left yourself a graceful way to retreat. If you’re right, you’ve tactfully made a point without making an enemy.
Missed something out. The code is fine as far as it goes, but there are cases the author hasn’t considered, or some important issues they’re overlooking. Use the “yes, and…” technique: “This looks great for the normal case, but I wonder what would happen if this input were really large, for example? Would it be a good idea to…?”
This is definitely wrong. The author has just made a slip, or there’s something you know that they don’t know. This is your opportunity to enlighten them, with all due kindness and humility. Don’t just rattle off what’s wrong; take the time to phrase your response carefully, gracefully. Again, use questions and suggestions. “It looks like we log the error here, but continue anyway. Is it really safe to do that, if the result is nil? What do you think about returning the error here instead?”
Many workers seem bad at their jobs not because of personal incompetence, but because their roles are poorly designed and embedded in dysfunctional systems.
Poorly structured environments and unclear expectations hinder job performance.
Mismanagement often exacerbates inefficiencies across organizations.
Systemic organizational flaws can demoralize and disengage employees.
"Are people bad at their jobs—or are their jobs bad to begin with?"
"If everyone seems bad at their job, maybe it’s the job that’s broken."
"We blame individuals for structural problems because blaming the system feels too big, too overwhelming, too immovable."
"It is easier to think someone is lazy than to examine how they’ve been set up to fail."
Managers are paid to drive results with some support. They have experience in the function, can take responsibility, but are still learning the job and will have questions and need support. They can execute the tactical plan for a project but typically can’t make it.
Directors are paid to drive results with little or no supervision (“set and forget”). Directors know how to do the job. They can make a project’s tactical plan in their sleep. They can work across the organization to get it done. I love strong directors. They get shit done.
VPs are paid to make the plan. Say you run marketing. Your job is to understand the company’s business situation, make a plan to address it, build consensus to get approval of that plan, and then go execute it.
Tech Industry, Burnout, Unionizing, Job Security, Agile Methodology, Work-Life Balance, Ethics in Tech, Hacker Ethos, Innovation, Gig Economy, Mindfulness, Non-Compete Clauses, Tech Layoffs, Workers Rights, Alphabet Workers Union, Organizing, Surveillance Tech, Data Mining, AI Ethics, Industry Culture.
We’re living in a world where billion dollar tech companies expect us to live and breathe code, demanding 80 hour weeks under the guise of "passion." And what do we get in return? Burnout, anxiety, and the constant threat of layoffs. It’s time to face facts: this industry is not your friend. It’s a machine, and unless we start organizing, it’s going to keep grinding us down. It’s time to talk about unionizing tech jobs.
On-call responsibilities in big tech have grown into a culture of reactive firefighting, where engineers babysit unreliable systems instead of improving their robustness. In startups, limited resources create similar roles, but with a focus on direct problem-solving. Big companies, however, normalize and entrench on-call practices, rewarding band-aid solutions over systemic fixes, leading to declining software quality.
The incentives in big tech favor quick feature delivery and measurable outcomes over long-term maintenance and ownership. Engineers cycle through projects without fully addressing technical debt, while management prioritizes metrics that showcase immediate progress. This creates a loop of short-term fixes and neglect of robust design, resulting in on-call roles that never end.
AI has potential to reshape on-call by automating mundane tasks like finding related issues or allocating responsibilities. Properly integrated, AI tools can help engineers focus on meaningful work by reducing repetitive efforts. However, a cultural shift is necessary to make on-call the exception, not the norm, fostering better engineering practices and happier teams.
Being more strategic as a software engineer isn't about long-term planning or big decisions; it's about creating a framework that guides daily decision-making. Strategy defines a path forward and clarifies trade-offs—what to prioritize and what to avoid—to align with core objectives. For example, improving system reliability might involve focusing on end-to-end automated tests rather than slowing down releases. A good strategy shapes decisions and narrows options, providing clarity on what actions to take.
Three useful frameworks can help in thinking strategically. Rumelt's Kernel breaks strategy into diagnosis (identifying the core challenge), guiding policy (deciding the approach), and coherent actions (steps aligning with the policy). The "Playing to Win" framework asks five critical questions about aspirations, focus areas, unique approaches, necessary capabilities, and management systems. This helps clarify priorities and connect technical work to business goals. McKinsey's Three Horizons framework helps balance immediate needs with long-term goals, encouraging work across short-term optimization, emerging opportunities, and future capabilities.
Being strategic means creating systems for how decisions are made, not just making decisions. These frameworks help diagnose problems, define winning strategies, and balance immediate and future needs. However, even great strategies require solid execution and tactical follow-through to succeed.
I stay close to the code without being the main coder. I make sure I understand our codebase, dig into code reviews, and even pair program when it benefits the team. My focus is on guiding and supporting others rather than writing every line myself.
I handle tasks that only I can manage—like setting strategy, hiring, and building our culture—while letting experts lead in writing code. I jump into coding when it helps solve problems or steer the team in the right direction.
I reserve dedicated time to work hands-on with the code. This balance keeps my skills sharp and reinforces my leadership, ensuring that I contribute meaningfully while empowering the team to produce great work.
Get everything in writing—follow up verbal conversations with email.
Wait until necessary to disclose personal situations.
Delay major announcements until protections are in place.
Keep job searches private—coworkers aren’t your confidants.
Know your rights and consult an attorney if needed.
Remember: Your vulnerability is their opportunity.
Your career survival depends on maintaining clear boundaries.
Follow for more corporate tactics exposed by a former insider.
Disclaimer: This information is for educational purposes only and does not replace professional legal advice. It does not establish an attorney-client relationship.
Here, we're going to cover the history, functionality, and performance of non-volatile storage devices over the history of computing, all using fun and interactive visual elements. This blog is written in celebration of our latest product release: PlanetScale Metal. Metal uses locally attached NVMe drives to run your cloud database, as opposed to the slower and less consistent network-attached storage used by most cloud database providers. This results in a blazing fast queries, low latency, and unlimited IOPS. Check out the docs to learn more.
Build beautiful cross-platform applications using Go
Wails v2 turns what used to be tedious and painful into a delightfully simple process. Use the tools you know to create cross-platform desktop apps. Everyone wins!
Tauri 2.0 is a framework designed for creating small, fast, and secure cross-platform applications. It supports a wide range of operating systems, including Linux, macOS, Windows, Android, and iOS, enabling developers to build from a single codebase. Tauri is frontend-independent, allowing integration with any web stack, and uses inter-process communication to seamlessly combine JavaScript for the frontend and Rust for application logic. It prioritizes security, optimizes for minimal application size (as small as 600KB), and leverages Rust's performance and safety features to provide next-generation app solutions.
Tags: LLMs, business logic, application development, decision-making, performance, debugging, testing, state management, security, AI limitations
Large Language Models (LLMs) should serve as interfaces, not handle core application logic or decision-making.
LLMs are inefficient at tasks requiring precision, like maintaining state or performing calculations.
Debugging LLMs is difficult due to opaque reasoning.
Testing outputs lacks the rigor of traditional unit tests.
LLMs are prone to mathematical errors and can't reliably generate randomness.
Versioning and audit trails are harder with LLM-driven logic.
Monitoring becomes complex with prompt-based execution.
Managing state via language inputs is fragile.
Using LLMs increases costs and dependency on API limits.
Prompt-based control blurs traditional security models.
Best use: converting user input to structured API calls and back.
This article is a critical read for developers navigating LLM integration, offering a grounded approach to maintaining application integrity and performance.
A CLI utility and Python library for interacting with Large Language Models, both via remote APIs and models that can be installed and run on your own machine.
Tags: recommendation systems, search systems, large language models, LLM integration, multimodal content, data generation, training paradigms, unified frameworks, Semantic IDs, M3CSR
Integrating large language models (LLMs) and multimodal content enhances recommendation and search systems, tackling challenges like cold-start issues and long-tail item recommendations.
Semantic IDs: YouTube replaces traditional hash-based IDs with content-derived Semantic IDs using a transformer-based video encoder and Residual Quantization Variational AutoEncoder (RQ-VAE), improving performance, especially for new or rarely interacted items.
M3CSR Framework: Kuaishou generates multimodal content embeddings (text, image, audio), clusters them with K-means into trainable category IDs, turning static embeddings into dynamic, behavior-aligned representations.
LLM-Assisted Data Generation: LLMs generate synthetic data to augment training datasets, increasing robustness and performance.
Scaling Laws and Transfer Learning: Applying these principles enables better generalization and task adaptability across recommendation/search models.
Unified Architectures: Combining search and recommendation systems into shared frameworks simplifies development and boosts consistency in user experience.
This article is important for its clear breakdown of how cutting-edge techniques are reshaping recommendation and search systems, offering actionable insights for future system design.
Generative AI tools are increasingly integrated into software development, especially agentic tools that not only suggest code but act on it. While promising, these tools require experienced developers to supervise and guide them.
Agentic tools often fail in three key ways:
Time-to-commit missteps: AI produces incorrect or non-compiling code, misdiagnoses issues, or hallucinates plausible but wrong solutions.
Iteration-level disruptions: The AI misinterprets requirements, implements features too broadly, or ignores team workflows, hindering collaboration.
Long-term maintainability issues: Generated code lacks reuse, introduces duplication, and accumulates technical debt due to poor architectural awareness.
These tools lack contextual understanding—of architecture, naming, intent—which developers must still provide. Prompting helps, but it doesn't replace engineering judgment.
Agentic AI isn't a replacement for developers but a tool that, like a junior teammate, needs oversight. Its value depends on the skill of the person wielding it.
Onyx (formerly Danswer) is the AI platform connected to your company's docs, apps, and people. Onyx provides a feature rich Chat interface and plugs into any LLM of your choice. Keep knowledge and access controls sync-ed across over 40 connectors like Google Drive, Slack, Confluence, Salesforce, etc. Create custom AI agents with unique prompts, knowledge, and actions that the agents can take. Onyx can be deployed securely anywhere and for any scale - on a laptop, on-premise, or to cloud.
OpenAdapt: AI-First Process Automation with Large Multimodal Models (LMMs).
OpenAdapt is the open source software adapter between Large Multimodal Models (LMMs) and traditional desktop and web Graphical User Interfaces (GUIs).
Enormous volumes of mental labor are wasted on repetitive GUI workflows.
Foundation Models (e.g. GPT-4, ACT-1) are powerful automation tools.
OpenAdapt connects Foundation Models to GUIs
A Windows desktop AI assistant built in Python. Assistant (without tools) is ~1000 lines of python code, with super simple chat UI inspired by the original AI, SmarterChild. Uses Windows COM automation to interface with Microsoft Office (Word, Excel), Images, and your file system. Perfect for Windows users looking to explore AI-powered desktop automation.
superglue is a self-healing open source data connector. You can deploy it as a proxy between you and any complex / legacy APIs and always get the data that you want in the format you expect.
Here's how it works: You define your desired data schema and provide basic instructions about an API endpoint (like "get all issues from jira"). Superglue then does the following:
Automatically generates the API configuration by analyzing API docs.
Handles pagination, authentication, and error retries.
Transforms response data into the exact schema you want using JSONata expressions.
Validates that all data coming through follows that schema, and fixes transformations when they break.
This is a collection of (mostly) pen-and-paper exercises in machine learning. The exercises are on the following topics: linear algebra, optimisation, directed graphical models, undirected graphical models, expressive power of graphical models, factor graphs and message passing, inference for hidden Markov models, model-based learning (including ICA and unnormalised models), sampling and Monte-Carlo integration, and variational inference.
Deep learning isn’t as unique or mysterious as it’s often made out to be. Many phenomena like overparametrization, double descent, and benign overfitting—features commonly associated with neural networks—can be replicated in simpler models and explained with long-standing frameworks like PAC-Bayes. Instead of restricting the hypothesis space to prevent overfitting, it’s more effective to allow flexibility with a soft preference for simpler, data-aligned solutions.
Soft inductive biases are a powerful concept. They guide learning by favoring specific solutions without imposing strict limitations on the model’s expressiveness. For example, high-order polynomials with regularization or vision transformers' soft translation preferences outperform rigidly constrained models, bridging the gap between flexibility and precision. These biases drive better results across diverse data complexities and sizes.
Generalization in deep learning can be understood with ideas like compressibility, which ties a model's performance to its ability to represent data simply. PAC-Bayes bounds reveal that even overparametrized models generalize effectively by balancing training accuracy with solution simplicity. Deep learning’s real distinction lies in its representation learning capabilities and phenomena like mode connectivity, making it versatile and universal in problem-solving.
Cosine similarity measures how similar two vectors are by examining the angle between them rather than their sizes. It focuses on direction, making it useful for comparing high-dimensional data like text embeddings. A score of 1 indicates vectors point in the same direction, 0 means they are perpendicular, and -1 shows they point in opposite directions. This technique is widely applied in AI for tasks like semantic search, recommendations, and content matching.
A Bloom filter is a data structure that helps quickly determine if an element exists in a large dataset. It doesn’t store the actual data but instead uses a bit array and multiple hash functions to create a lightweight "fingerprint" for each item. This makes it both memory-efficient and fast, ideal for cases where speed and minimal storage are essential. However, it sacrifices perfect accuracy—while it can always confirm when an item isn’t in a dataset, it may produce false positives when indicating that an item is present.
THINKING LIKE AN ARCHITECT: ESSENTIAL LESSONS FROM GREGOR HOHPE
See the Whole Picture
Gregor Hohpe urges us to step back from the minutiae and view the entire system. By focusing on the interactions and evolution of components, we can make design choices that serve long-term business goals rather than just immediate fixes.
Embrace Key Architectural Principles
Modularity: Divide complex systems into smaller, independent parts for easier development and maintenance.
Abstraction: Simplify complexity by hiding the details that aren’t crucial to the current discussion.
Separation of Concerns: Keep different responsibilities distinct to reduce unwanted dependencies and improve clarity.
Balance Trade-Offs and Make Informed Decisions
Every design choice involves trade-offs between performance, cost, complexity, and flexibility. Hohpe reminds us that there’s rarely a perfect solution—only the best balance for the situation at hand. Thoughtful evaluation prevents technical debt and supports future growth.
Communicate Clearly and Document Thoughtfully
Great architecture emerges from collaboration. Transparent documentation of decisions, assumptions, and rationales keeps technical teams and business stakeholders aligned, paving the way for smooth implementation and ongoing improvement.
Learn from Real-World Examples
Through practical case studies, Hohpe illustrates how sound architectural thinking addresses real challenges. These examples demonstrate that adaptability and creative problem-solving are crucial when systems evolve or requirements change unexpectedly.
Lead with Vision and Foster Continuous Improvement
An effective architect does more than design systems—they act as a bridge between technology and business. By encouraging a culture of continuous learning and collaboration, architects inspire teams to innovate and adapt in a rapidly changing environment.
Final Thoughts
"Thinking Like an Architect" is a call to adopt a strategic, big-picture approach. Whether you’re designing systems or part of a technical team, the key is to:
Look beyond immediate challenges and consider future impacts.
Communicate openly to ensure all stakeholders are on the same page.
Continuously adapt and refine your approach to stay ahead of evolving requirements.
These insights empower you to build systems that not only meet today’s demands but also thrive in the future.
Core Tenet:
C++ is engineered to deliver maximum performance. Every language feature is designed so that, when not used, it incurs zero overhead; when used, it should incur no more cost than a hand‐crafted implementation.
Trade-off with Safety:
Safety features, like automatic checks or initializations, are often omitted or left to the programmer. For instance, leaving variables uninitialized (instead of zeroing them by default) saves time when the variable is immediately overwritten at runtime.
2. Move Semantics & Moved-from Objects
Move Semantics Explained:
Move semantics were introduced in C++11 to avoid the cost of unnecessary copying. Instead of copying data, resources are transferred (or “moved”) from one object to another.
What Are Moved-from Objects?
After a move operation, the source object is left in a “moved-from” state. Kalb stresses that:
Valid but Minimal: A moved-from object remains valid only enough to be destroyed or assigned a new value.
No Other Guarantees:
Its internal state is undefined for any use other than assignment or destruction.
“If you need to know its state after moving, you’re misusing move semantics.”
Practical Examples:
Vectors and Unique Pointers:
The talk details how vector move operations typically zero out the internal pointer and size—ensuring no overhead is added for range checking in common operations.
Move Constructors & Assignment:
Kalb explains that the move constructor should transfer resource ownership efficiently, without extra checks that might degrade performance.
3. Embracing Undefined Behavior for Performance
Performance by Omission:
C++ intentionally leaves certain behaviors undefined (for example, reading from an uninitialized variable or accessing a moved-from object) to avoid extra runtime checks. This “undefined behavior” is a deliberate design choice that:
Maximizes Speed: No extra conditional tests mean faster code in the common case.
Shifts Responsibility: The onus is on the programmer to ensure that only valid operations are performed on objects.
The Zero Overhead Principle:
The language design guarantees that features “when not used” have no overhead. Kalb emphasizes that any additional safety check (like range-checking or state validation in moved-from objects) would hinder performance.
4. Debate Over Standards and Moved-from Object State
Standards Committee’s Note:
There is an ongoing debate regarding how much “life” a moved-from object should retain:
Fully Formed vs. Partially Formed:
The committee’s stance—documented in non-normative notes and echoed by Herb Sutter—suggests that moved-from objects should remain “fully formed” (i.e., callable for any operation without precondition checks).
Kalb’s Perspective:
He argues that this decision encourages logic errors. Instead, a moved-from object should be treated as “suspended”—only eligible for assignment or destruction.
“If you need to query the state of an object that’s been moved from, you’re creating a logic error.”
Real-world Impact:
Implementations (such as those for vector and list) illustrate that ensuring full functionality of moved-from objects can force extra runtime checks, which undermines the zero overhead promise.
Understanding distributed systems means accepting that time is not absolute. Events do not always occur in a clear sequence, and different machines may see different orders of events. Leslie Lamport’s work showed that “happened before” is a partial ordering, not a total one. Logical clocks, like Lamport timestamps, help establish order without relying on unreliable system clocks. This is crucial because networks introduce delays, failures, and inconsistencies that force us to rethink how we model time and causality in software. Networks are not reliable, fast, or secure. The classic "fallacies of distributed computing" highlight common false assumptions, such as expecting zero latency, infinite bandwidth, and trustworthy communication. A system might show different data to different users or lose information due to network partitions. The CAP theorem states that in a distributed system, we can only guarantee two of three properties: consistency, availability, and partition tolerance. If the network fails, we must choose between showing potentially outdated data (availability) or refusing to show anything (consistency). Software slows down hardware. The speed of light is fast, but software introduces inefficiencies, adding delays beyond physical limits. A distributed system has a "refractive index" like glass slowing down light—it distorts time, making responses slower than ideal. Developers should recognize that their programming environments create a misleading illusion of synchrony and locality. Thinking in terms of partial ordering, network partitions, and failure tolerance leads to better system design. Time is an illusion; software makes it worse.
I'm a firm believer that exceptions aren't the enemy—they're powerful signals that something's gone wrong in our code. Over the years, I've learned that effective error handling is all about knowing how and where to use exceptions. Below is a detailed digest of the talk along with practical C#-like code examples that directly correspond to the transcript and are supported by the slides.
Understanding Exception Categories
Fatal Exceptions are errors you can’t recover from (like out-of-memory or stack overflow). Instead of trying to catch these, you should design your code to avoid them. For example, if recursion might lead to a stack overflow, check your recursion depth first:
// Avoid catching fatal exceptions like StackOverflowException. try { RecursiveMethod(); } catch (StackOverflowException) { // You can't reliably recover from a fatal error; let the app crash. Environment.FailFast("Stack overflow occurred."); }
Boneheaded Exceptions indicate a bug (such as a null pointer or index out-of-range error). Validate inputs to prevent these errors instead of masking them:
// Validate input to avoid a boneheaded exception. if (index < 0 || index >= myList.Count) throw new ArgumentOutOfRangeException(nameof(index), "Index is out of range."); var value = myList[index];
Vexing Exceptions are thrown by poorly designed APIs (like FormatException when parsing). Use safe parsing patterns instead:
// Use TryParse to avoid a vexing FormatException. if (!int.TryParse(userInput, out int result)) Console.WriteLine("Input is not a valid number."); else Console.WriteLine("Parsed value: " + result);
Exogenous Exceptions arise from the external environment (for example, missing files or network errors). Catch these at a higher level to log the error or notify the user:
try { string content = File.ReadAllText("data.txt"); Console.WriteLine(content); } catch (FileNotFoundException ex) { Console.WriteLine("File not found: " + ex.Message); // Log the error or provide an alternative action. }
Best Practices in Exception Handling
Don’t Hide Errors by avoiding catch blocks that simply return default values; instead, log the error and rethrow it to preserve the context:
try { ProcessOrder(order); } catch (Exception ex) { Console.WriteLine("Error processing order: " + ex.Message); throw; // Rethrow to preserve the original context. }
Provide Clear, Context-Rich Messages by including detailed error messages that help diagnose issues:
if (user == null) throw new ArgumentNullException(nameof(user), "User object cannot be null when processing an order.");
Assert Your Assumptions using assertions during development to enforce conditions that should always be true:
Debug.Assert(order != null, "Order must not be null at this point in the process.");
Don’t Overuse Catch Blocks; let exceptions bubble up when you don’t have enough context to handle them. This keeps your code cleaner:
public void ProcessData() { ValidateData(data); SaveData(data); // Let exceptions bubble up to a higher-level handler. }
Be Specific with Your Catches by catching only the exceptions you expect. This prevents masking other issues:
try { string data = File.ReadAllText("config.json"); } catch (FileNotFoundException ex) { Console.WriteLine("Configuration file not found: " + ex.Message); }
Retain the Original Stack Trace when rethrowing exceptions by using a simple throw statement, which preserves all the valuable context:
Clean Up Resources by using the "using" statement or a finally block to ensure that resources are disposed of correctly, even if an exception occurs:
using (var connection = new SqlConnection(connectionString)) { connection.Open(); // Execute database operations. } // Or, if not using "using": SqlConnection connection = new SqlConnection(connectionString); try { connection.Open(); // Execute operations. } finally { connection.Dispose(); }
The Philosophy Behind “Throw More, Catch Less”
I advocate for writing fewer catch blocks and allowing exceptions to propagate to a centralized handler. This keeps error handling centralized and improves observability. For example, a method can validate and throw errors without catching them:
public void ProcessOrder(Order order) { if (order == null) throw new ArgumentNullException(nameof(order), "Order cannot be null."); // Process the order... }
In an ASP.NET application, you might use a global exception handler to manage errors consistently:
app.UseExceptionHandler("/Error");
This approach ensures that errors are visible and managed in one place, making systems more robust and easier to debug.
These principles and code examples are directly derived from the transcript and are supported by the slides, ensuring that they reflect the original content without deviation.
Problem: Platform teams rely on heavyweight tools (e.g., Kubernetes, Kafka, Istio), creating high maintenance costs and unplanned work for delivery teams.
Solution: Replace complex tools with lightweight alternatives like Fargate or Kinesis to reduce tech burden.
Technology Anarchy
Problem: Teams have too much autonomy without alignment, leading to inconsistent tech stacks, inefficient processes, and slow collaboration.
Solution: Establish paved roads with clear guidelines, expectations, and business consequences to balance autonomy with alignment.
Ticketing Hell
Problem: Platform teams act as a service desk, requiring tickets for routine tasks, causing bottlenecks, slow progress, and developer frustration.
Solution: Implement self-service workflows to automate common tasks, freeing both platform and delivery teams from excessive manual work.
Platform as a Product Mindset
Problem: Teams treat platform engineering as a project rather than a product, leading to inefficiencies and lack of user focus.
Solution: Apply product management principles, measure internal customer value, and focus on reducing unplanned work to drive adoption and success.
I’ve learned from experience that if you’re going to build a product that truly solves real user needs, you must start by building a working prototype instead of spending months on a design document. In my time at big tech—and even more so in medium and small companies—I’ve seen how design docs can lead teams astray, locking in bad assumptions before you even know what you’re building. I call it "painting a house you haven’t seen yet", because when you plan without having built the thing, you’re just imagining complexities that don’t exist in practice.
When I worked on projects like the Twitch dashboard, our elaborate design for a binary tree layout failed to account for real-world issues like varying aspect ratios across devices. Had we built a proof-of-concept first, we would have discovered these issues early on, saving us months of wasted effort. Instead, the focus on a rigid spec led us to persist with bad decisions and ultimately delay a product that could have been released sooner.
For me, the only sensible approach is to prototype, test, and iterate. Building something tangible exposes hidden complexities and actual user behaviors in ways that a design doc never can. Once you’ve built it and seen how it works in reality, then you can document and refine the design. If you haven’t built it first, don’t plan it—this is the only way to avoid locking in mistakes and wasting valuable engineering time.
With the rise of AI, companies need to rethink their interview processes. Simply asking candidates to complete coding tests isn't enough anymore. Some options include stopping remote interviews, requiring spyware during interviews, or allowing AI use and focusing on how well candidates can prompt and refactor AI outputs. Ultimately, companies may need to adopt a hybrid approach, combining remote and in-person interviews to evaluate both coding skills and AI proficiency. Regardless, the nature of tech interviews is set to change drastically in the coming years.
Johann Hari says in Stolen Focus that rats and pigeons can be manipulated as we want. Just give them food whenever they do what you want them to. And shortly after, they will repeat that over and over again.
This made me think. In times when Instagram and other apps give us likes, hearts, and views on things we post, how much does big tech influence our behavior?
Aren’t they the same as the researcher, feeding us with dopamine to tell us to do what they want? Are they doing the same as the researcher who feeds the rats or pigeons?
This question, and recent improvements and tinkering with my flow as I started working for myself, made me ask how we can control the addiction and the influence and find a better way to slow living.
To understand why key metrics change, Pinterest uses three approaches. The "Slice and Dice" method breaks down metrics into segments based on different dimensions like country and device type, allowing us to identify significant segments. This method helps diagnose issues like video metric regressions by organizing segments into a tree structure.
The "General Similarity" approach looks for other metrics that move similarly, either in the same or opposite direction, using factors like Pearson correlation and Spearman’s rank correlation. This method has helped us discover relationships between performance metrics and content distribution, indicating potential causes for latency.
Lastly, the "Experiment Effects" approach leverages A/B testing to see which experiments impact key metrics. By analyzing the treatment effects and filtering out noisy results, we dynamically identify top experiments affecting metrics. These approaches together help us narrow down root causes for metric movements and guide further investigations.
Quotes:
How we are analyzing the metric segments takes inspiration from the algorithm in Linkedin’s ThirdEye. We organize the different metric segments into a tree structure, ordered by the dimensions we are using to segmentize the metric.
Pearson correlation: measures the strength of the linear relationship between two time-series
Spearman’s rank correlation: measures the strength of the monotonic relationship (not just linear) between two time-series; in some cases, this is more robust than Pearson’s correlation
Euclidean similarity: outputs a similarity measure based on inversing the Euclidean distance between the two (standardized) time-series at each time point
Dynamic time warping: while the above three factors measure similarities between two time-series in time windows of the same length (usually the same time window), this supports comparing metrics from time windows of different lengths based on the distance along the path that the two time-series best align
Creating a calculator app with precise results is challenging because floating point numbers can't represent all numbers accurately. Hans-J. Boehm experimented with various methods like bignums and algebraic equations but had to find a balance between precision and practicality.
Ultimately, Boehm's team realized they only needed to work with numbers expressible through the calculator's operations. They combined rational arithmetic and constructive real numbers, representing numbers as a rational times a real. Using symbolic representations for irrational numbers like π, they achieved accurate results while maintaining usability.
This approach allowed them to develop a calculator app that delivers accurate answers without compromising user experience. Their work highlights the complexity and creativity required to solve seemingly simple problems in software development.
I started my career at Hughes Aircraft in 1972 while working on my Ph.D. at the University of California, Los Angeles (UCLA). After designing airborne computers for four years, I graduated and then taught and did systems research at UC Berkeley for the next 40. Since 2016, I’ve helped Google with hardware that accelerates artificial intelligence (AI).
At the end of my technical talks, I often share my life story and what I’ve learned from my half-century in computing. I recently was encouraged to share my reflections with a wider audience, so I’ve captured them here as 16 people-focused and career-focused life lessons.
People-Focused and Career-Focused Life Lessons from David Patterson.
People-Focused
1. Family first! Don’t sacrifice your family’s happiness on the altar of success.
2. Choose happiness.
3. It’s the people, not the projects, that you value in the long run.
4. The cost of praise is small. The value to others is inestimable.
5. Seek out honest feedback; it might be right.
6. “For better or for worse, benchmarks shape a field.”16
7. “I learned that courage was not the absence of fear, but the triumph over it.”11
8. Beware of those who believe they are the smartest people in the room.
Career-Focused
9. “Most of us spend too much time on what is urgent and not enough time on what is important.”4
10. “Nothing great in the world has ever been accomplished without passion.”5
11. “There are no losers on a winning team, and no winners on a losing team.”
12. Lead by example.
13. “Audentes Fortuna iuvat.” (Fortune favors the bold).
14. Culture matters.
15. It’s not how many projects you start; it’s how many you finish.
People who stress over code style, linting rules, or other minutia remain insane weirdos to me. Focus on more important things.
Code coverage has absolutely nothing to do with code quality (in many cases, it's inversely proportional)
Monoliths remain pretty good
It's very hard to beat decades of RDBMS research and improvements
Micro-services require justification (they've increasingly just become assumed)
Most projects (even inside of AWS!) don't need to "scale" and are damaged by pretending so
93%, maybe 95.2%, of project managers, could disappear tomorrow to either no effect or a net gain in efficiency. (this estimate is up from 4 years ago)
The most common question I got after that post was how do you do that?
I interviewed Evan last week so you can hear the answer in his own words soon (aiming to share that next week). Before that, I wanted to share some thoughts since it’s one of the most important parts of growing your impact. Here’s everything I know about shipping more in less time.
= = =
(Semi-GPT summary) To get more done in less time, you’ve got to nail your core responsibilities so you can free up time for growth. Start by resolving ambiguity. Be fluent in code search to navigate big codebases quickly, know who to ask for help when you’re stuck, and learn to query data yourself instead of waiting on others. These basics will save you hours.
When writing code, smaller, focused diffs are the way to go. They’re faster to write, test, and review, with fewer bugs slipping through. To move even quicker, batch your tests, use feature flags to safely land work in progress, and copy existing test plans to save time in unfamiliar code paths. Make reviews faster by spoon-feeding context to reviewers and preempting feedback before submission. Being a great collaborator builds trust and gets your code reviewed faster.
Flow state is key. Eliminate distractions with noise-canceling headphones, cluster meetings to maximize focus time, and work during hours when interruptions are minimal. Turn off noisy notifications and audit your workflow for inefficiencies. While waiting on builds or tests, knock out quick tasks to keep momentum. Freeing up that extra time lets you tackle growth opportunities and build a career trajectory like Evan’s.
At work the junior engineer sends you some code to review. The code was clearly written in a first draft, and then just iteratively patched until the tests passed, then immediately sent to you to review without any further improvement. They do not care.
The guy on the hiking trail is playing his shitty EDM on his bluetooth speaker, ruining nature for everyone else. He does not care.
The doctor misdiagnoses your illness whose symptoms are in the first paragraph of the trivially googleable wikipedia article. He does not care.
People don't pick up after their dogs. The guy at the gym doesn't re-rack the weights. The lady at the grocery store leaves the cart in the middle of the parking lot. They. Do. Not. Care.
First, we need to understand why senior-to-staff promotions happen in tech companies. They happen for two reasons:
Company leadership (i.e. your skip-level or above) think a particular engineer is valuable and may leave if not promoted to staff.
Company leadership want a particular engineer to lead specific cross-org projects that will run smoother if they’ve got the staff role.
Promotions do not happen because a particular engineer is really technically strong and ready for the next level. They do not happen because an engineer has been mentoring a lot and is ticking the boxes on the engineering ladder description. They are a tool for retaining or for empowering valued engineers. So to be promoted to staff, you must be known and valued by your organization.
When someone suggests, "let's just," it often leads to complications far beyond what anyone anticipates. For example, making something "pluggable" assumes seamless adaptability through future modules or implementations, but true pluggability requires creating at least two working versions upfront, which is rarely feasible. Similarly, adding APIs to transform a product into a "platform" may sound strategic, but APIs demand constant maintenance, compatibility, and user interest—things that are much harder to deliver than imagined.
Other ideas that rarely work include adding layers of abstraction, synchronizing data, or enabling cross-platform functionality. While abstractions can solve problems, premature ones create unused complexity. Synchronization, especially across unstructured data, is fraught with inconsistencies and bugs. Cross-platform efforts often devolve into building something akin to an operating system, which is far more complex than initially envisioned. Even "escape to native" options—allowing frameworks to access underlying platforms—tend to fail because they create conflicts between the framework's state and the native platform's.
Most of these ideas fail not because they are inherently bad but because they oversimplify the problem and ignore the complexities of implementation, maintenance, and real-world usage. Successful engineering requires solving problems with clear first principles, not leaning on patterns that are more prone to failure than success.
The website Neal.fun is a creative space where Neal shares his projects and games. It's a fun and interactive site with various activities and experiments.
A system to organise your life.
Johnny.Decimal is designed to help you find things quickly, with more confidence, and less stress.
You assign a unique ID to everything in your life.
A diagram showing the structure of a Johnny.Decimal number. The number is 15.52 and it explains how the '1' is an area, which groups related categories in sets of 10. The '15' is the category, in this case 'travel'. And '52' is just an ID; they start at 01. The title of this, our 52nd travel thing, is 'Trip to NYC'.
These IDs help you stay organised. They impose constraints that make it harder to get lost. And you create your own index to link everything in your life together.
The system is free to use and the concepts are the same at home, work, or that club you manage.
SSH access to the bed!
What Can They Do with This Access?
Let’s start with the basics:
They can know when you sleep
They can detect when there are 2 people sleeping in the bed instead of 1
They can know when it’s night, and no people are in the bed
Imagine your ex works for Eight Sleep. Or imagine they want to know when you’re not home.
(Of course, they can also change the bed’s temperature, turn on the vibrating feature, turn off your alarm clock, and any of the other normal controls they have power over.)
At first glance, it might not be obvious that this script provides value. Maybe it looks like all we’ve done is make the instructions harder to read. But the value of a do-nothing script is immense:
It’s now much less likely that you’ll lose your place and skip a step. This makes it easier to maintain focus and power through the slog.
Each step of the procedure is now encapsulated in a function, which makes it possible to replace the text in any given step with code that performs the action automatically.
Over time, you’ll develop a library of useful steps, which will make future automation tasks more efficient.
A do-nothing script doesn’t save your team any manual effort. It lowers the activation energy for automating tasks, which allows the team to eliminate toil over time.
Intuitive spreadsheet-like interface that lets users of all technical skill levels view, edit, query, and collaborate on Postgres data directly—self hosted, with native Postgres access control.
Universal Access: AI assistants should be accessible from anywhere on your computer, not just in browsers or specific apps.
Provider Freedom: Users should have the choice between models and model providers (Anthropic, OpenAI, xAI, etc.) and not be locked into a single provider.
Local First: AI is much more useful with access to your data. But that doesn't count for much if you have to upload personal files to an untrusted server first. Onit will always provide options for local processing. No personal data will leave your computer without explicit approval.
Customizability: Onit is your assistant. You should be able to configure it to your liking.
Extensibility: Onit should allow the community to build and share extensions, making it more useful for everyone.
I kindly request that you allow me to finish my thoughts. This will enable a smoother flow of conversation and ensure that all points are thoroughly addressed. Thank you for your understanding.
Why are you so useless?
(This one’s obviously sarcastic, but if you do use it, tag us on social media @corporatereplies 😂; We’re on Instagram and TikTok and we’d love to see the reaction.)
I am observing that your current performance is not meeting the expected standards. Could you please elaborate on the challenges you are facing to assist in finding potential solutions?
Allows for simple usage of ffmpeg via an llm. BASH
You write ffmpeg commands based on the description from the user. You should only respond with a command line command for ffmpeg, never any additional text. All responses should be a single line without any line breaks.
Rant time: You've heard it before, git is powerful, but what good is that power when everything is so damn hard to do? Interactive rebasing requires you to edit a goddamn TODO file in your editor? Are you kidding me? To stage part of a file you need to use a command line program to step through each hunk and if a hunk can't be split down any further but contains code you don't want to stage, you have to edit an arcane patch file by hand? Are you KIDDING me?! Sometimes you get asked to stash your changes when switching branches only to realise that after you switch and unstash that there weren't even any conflicts and it would have been fine to just checkout the branch directly? YOU HAVE GOT TO BE KIDDING ME!
If you're a mere mortal like me and you're tired of hearing how powerful git is when in your daily life it's a powerful pain in your ass, lazygit might be for you.
The goal of font pairing is to select fonts that share an overarching theme yet have a pleasing contrast. Which fonts work together is largely a matter of intuition, but we approach this problem with a neural net. See GitHub for more technical details.
Together with some friends, I decided earlier this year to particpate in the Carbage run 2025 Winter edition. This is a 6-day journey in winter all the way through Sweden to the polar circle, and back down to Helsinki in a group of roughly 400 cars.
One small catch (you might have guessed it from the name): your car has to be “carbage”. In practice, this means it needs to be at least 20 years old, and with a day value of less than €1000.
API Parrot is the tool specifically designed to reverse engineer the HTTP APIs of any website. Making life easier for developers looking to automate, integrate or scrape websites without public APIs.
The next generation of programmers will grow up expecting AI to do the hard parts for them. They won’t know why an algorithm is slow, they won’t be able to debug cryptic race conditions (provided they are familiar with the concept), and they certainly won’t know how to build resilient systems that survive real-world chaos.
The result? We’ll have a whole wave of programmers who are more like AI operators than real engineers. And when companies realize AI isn't magic, being just a bunch of tokenized words in line (prove me wrong on that), they'll scramble to find actual programmers who know what they're doing. Too bad they spent years not hiring them.
In 2024, the field of Large Language Models (LLMs) saw significant advancements. The GPT-4 barrier was broken, with 18 organizations now having models that outperform the original GPT-4. Notably, Google's Gemini 1.5 Pro introduced new capabilities like a 2 million token input context length and video input. Additionally, LLM prices dropped dramatically due to increased competition and efficiency, making these models more accessible.
Multimodal vision became common, with models now handling images, audio, and video. Voice and live camera modes also emerged, allowing real-time interaction with LLMs. Despite these advancements, the concept of "agents"—LLMs acting autonomously—has not yet fully materialized. The environmental impact of LLMs improved due to efficiency gains, but the large-scale infrastructure buildout by tech giants remains a concern.
Overall, 2024 was marked by rapid progress in LLM capabilities, reduced costs, and the rise of multimodal and real-time interaction features. However, challenges like the environmental impact and the practical implementation of autonomous agents still need to be addressed.
This article investigates whether large language models (LLMs) like Claude 3.5 Sonnet or GPT can iteratively improve code when asked to "make it better." Using a Python coding problem as a test, the author demonstrates that LLMs can optimize performance over iterations, improving speed and efficiency. However, vague prompts often lead to overengineering, such as unnecessary "enterprise-level features," without clear benefits. Despite these issues, iterative prompting can yield faster, more efficient code.
With explicit instructions, the LLM delivered substantial improvements, including using tools like Numba for just-in-time compilation and NumPy for vectorization. These optimizations resulted in code that was up to 100x faster than the initial implementation. The LLM also introduced creative techniques like precomputing digit sums and leveraging parallel processing. However, issues like hallucinated logic, subtle bugs, and redundant complexity showed that human oversight is essential to validate and refine the results.
The findings highlight the potential and limitations of using LLMs for coding. While they can provide significant speed-ups and novel ideas, they often miss important optimizations, such as deduplication or statistical shortcuts. The article emphasizes that LLMs are valuable tools for accelerating development when used thoughtfully but require careful guidance and validation from skilled developers to produce effective, reliable results.
Since the beginning of Val Town, our users have been clamouring for the state-of-the-art LLM code generation experience. When we launched our code hosting service in 2022, the state-of-the-art was GitHub Copilot. But soon it was ChatGPT, then Claude Artifacts, and now Bolt, Cursor, and Windsurf. We’ve been trying our best to keep up. Looking back over 2024, our efforts have mostly been a series of fast-follows, copying the innovation of others. Some have been successful, and others false-starts. This article is a historical account of our efforts, giving credit where it is due.
Virtually all experienced scholars know that writing, as historian Lynn Hunt has argued, is “not the transcription of thoughts already consciously present in [the writer’s] mind.” Rather, writing is a process closely tied to thinking. In graduate school, I spent months trying to fit pieces of my dissertation together in my mind and eventually found I could solve the puzzle only through writing. Writing is hard work. It is sometimes frightening. With the easy temptation of AI, many—possibly most—of my students were no longer willing to push through discomfort.
Generative AI is, in some ways, a democratizing tool. Many of my students were non-native speakers of English. Their writing frequently contained grammatical errors. Generative AI is effective at correcting grammar. However, the technology often changes vocabulary and alters meaning even when the only prompt is “fix the grammar.” My students lacked the skills to identify and correct subtle shifts in meaning. I could not convince them of the need for stylistic consistency or the need to develop voices as research writers.
I pointed to weaknesses such as stylistic quirks that I knew to be common to ChatGPT (I noticed a sudden surge of phrases such as “delves into”). That is, I found myself spending more time giving feedback to AI than to my students.
How was this tested? Participants completed decision-making tasks before and after AI use.
Results: AI-assisted users had a higher accuracy rate in complex decision-making.
🚀 Key takeaway: AI is acting as a cognitive amplifier, allowing us to process and retain information more efficiently.
But… it’s not all good news.
The Dark Side: AI is Increasing Stress and Anxiety
While AI improves cognitive performance, the study also found a moderate positive correlation (r = 0.468, p < 0.01) between frequent AI use and increased mental stress.
📌 Evidence from self-reported stress levels:
Participants completed anxiety and stress assessments before and after AI interactions.
Results: Frequent AI users reported higher stress scores after prolonged AI use.
📌 Cognitive overload is real:
AI bombards users with continuous information, leading to mental fatigue.
Example from interviews: Users described feeling "overwhelmed" and "mentally exhausted" after extensive AI interaction.
🤯 Key takeaway: AI might make tasks easier, but it also increases cognitive pressure and emotional strain.
The Hidden Risk: Psychological Dependence on AI
One of the most alarming findings was the development of AI dependency.
📌 Psychological reliance on AI:
Regression analysis confirmed that frequent AI users are more likely to doubt their own judgment.
Standardized Coefficient (Beta) = 0.421, p = 0.000 → A strong predictor of AI-induced dependency.
📌 Real-world impact:
Users who rely on AI for problem-solving report difficulty making decisions without AI assistance.
Example from interviews: Some participants said they "don’t trust their answers without double-checking with AI."
🔍 Key takeaway: AI is replacing independent thinking, reducing cognitive autonomy, and making users second-guess themselves.
5. The Solution: How We Can Use AI Without Losing Ourselves
So, what’s the way forward? The study suggests three key strategies to balance AI’s cognitive benefits with emotional well-being:
✔️ AI should assist, not replace thinking → We must stay in control of our decisions.
✔️ Regulate AI’s role in decision-making → Avoid relying on AI for every task.
✔️ AI should be designed for cognitive balance → Not just efficiency, but emotional well-being too.
🎯 Final Thought: AI has the potential to elevate our intelligence or erode our independence.
The question is: Will we use AI as a tool to enhance our minds—or let it become the master of our decisions?
The future is in our hands.
For the record (gpt-4o):
I've asked GPT summarize the article like a friend researcher would do. The result was bad.
The I've asked to write in a conversation style between two friends... the result was "Me: Bro, this paper is wild. It’s basically saying that using AI all the time makes us smarter… but also kinda messes with our emotions."
"Make the TED-style presentation, where the people share their opinions" -- led to good initial structure with emojis, which I like!
"Add evidence for each point" -- finalized the result, not bad, I wonder if the numbers and conclusions are correct.
A new study published by researchers at Microsoft and Carnegie Mellon University found that the more humans lean on AI tools to complete their tasks, the less critical thinking they do, making it more difficult to call upon the skills when they are needed.
The researchers tapped 319 knowledge workers—a person whose job involves handling data or information—and asked them to self-report details of how they use generative AI tools in the workplace. The participants were asked to report tasks that they were asked to do, how they used AI tools to complete them, how confident they were in the AI’s ability to do the task, their ability to evaluate that output, and how confident they were in their own ability to complete the same task without any AI assistance.



The article is a practical tour of lossless compression, focusing on how common schemes balance three levers: compression ratio, compression speed, and decompression speed. It explains core building blocks like LZ77 and Huffman coding, then dives into DEFLATE as used by gzip, before comparing speed and ratio tradeoffs across Snappy, LZ4, Brotli, and Zstandard. It also highlights implementation details from Go’s DEFLATE, and calls out features like dictionary compression in zstd.

Ruud van Asseldonk’s article The YAML Document from Hell critiques YAML as overly complex and error-prone compared to JSON. Through detailed examples, he shows how YAML’s hidden features, ambiguous syntax, and inconsistent versioning can produce confusing or dangerous outcomes, making it risky for configuration files.


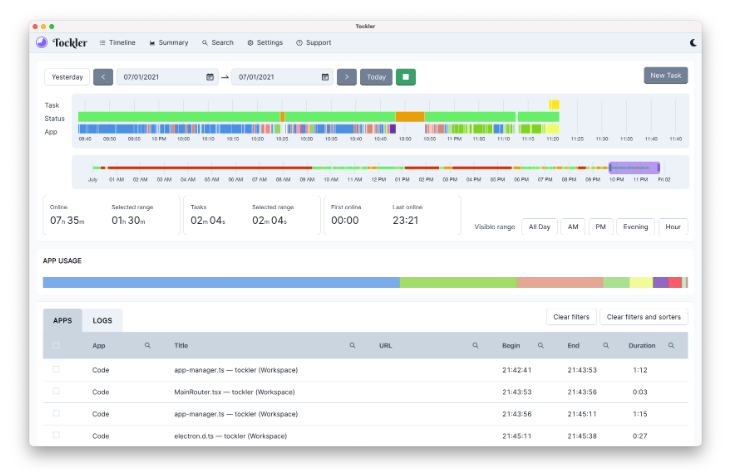
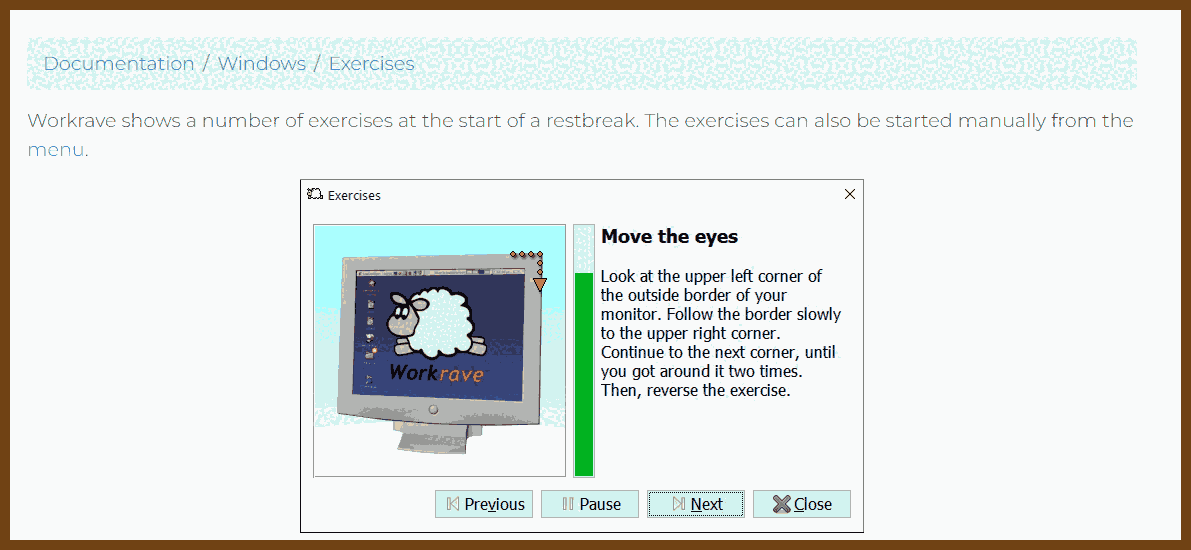


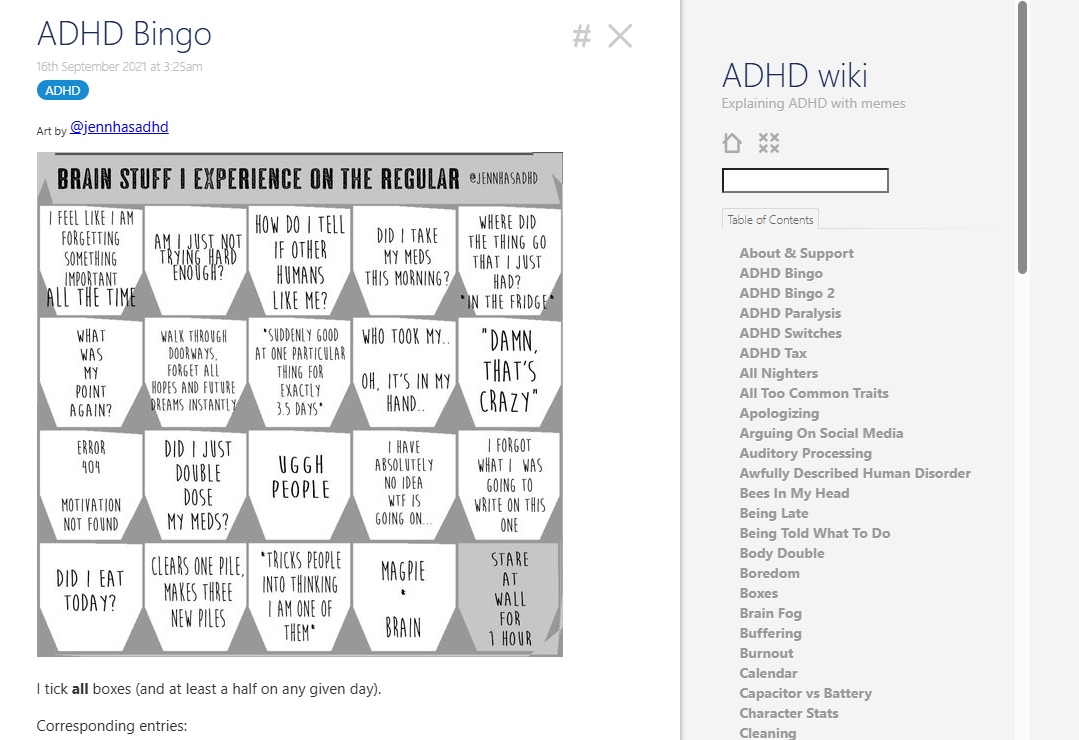
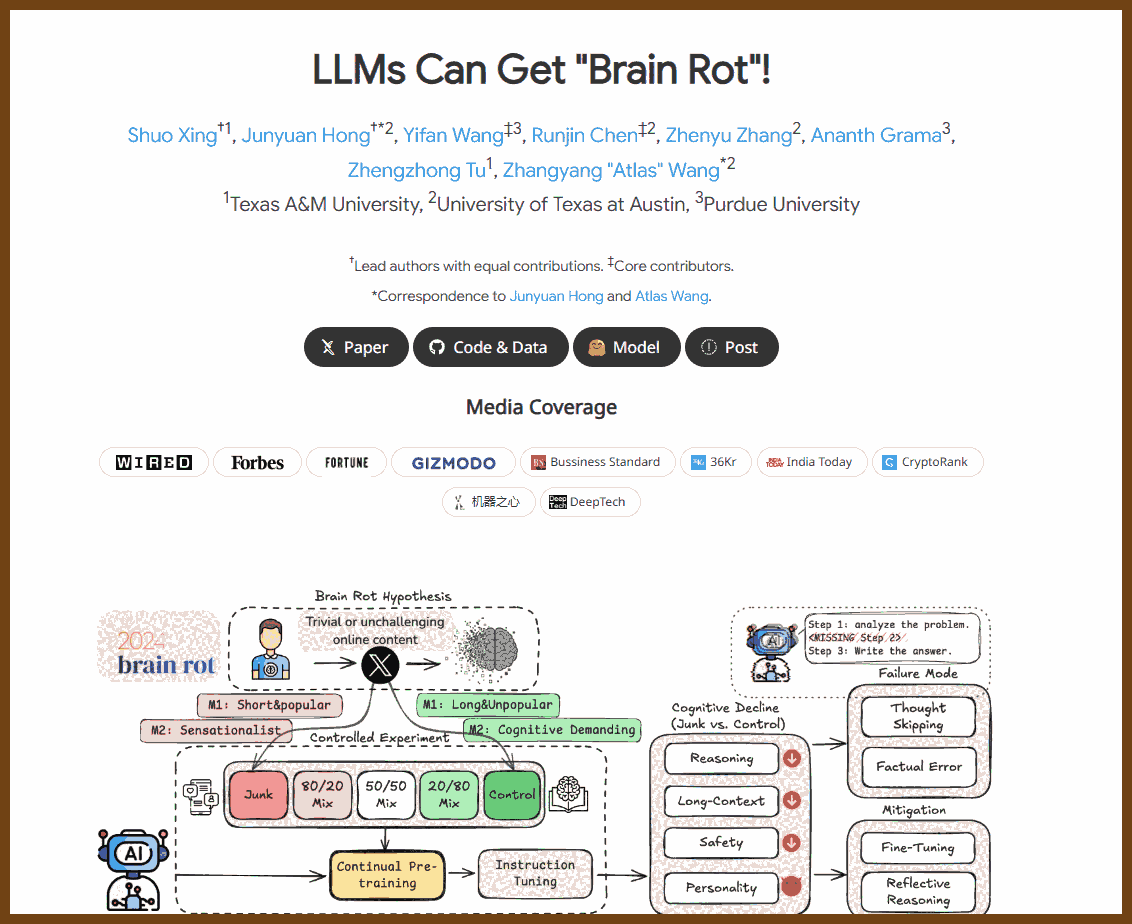

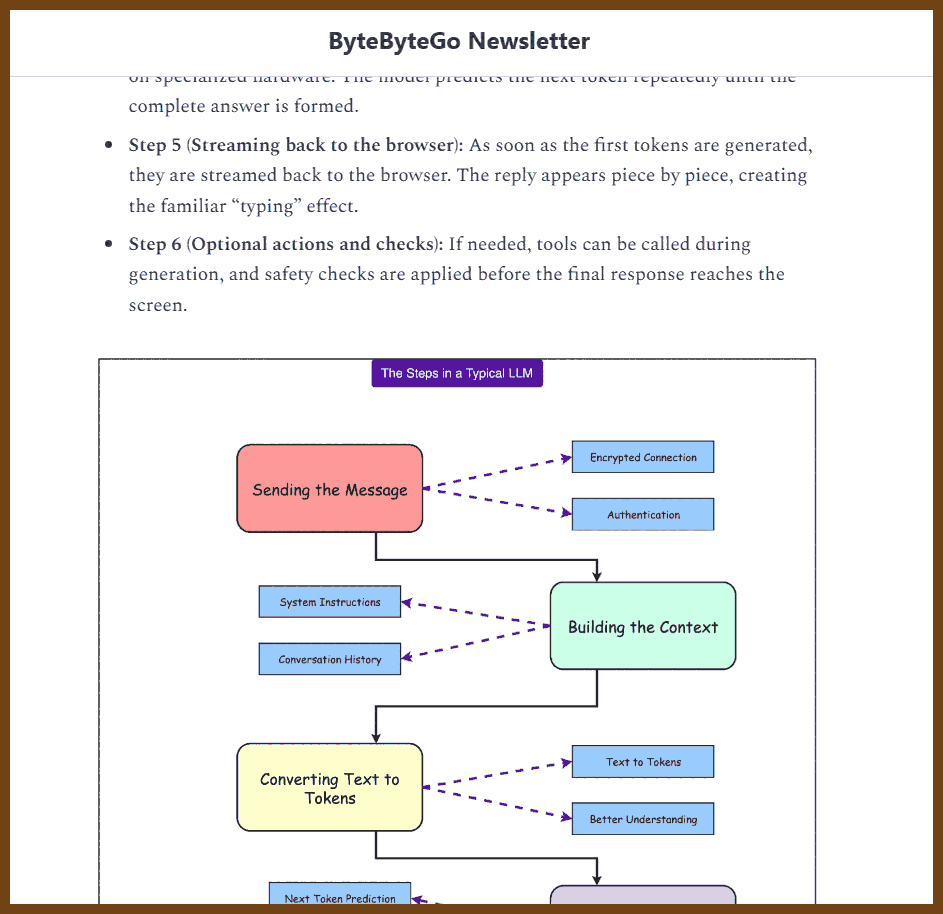
This methodology provides a structured approach for collaborating with AI systems on software development projects. It addresses common issues like code bloat, architectural drift, and context dilution through systematic constraints and validation checkpoints.
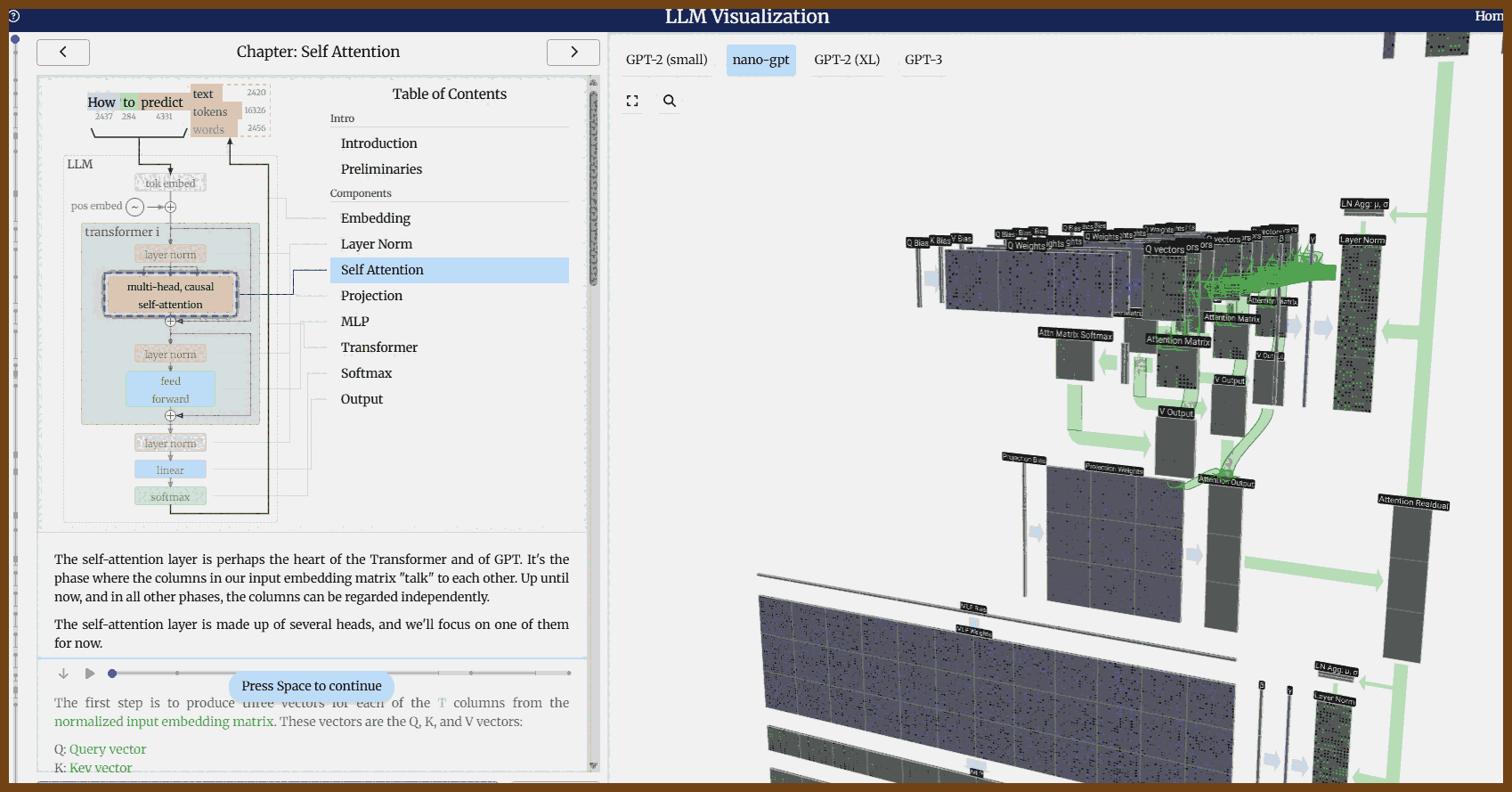

The writeup explains how to make AI coding agents productive in large, messy codebases by treating context as the main engineering surface. The core method is frequent intentional compaction: repeatedly distilling findings, plans, and decisions into short, structured artifacts, keeping the active window lean, using side processes for noisy exploration, and resetting context to avoid drift. The piece sits alongside a YC talk and HumanLayer tools that operationalize these practices for teams.


 Key Takeaways – The Real Bottleneck in Software Development (and How AI Should Actually Help)
Key Takeaways – The Real Bottleneck in Software Development (and How AI Should Actually Help)

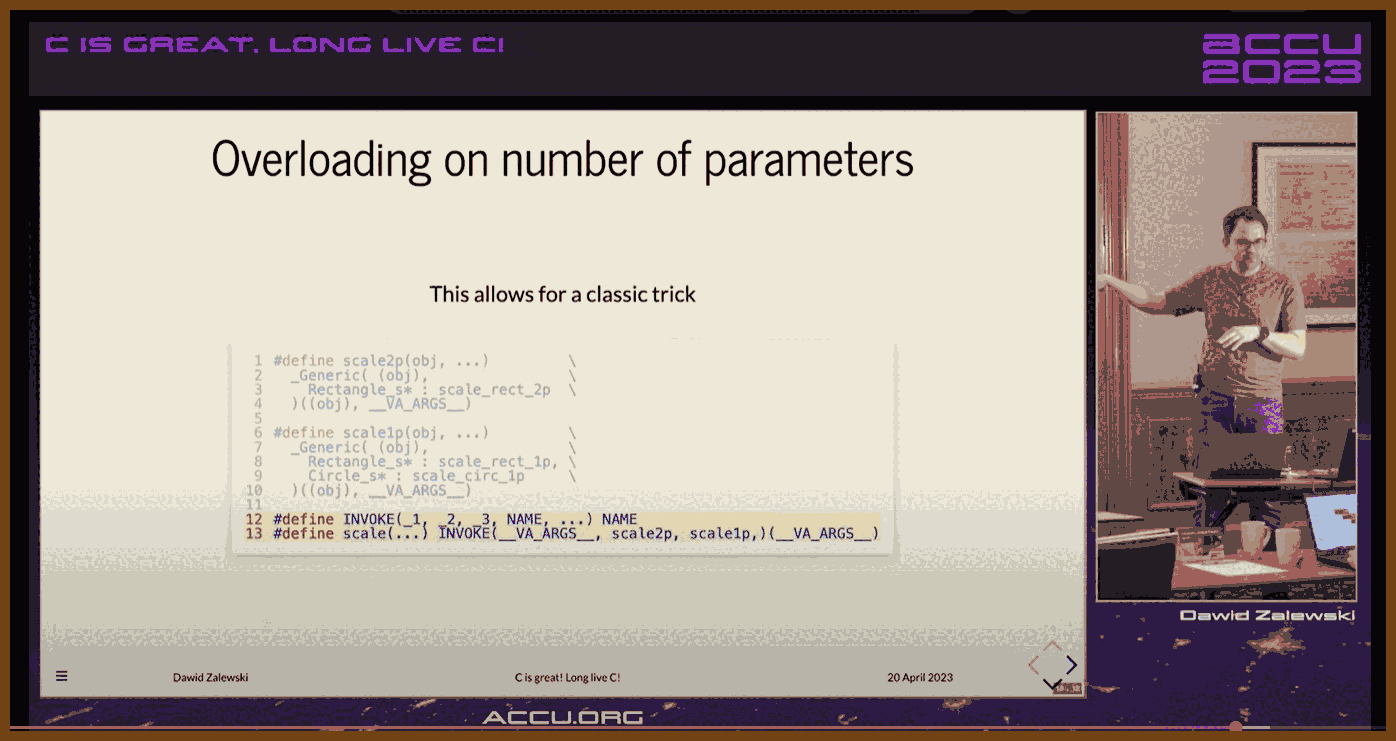
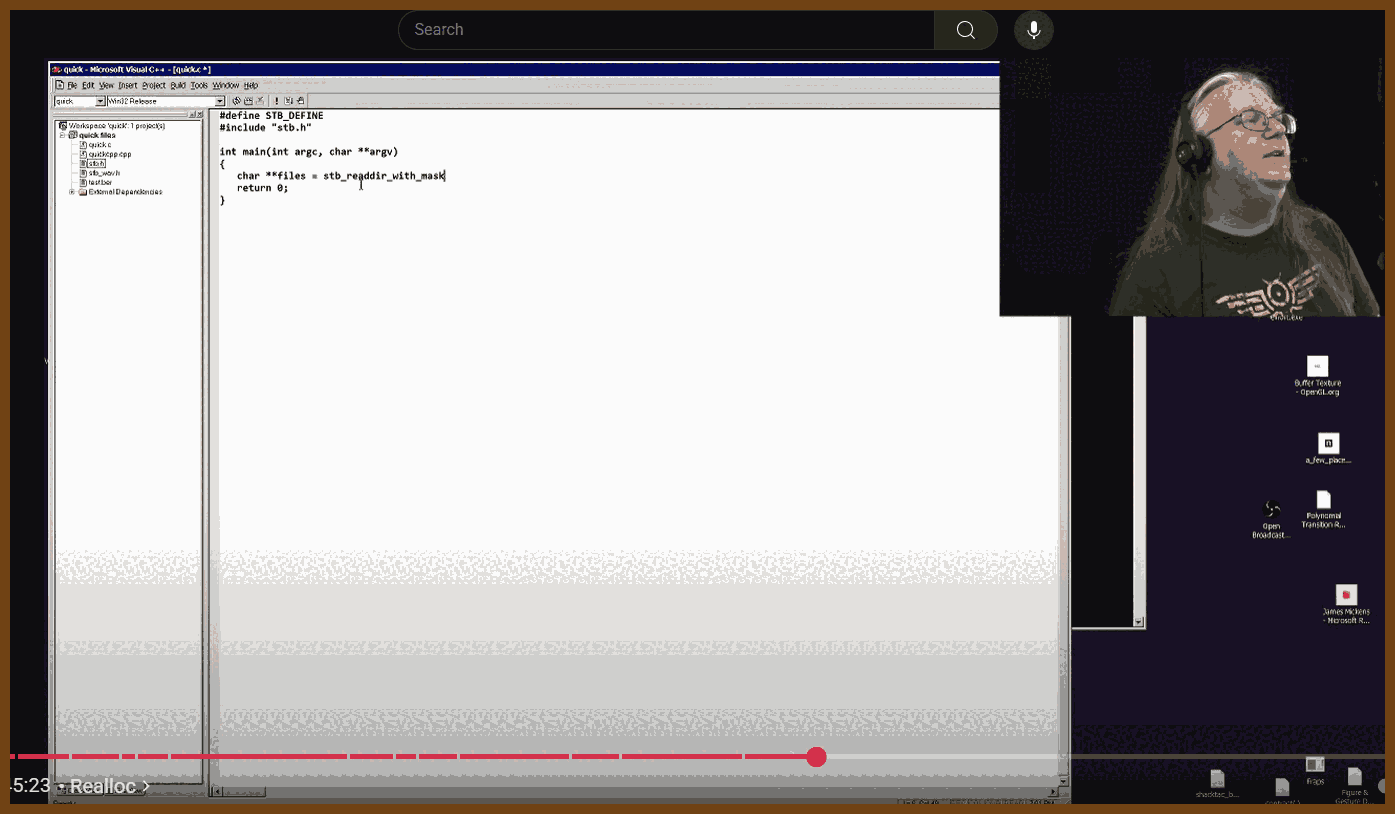 Main point
Main point


 when everything is “an opportunity for growth,” nothing is.
when everything is “an opportunity for growth,” nothing is.
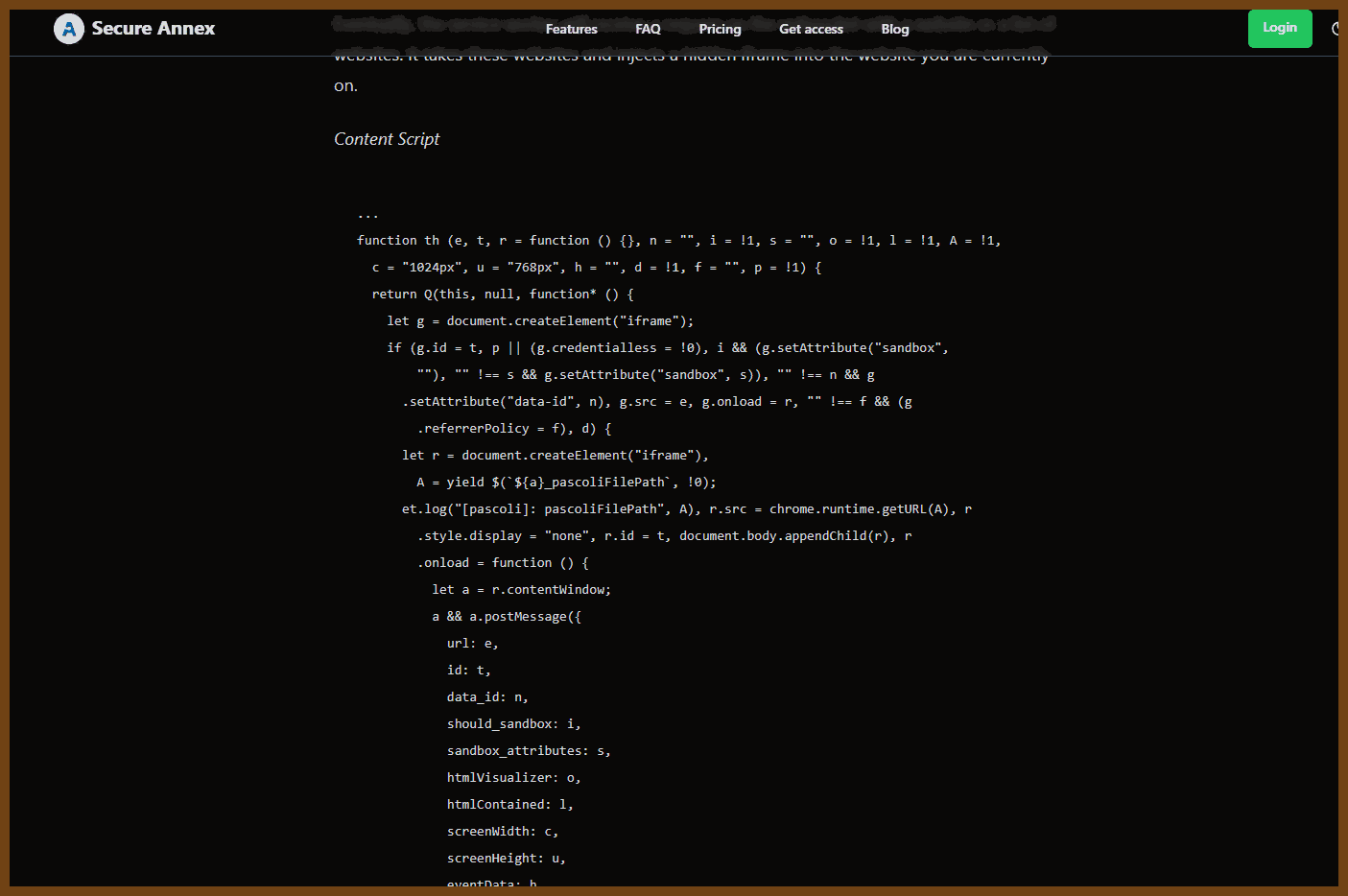




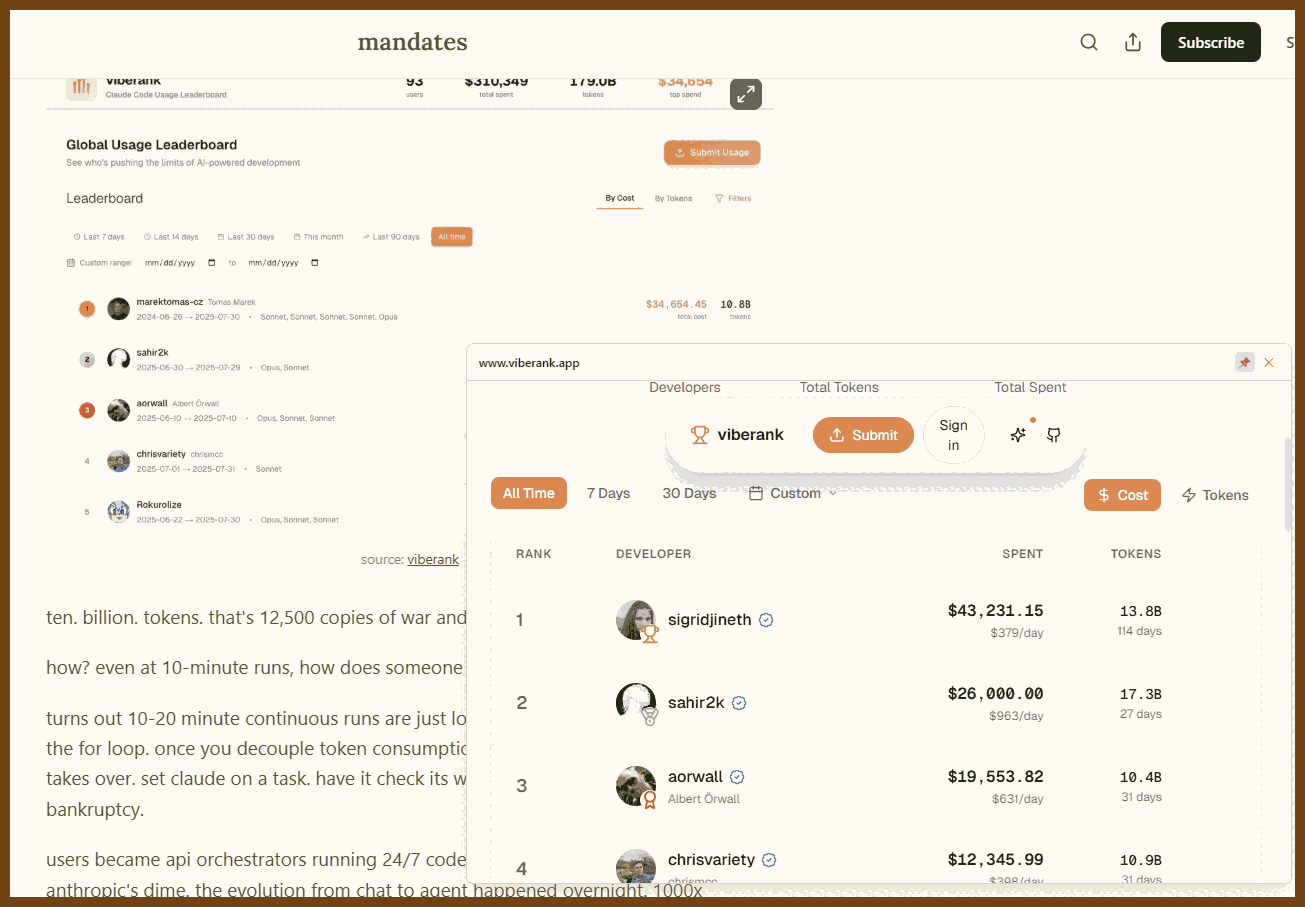

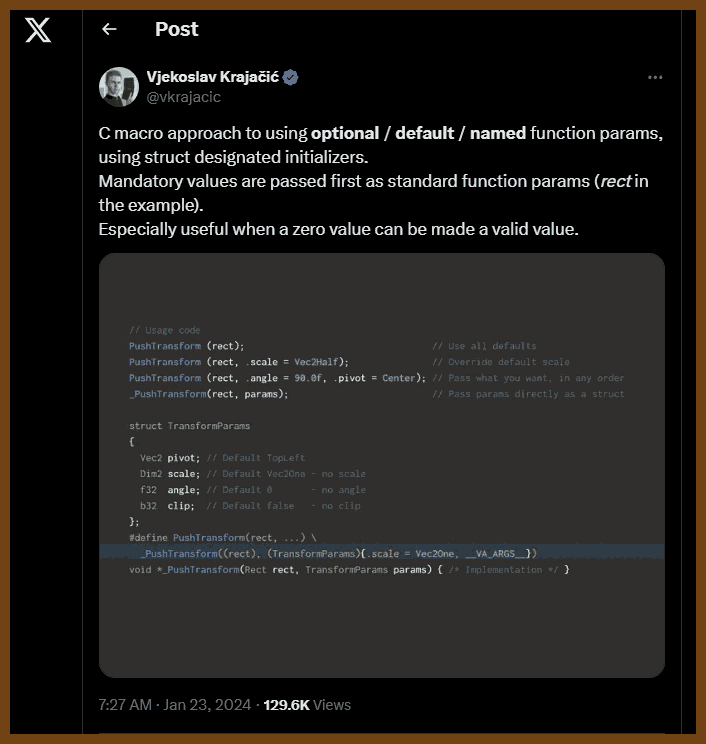
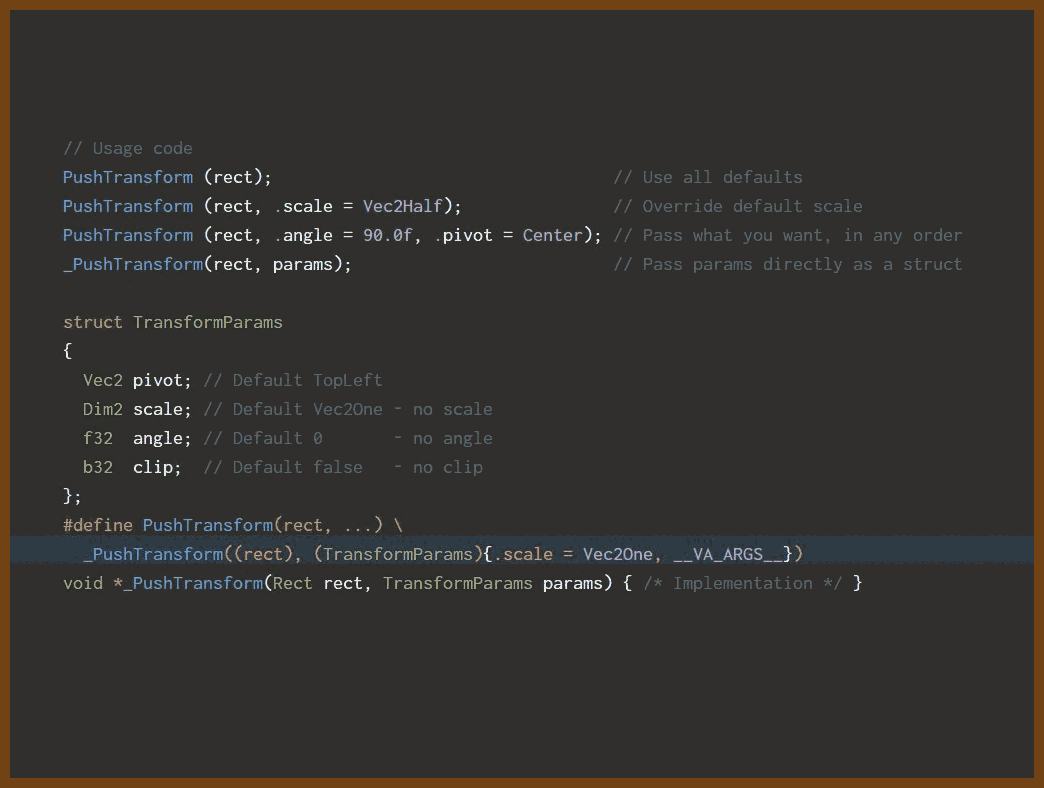
 Speaker Eskil Steenberg – game-engine and tools developer (Quel Solaar)
Recording Seattle, Oct 2016 (2 h 11 m)
Speaker Eskil Steenberg – game-engine and tools developer (Quel Solaar)
Recording Seattle, Oct 2016 (2 h 11 m)
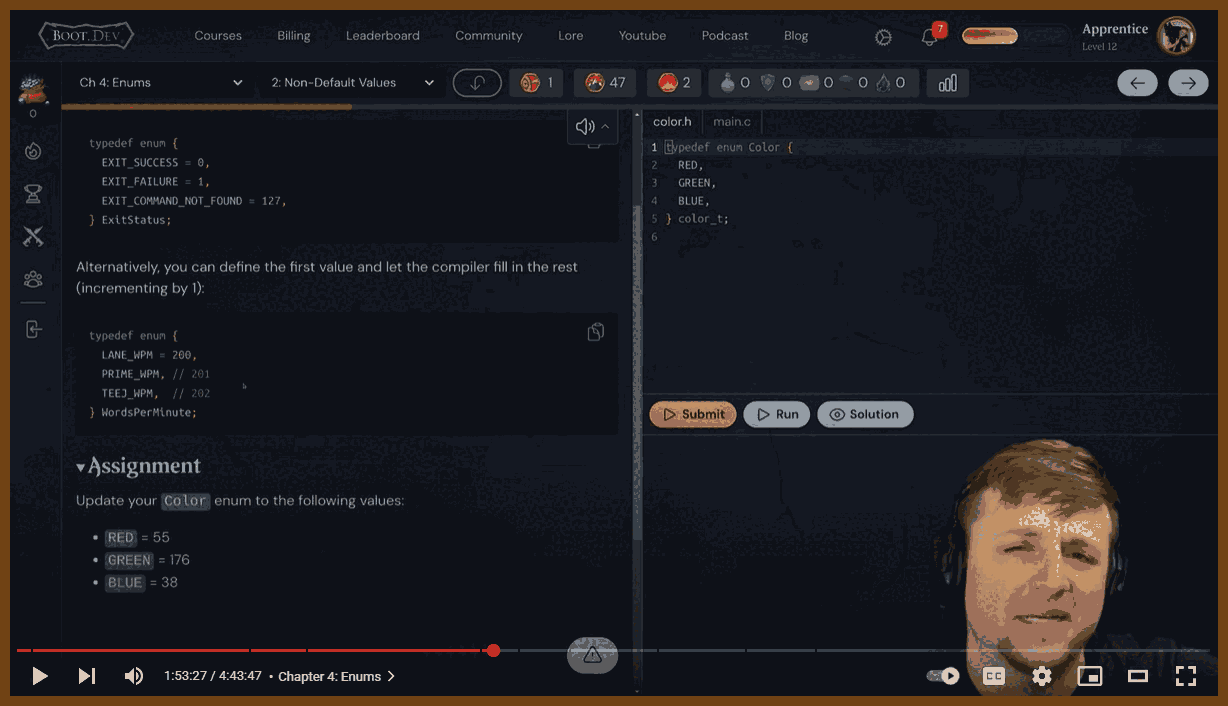


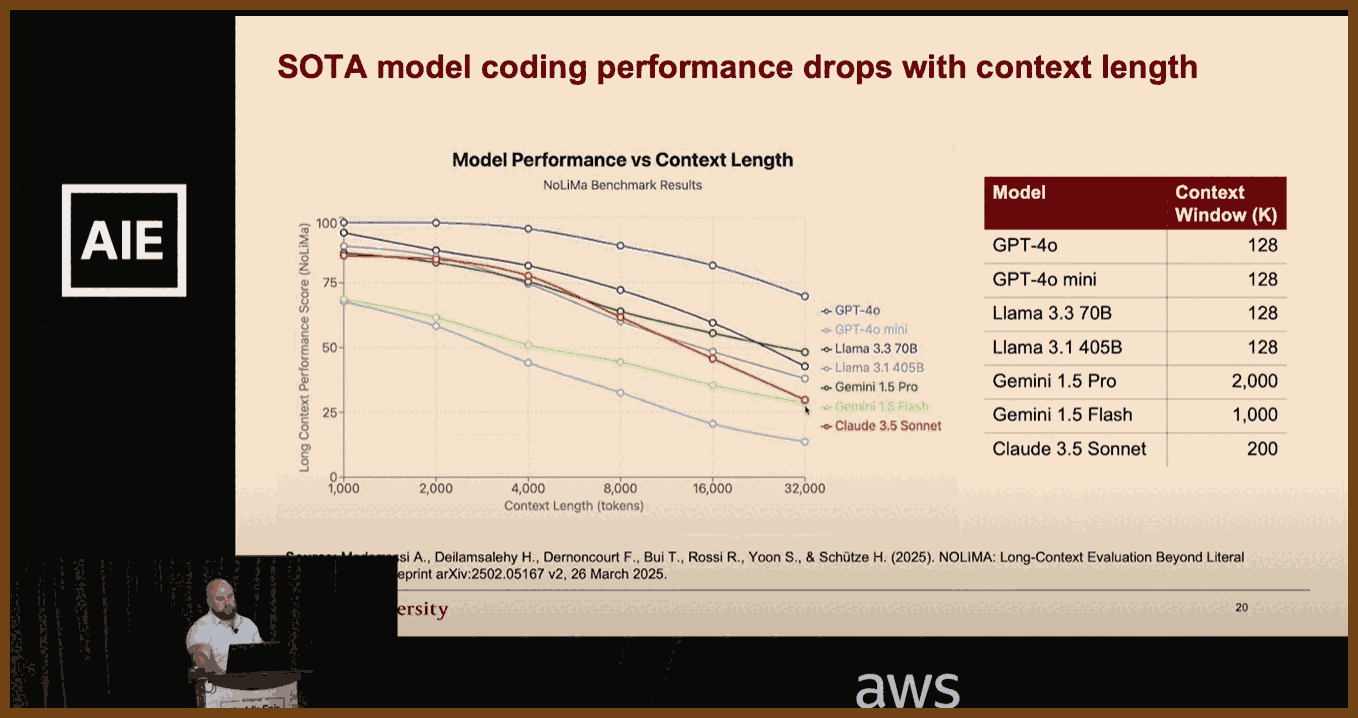
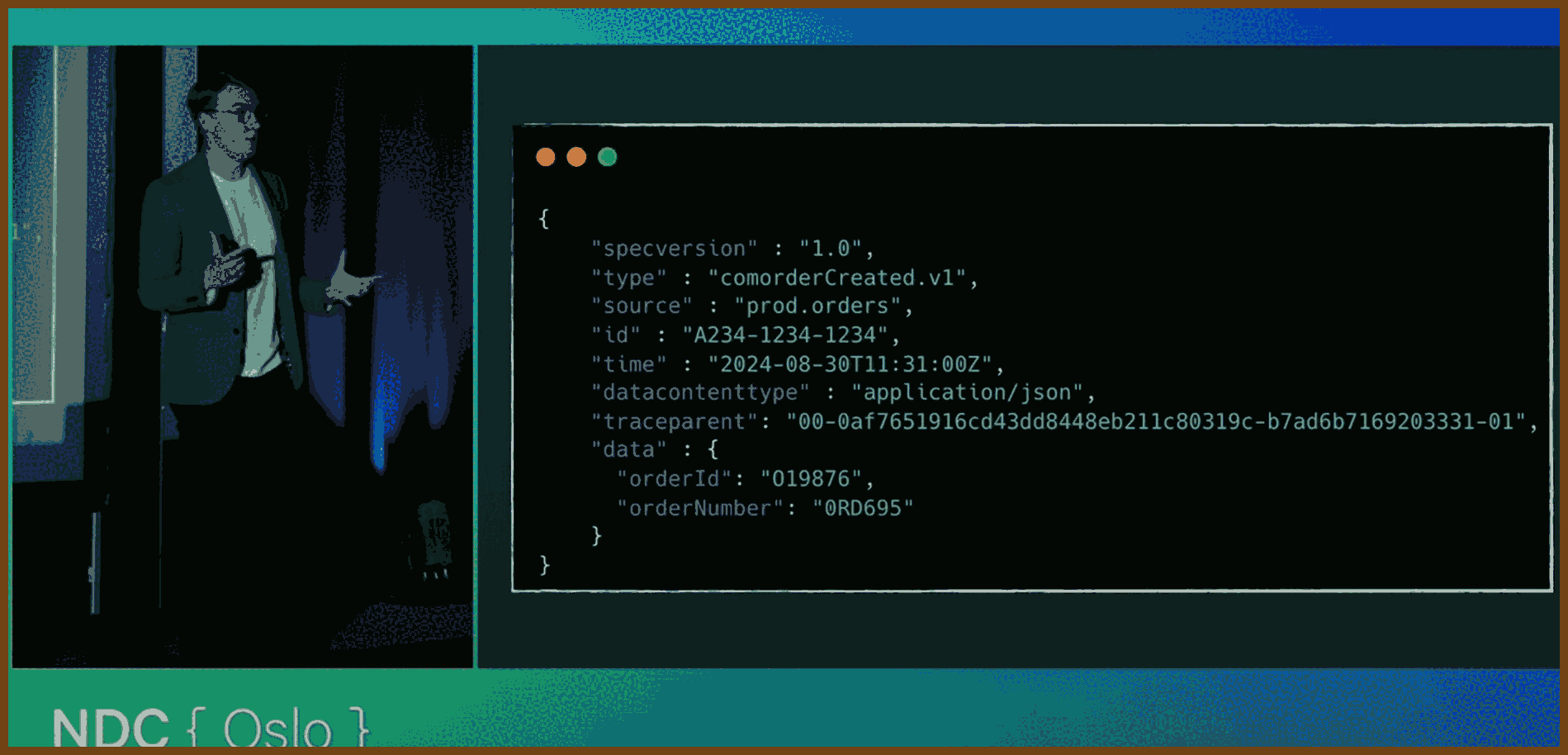
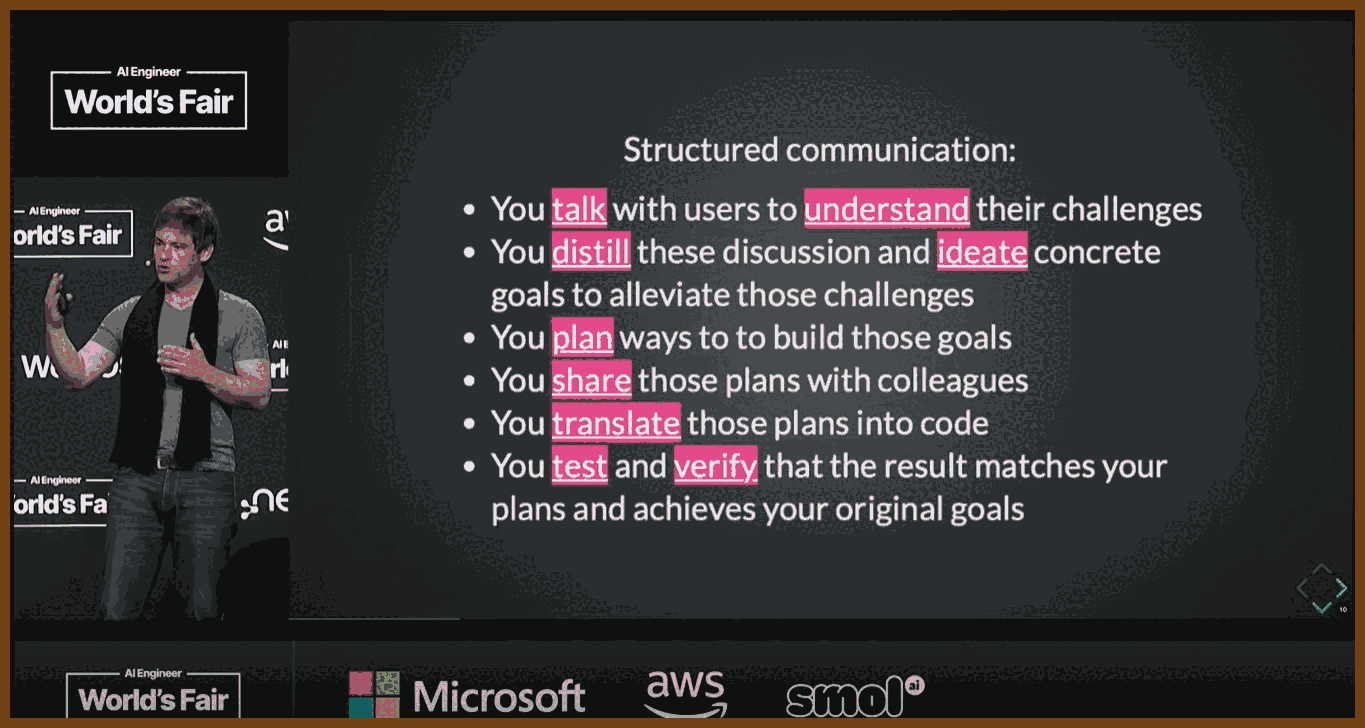






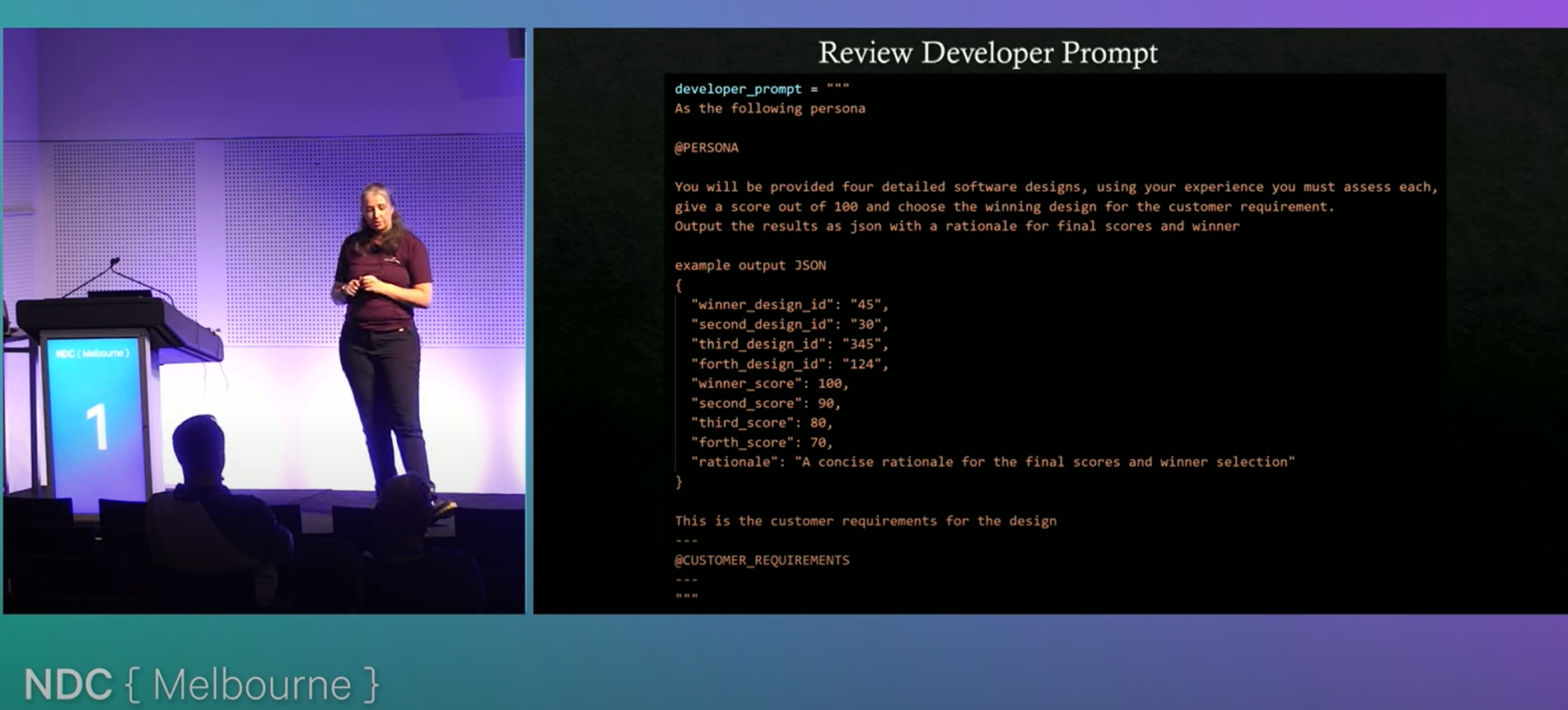 I built 1,000 architects using AI—each with a name, country, skillset, and headshot
I asked a language model to make me architect profiles. I told it their gender, country, and years of experience. Then I got it to generate a photo too. I used tools like DALL-E and ChatGPT to get realistic images.
I built 1,000 architects using AI—each with a name, country, skillset, and headshot
I asked a language model to make me architect profiles. I told it their gender, country, and years of experience. Then I got it to generate a photo too. I used tools like DALL-E and ChatGPT to get realistic images.




 I’ve been thinking a lot about something I call change energy. Everyone’s got a different threshold for how much change they can handle — their living situation, work, even what they eat. Too much stability feels boring, but too much change feels overwhelming. It’s all about where you sit on that spectrum.
I’ve been thinking a lot about something I call change energy. Everyone’s got a different threshold for how much change they can handle — their living situation, work, even what they eat. Too much stability feels boring, but too much change feels overwhelming. It’s all about where you sit on that spectrum.

 Caught in a heavy downpour but grateful to be warm and dry inside, the speaker dives into a list of surprisingly useful tools. First is Webcam Eyes, a 200-line shell script that effortlessly mounts most modern cameras as webcams—especially useful for recording with tools like
Caught in a heavy downpour but grateful to be warm and dry inside, the speaker dives into a list of surprisingly useful tools. First is Webcam Eyes, a 200-line shell script that effortlessly mounts most modern cameras as webcams—especially useful for recording with tools like 

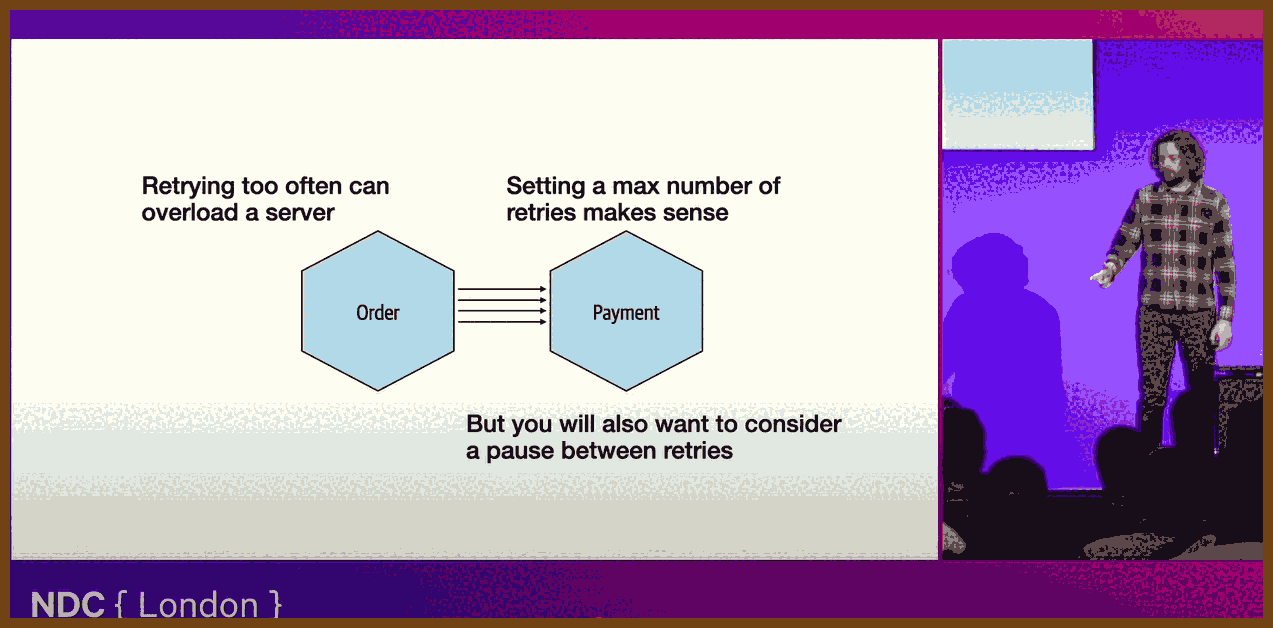

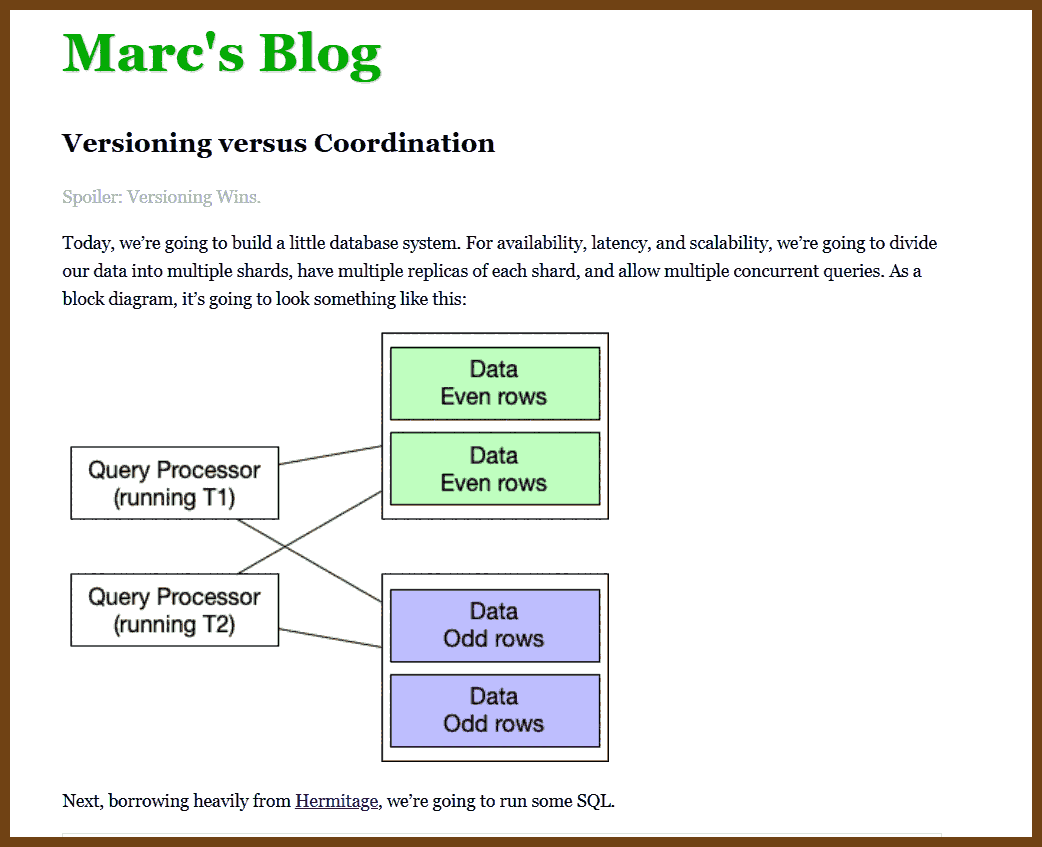
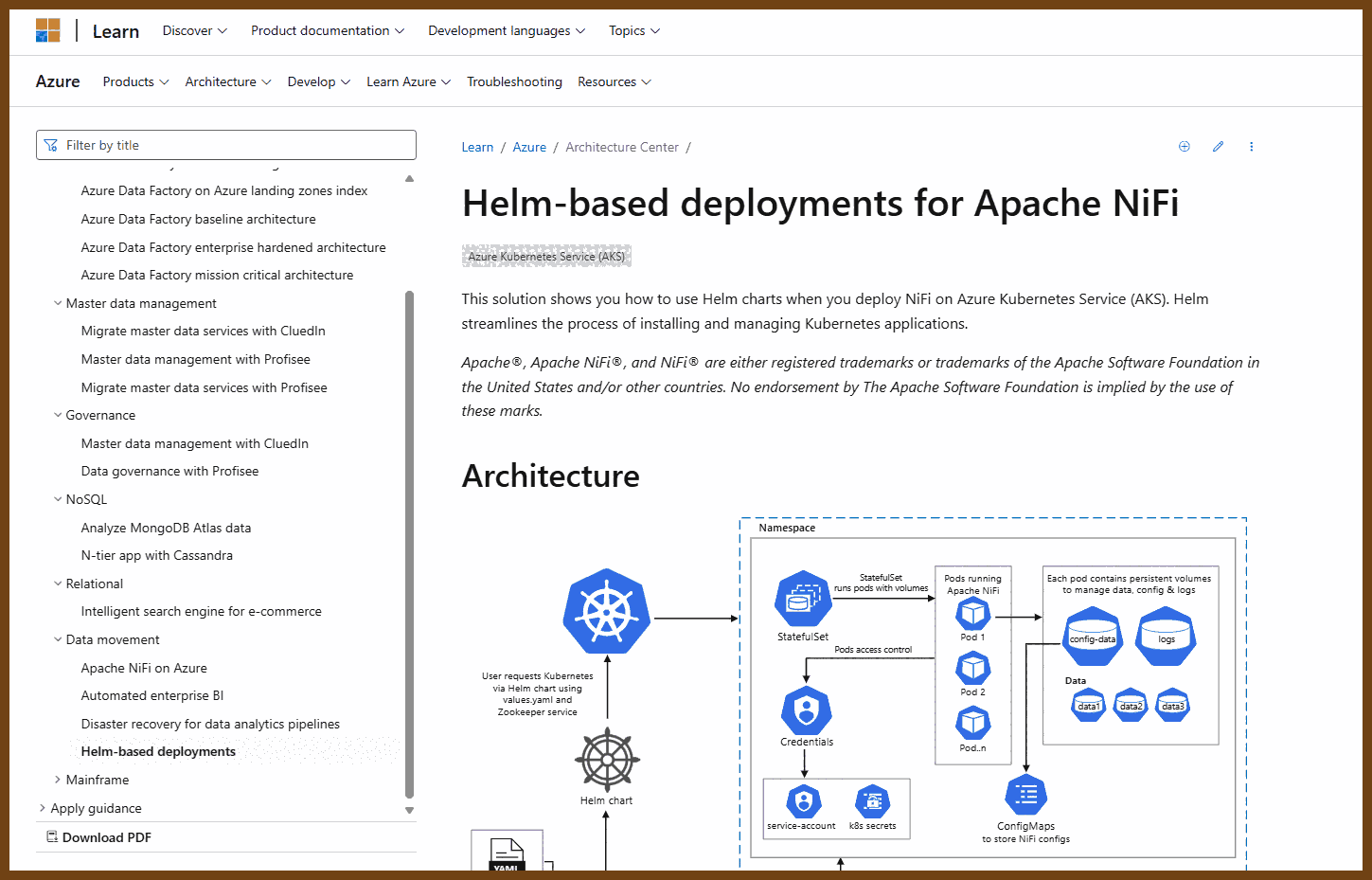

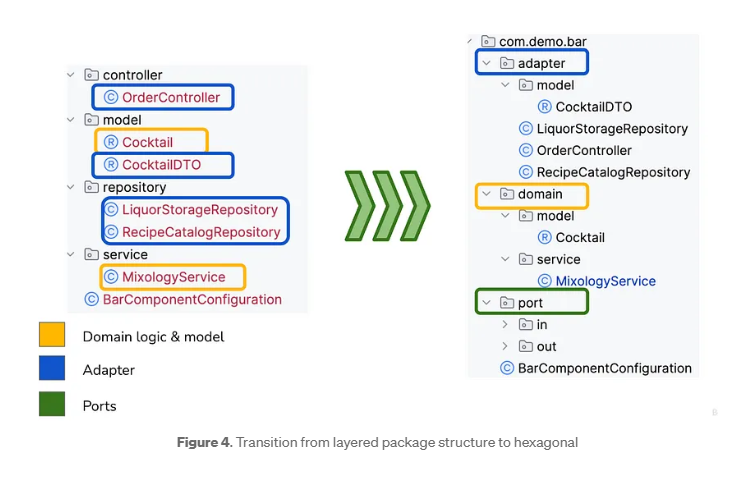
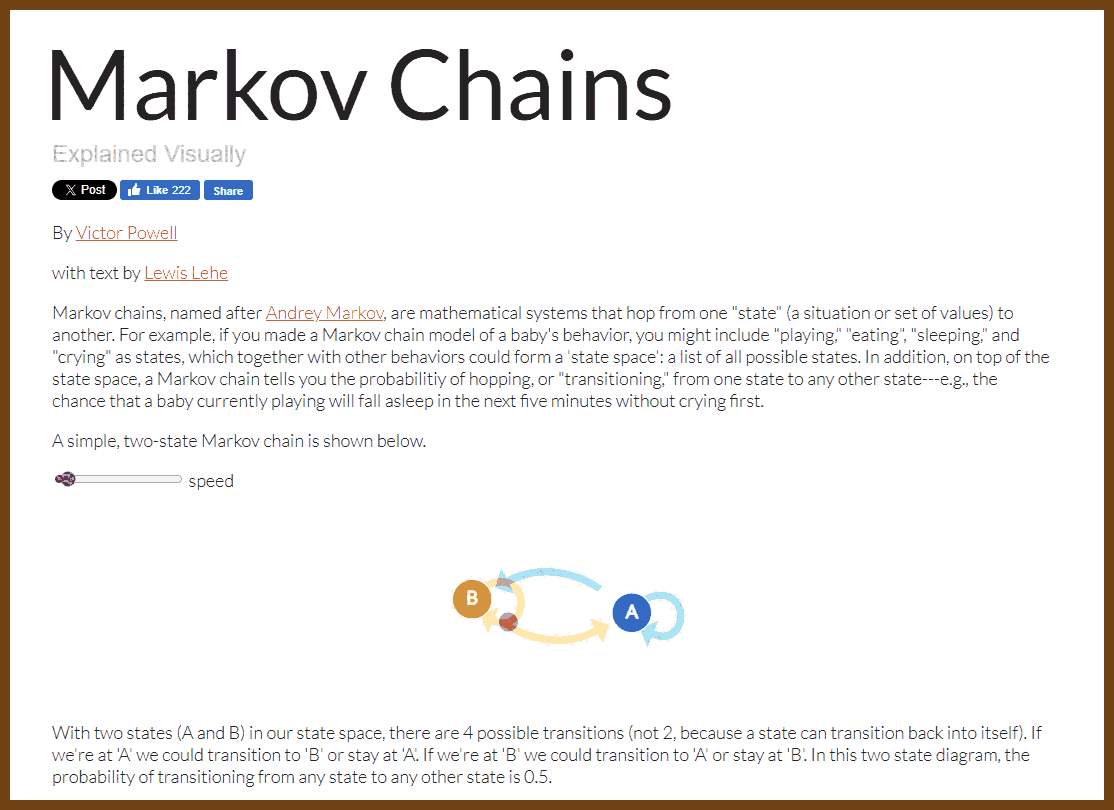
 (found in 2025-02-23
(found in 2025-02-23 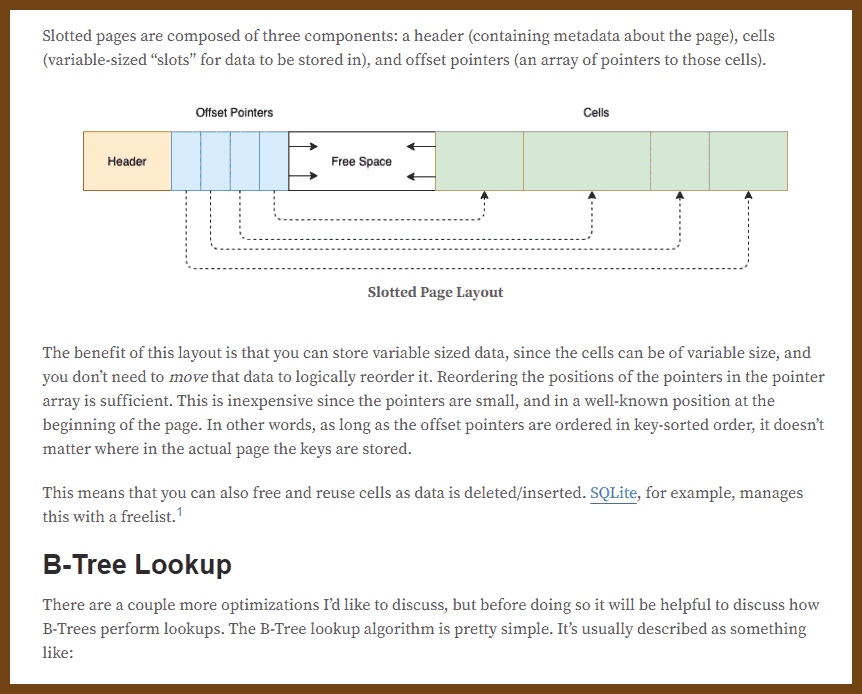
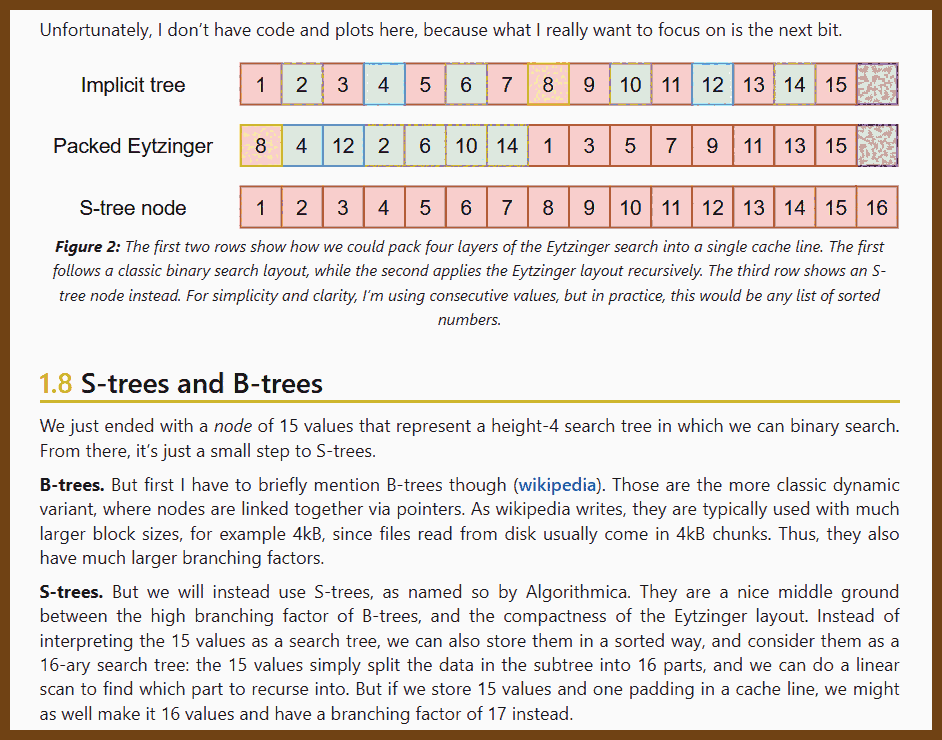

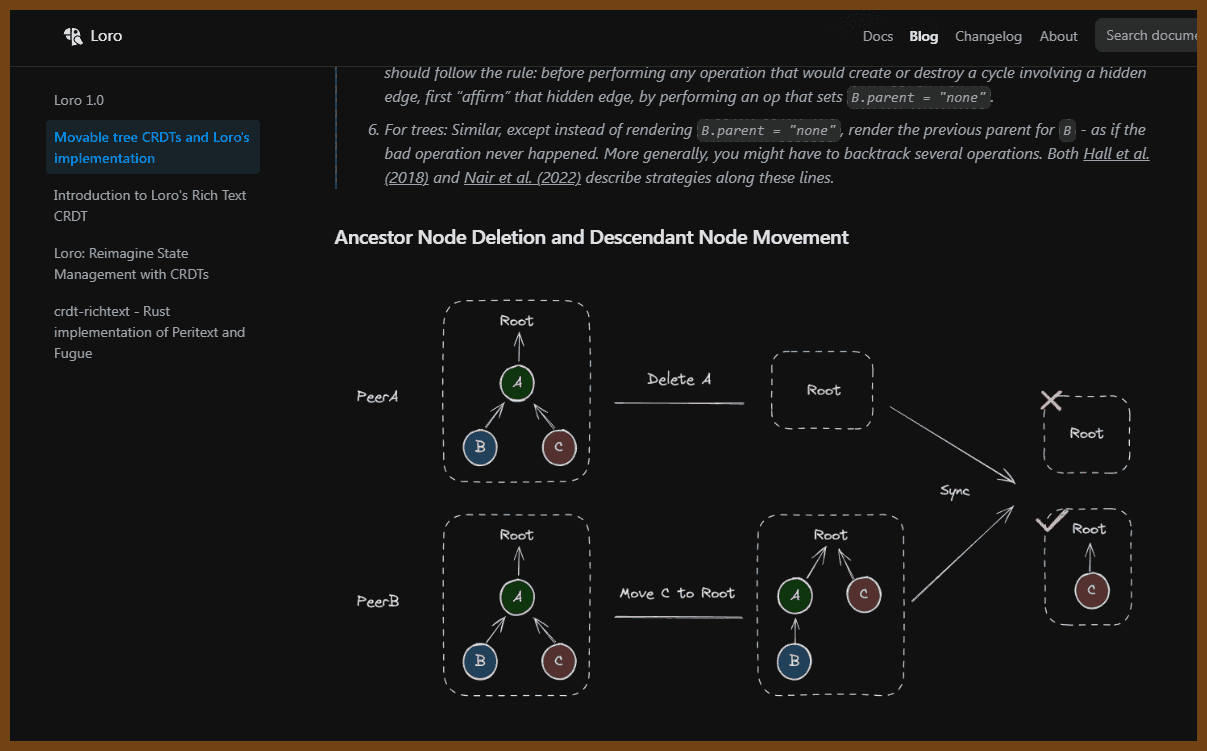
 "It's like Git, for your data."
"It's like Git, for your data."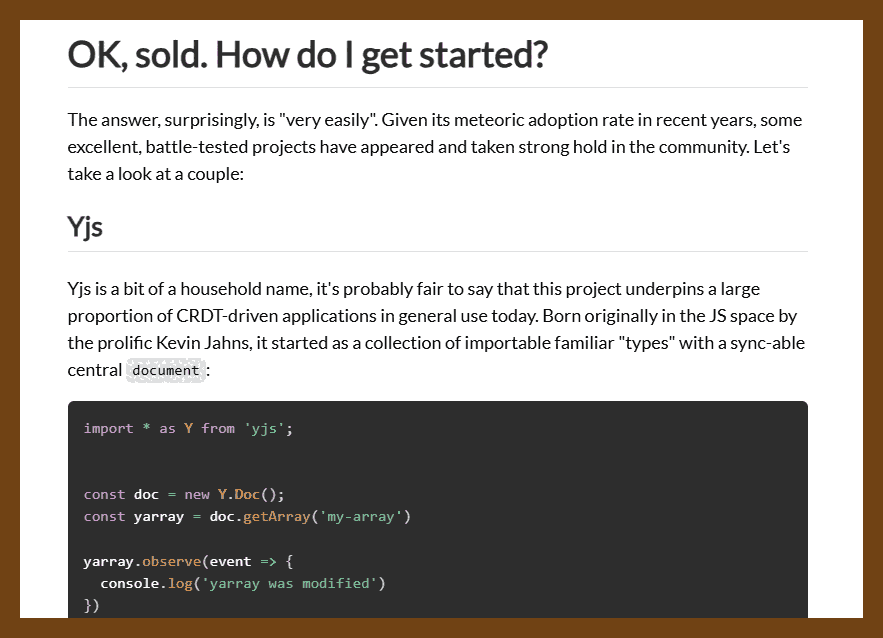
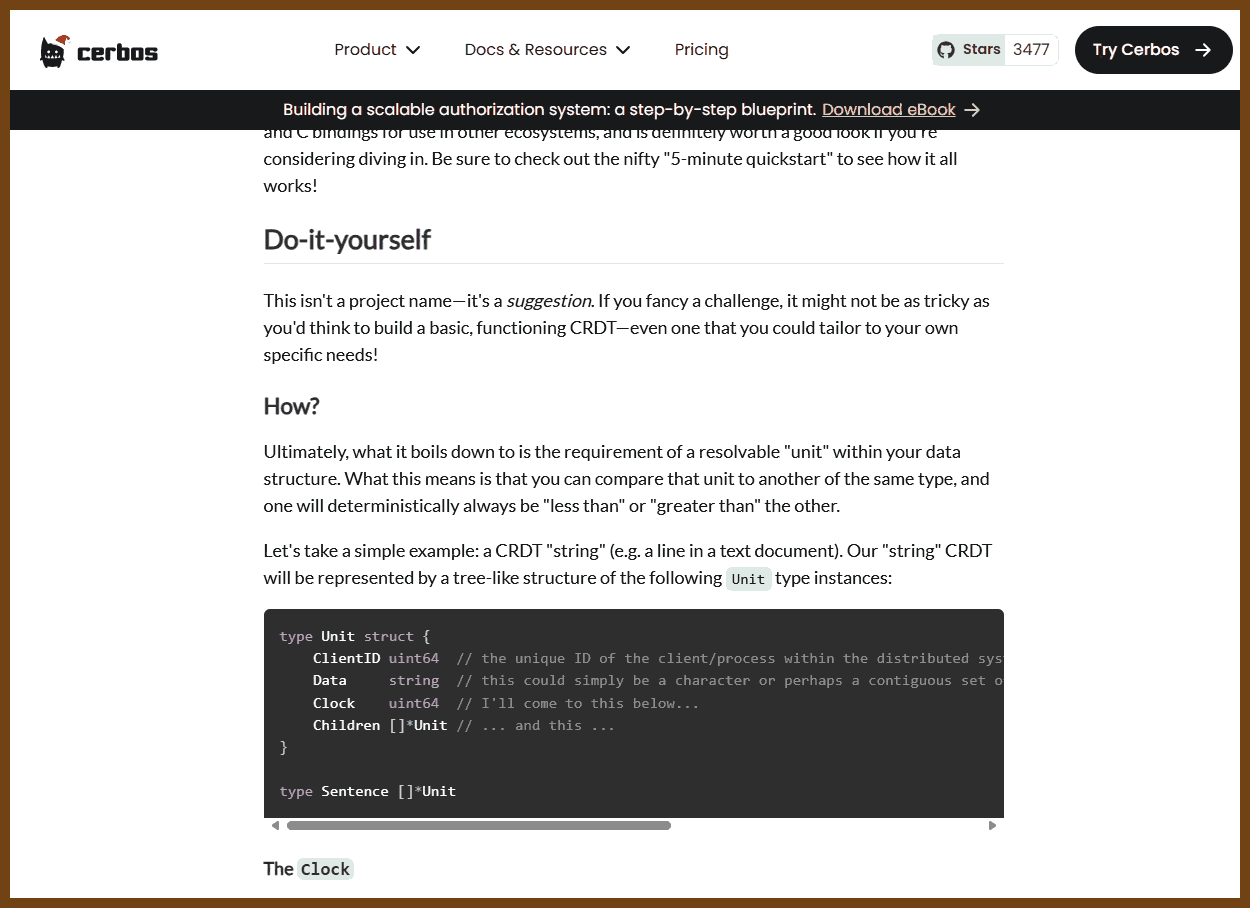
 Try the
Try the 



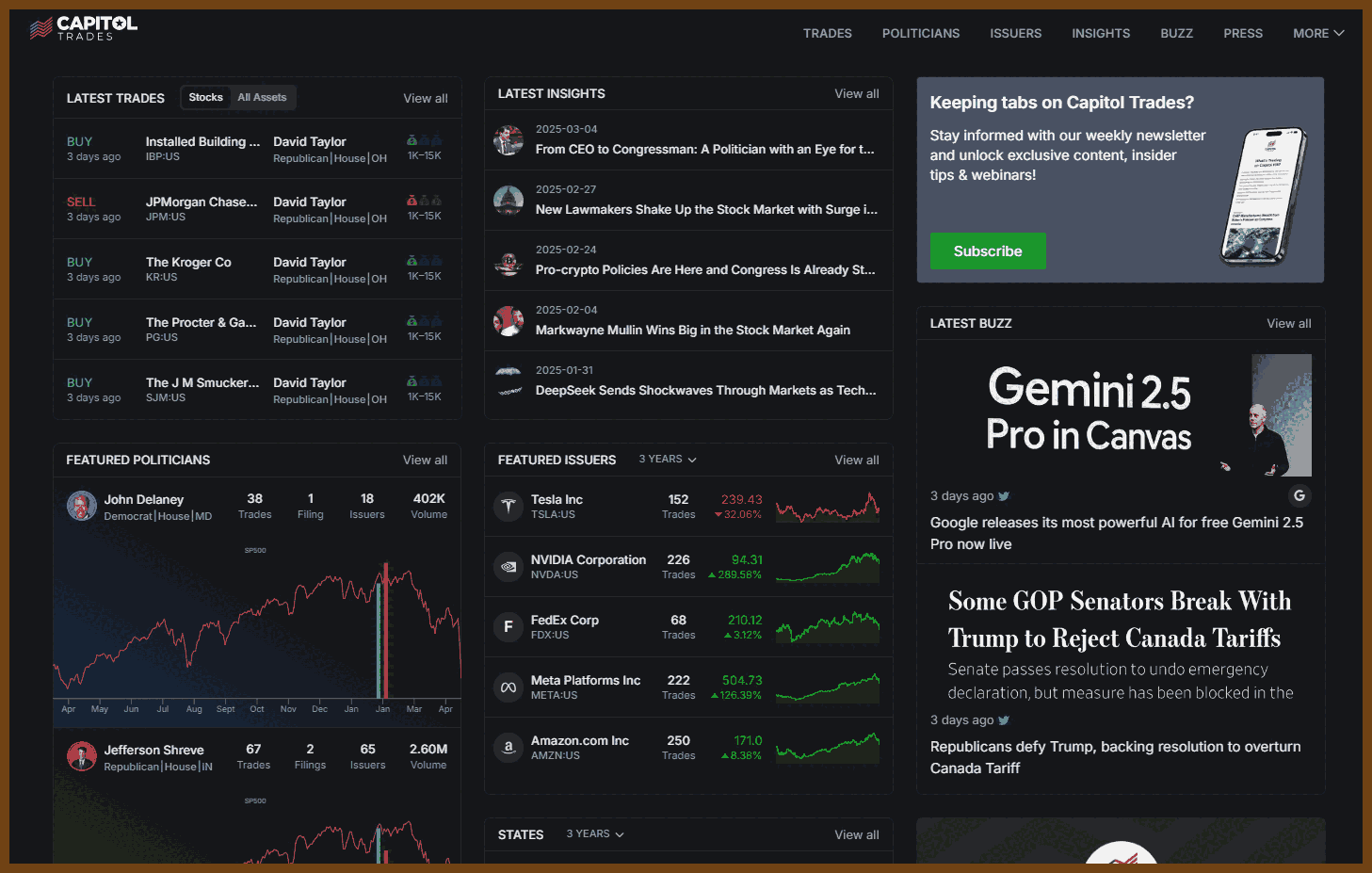



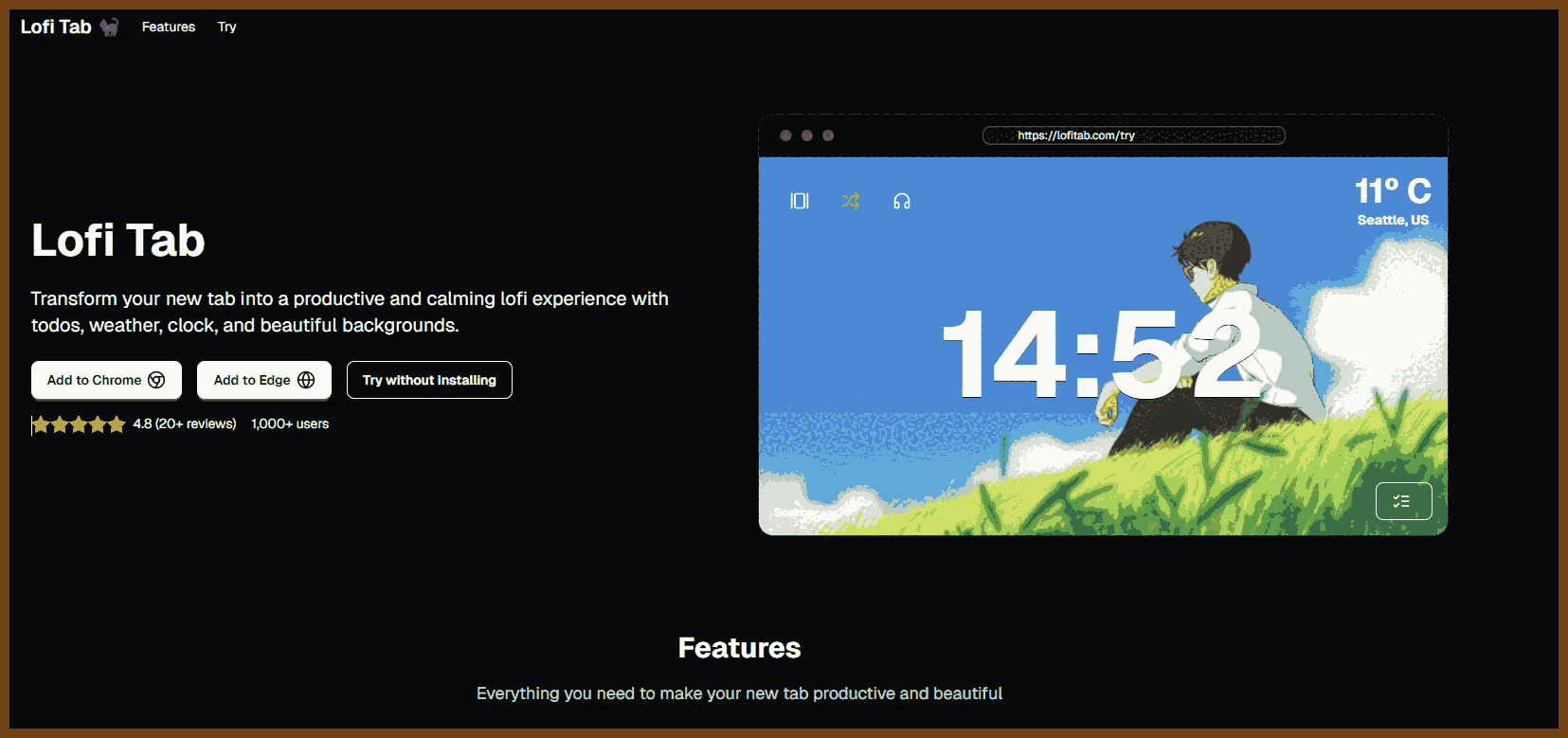
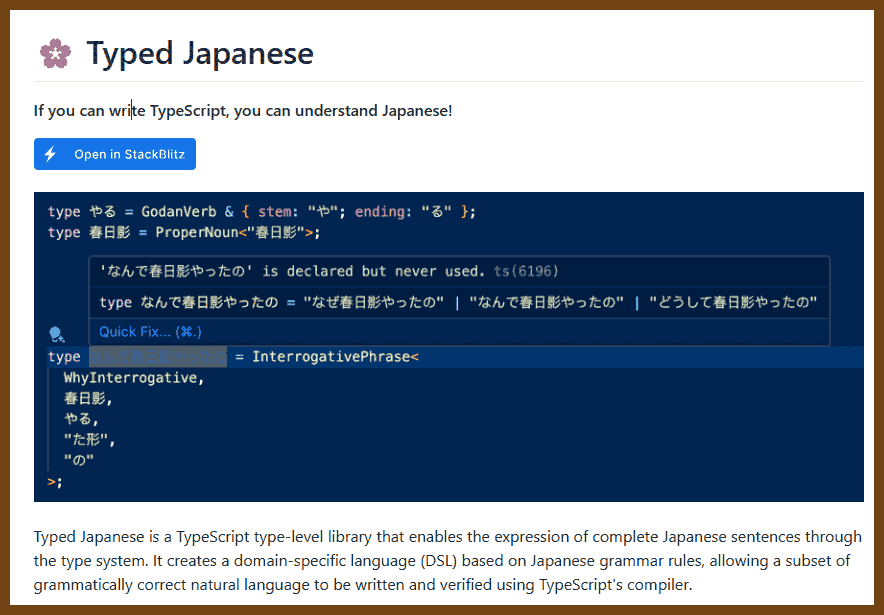




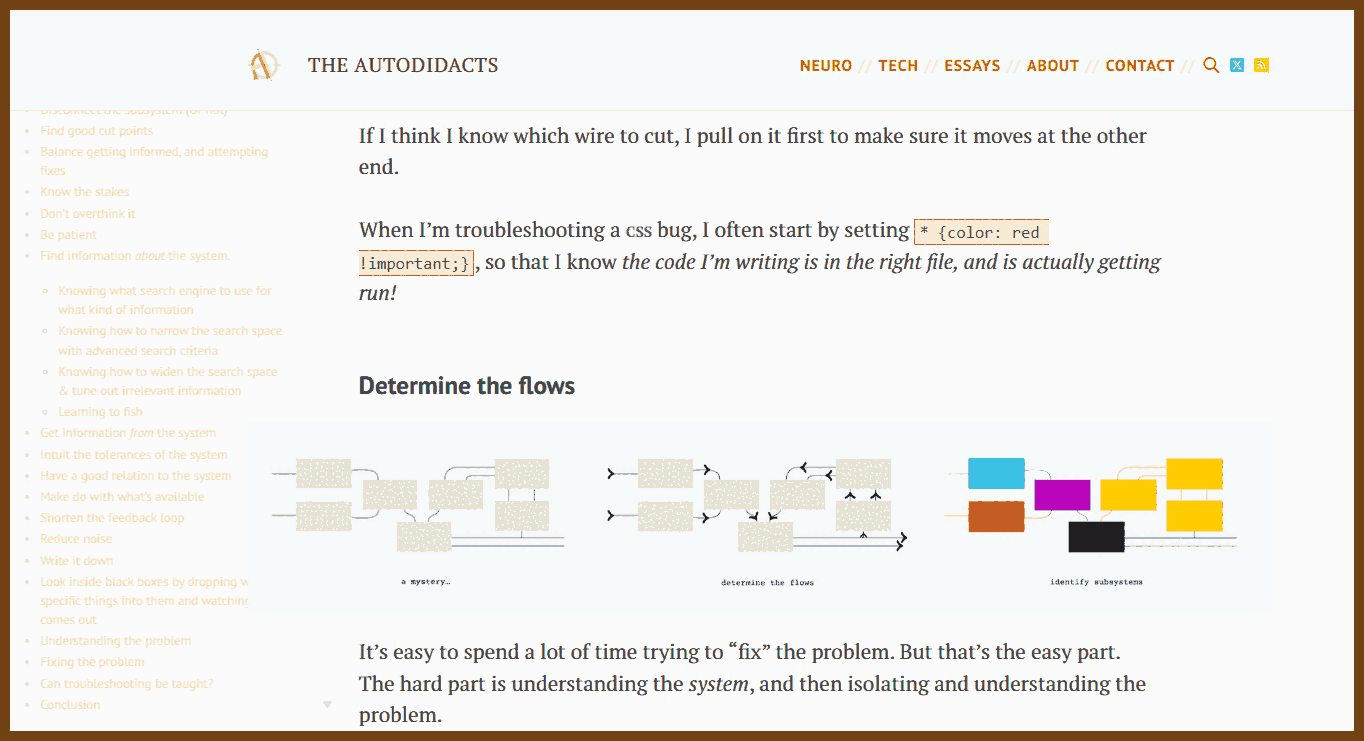


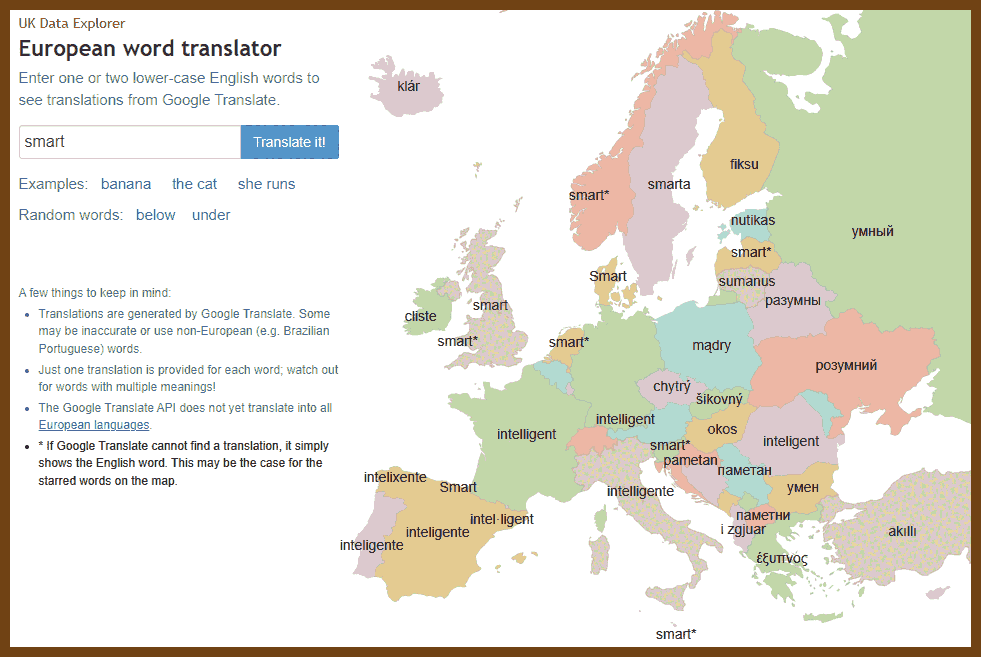


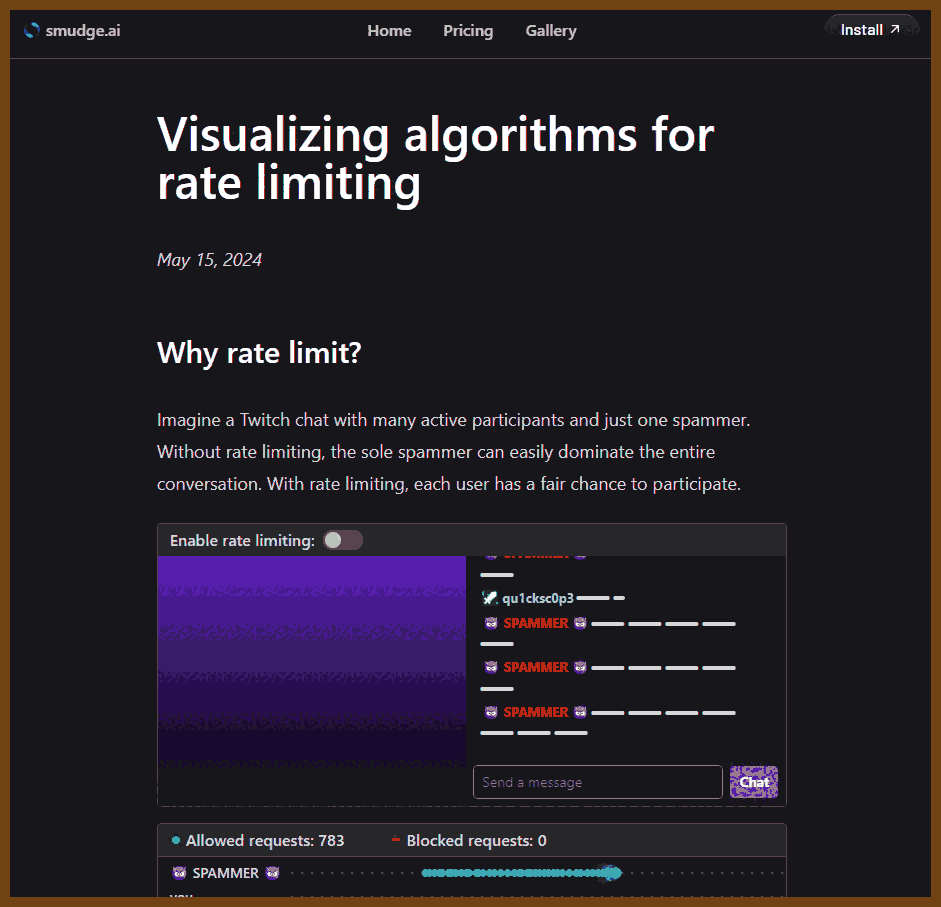

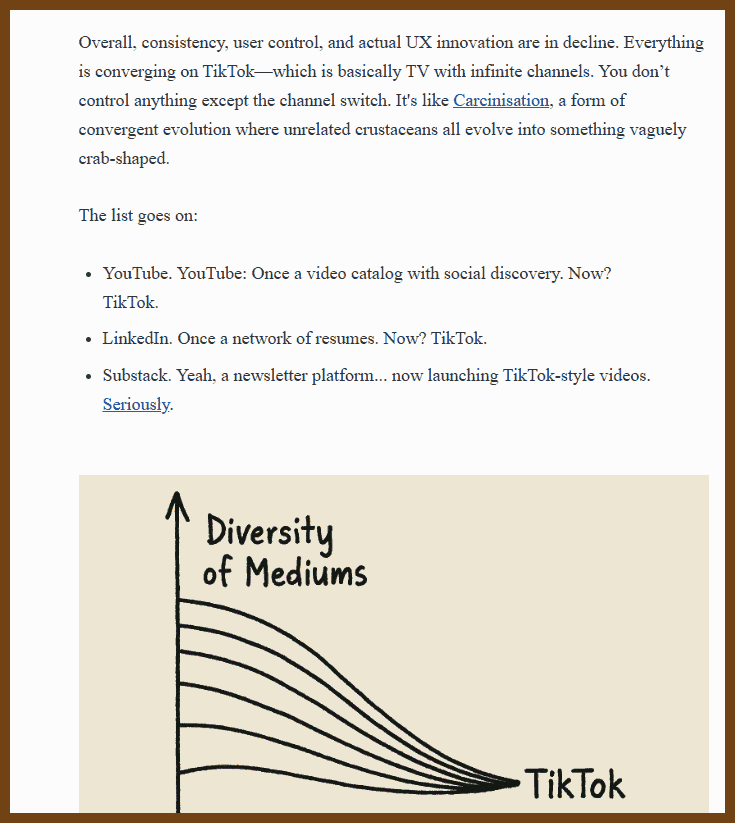



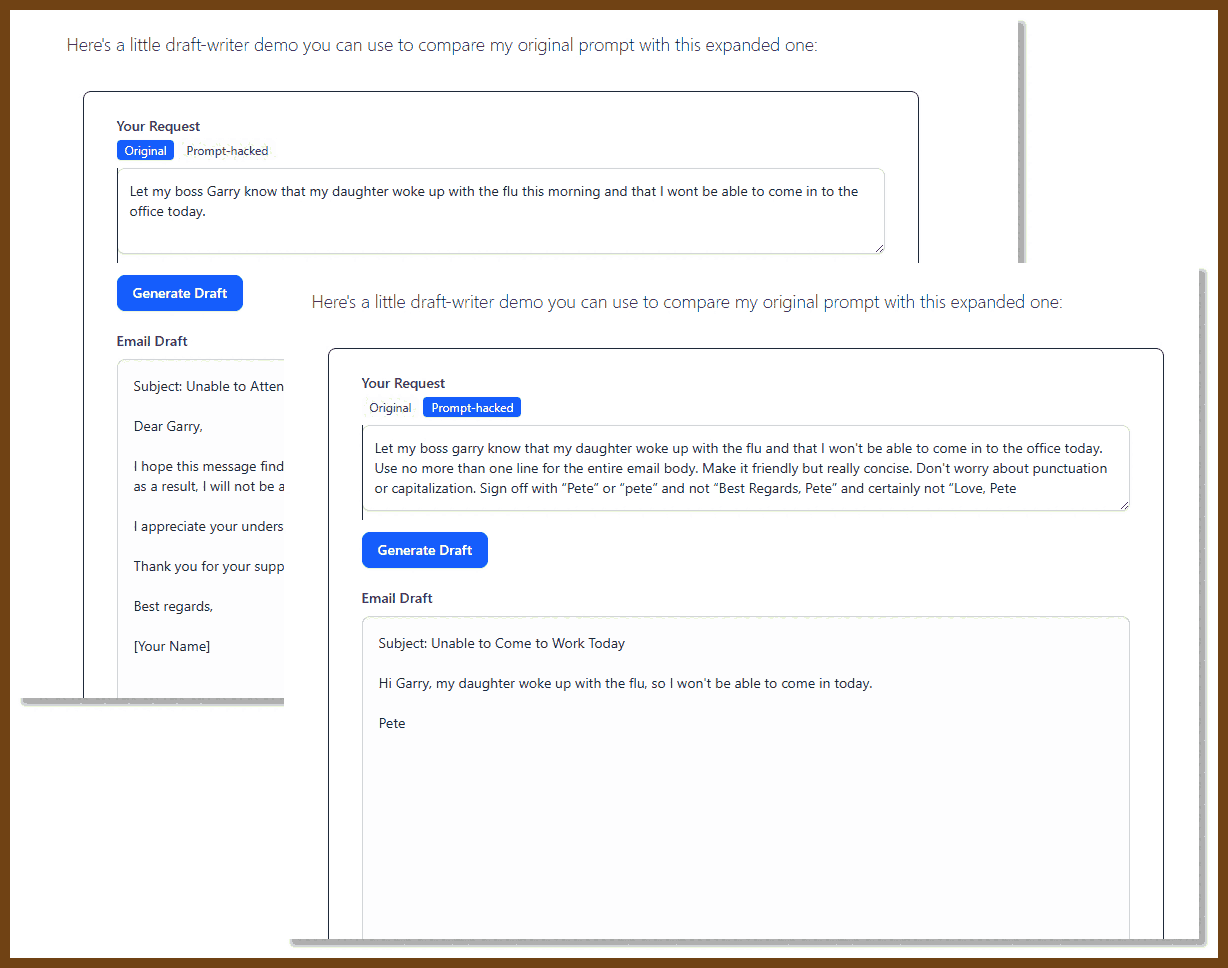
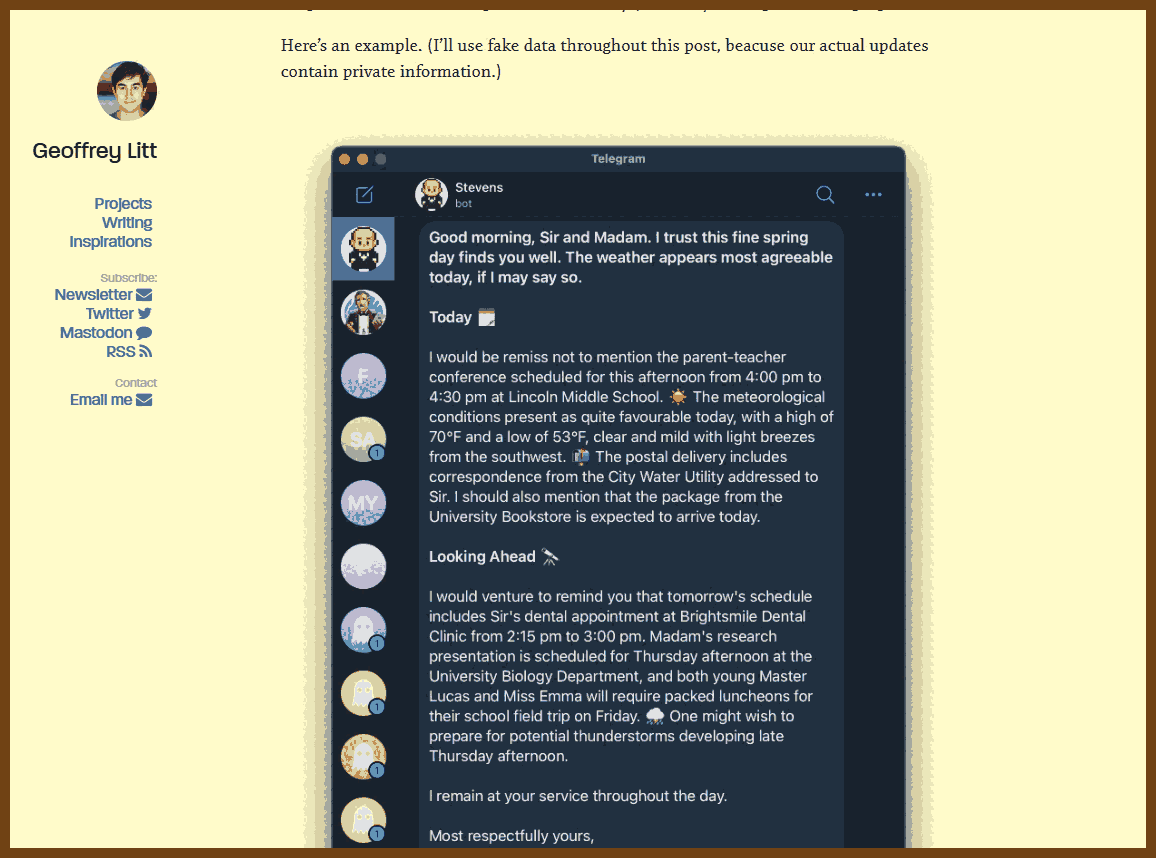
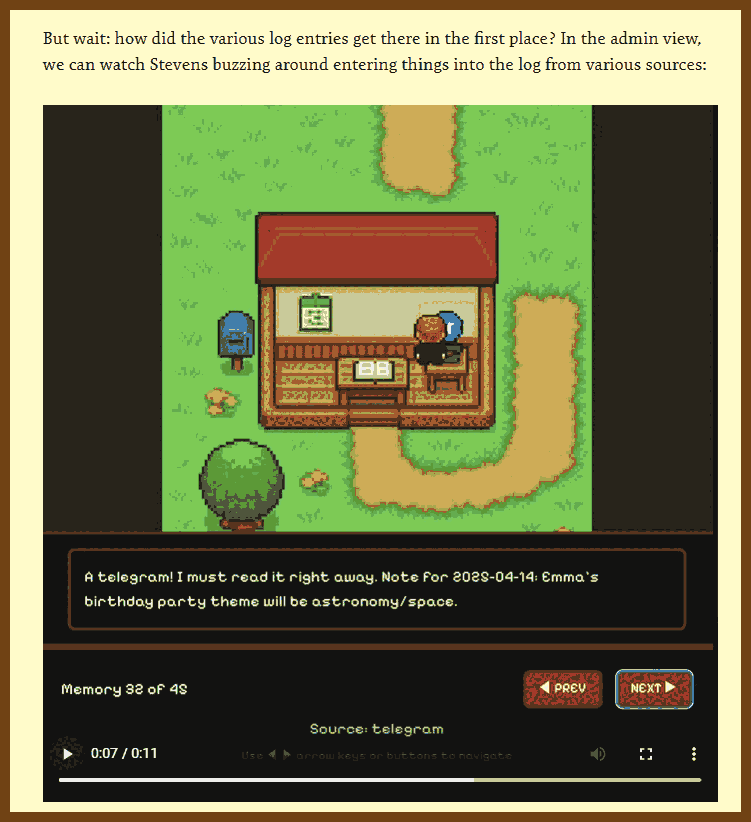
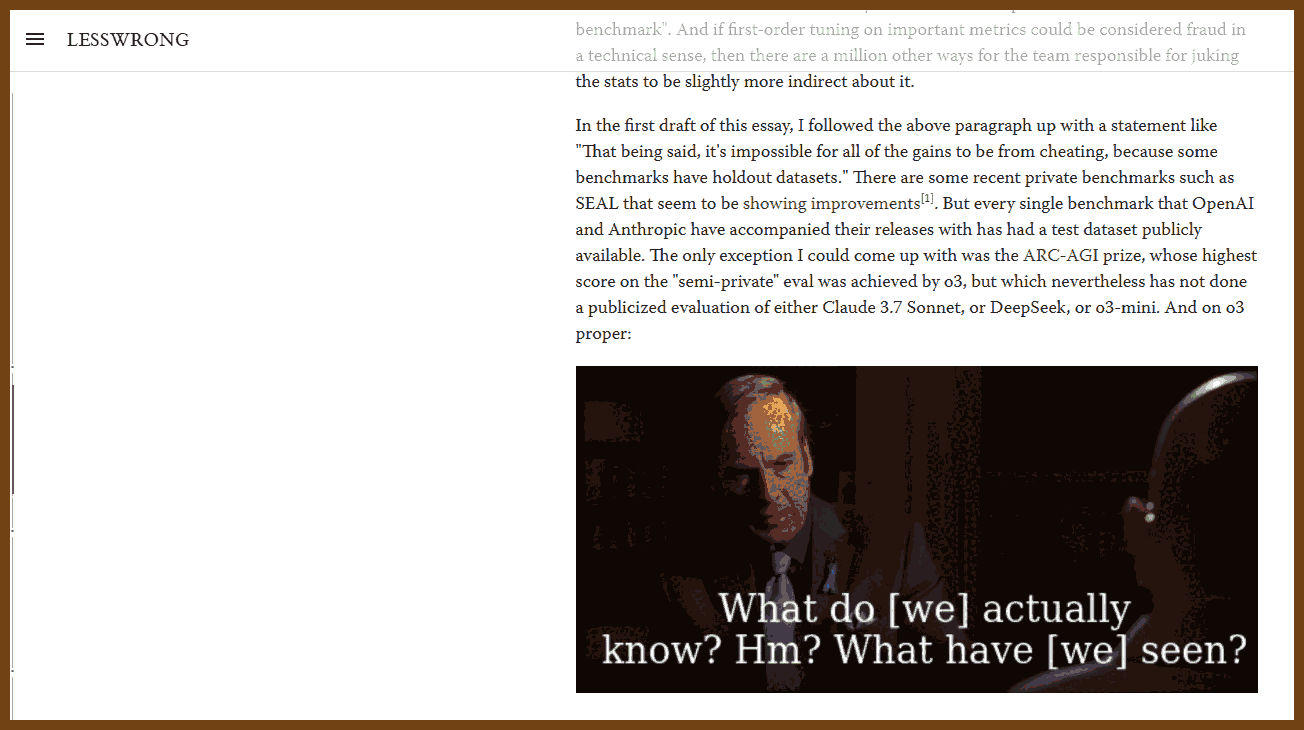

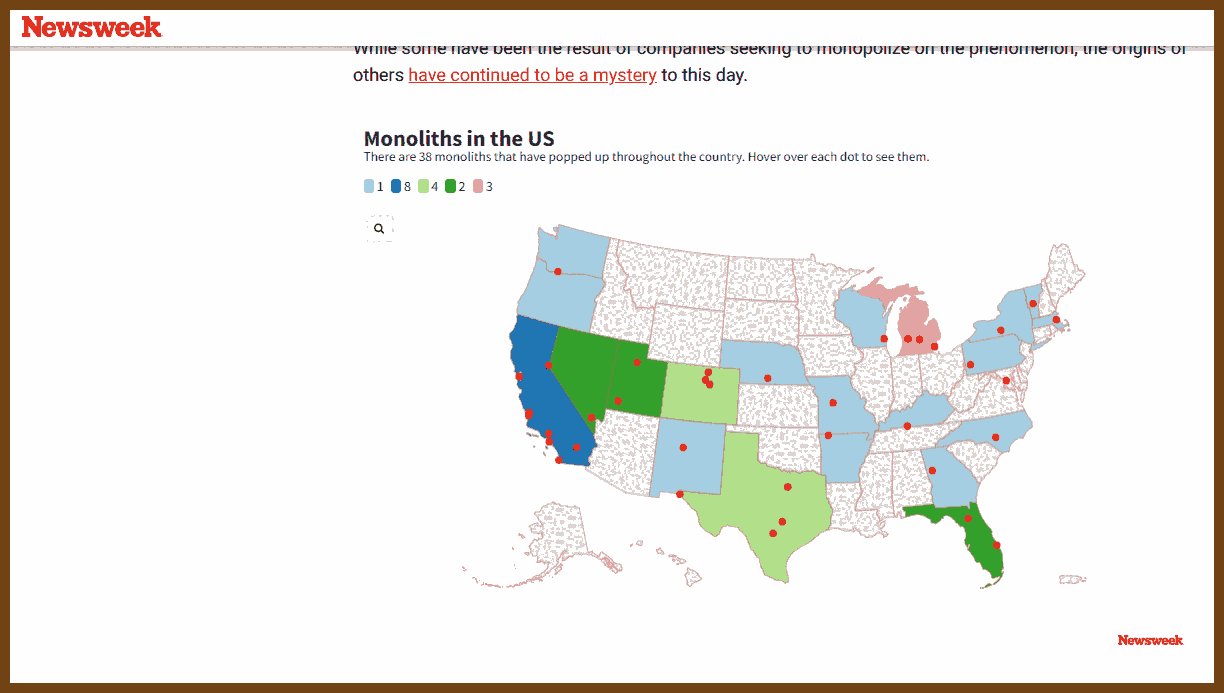



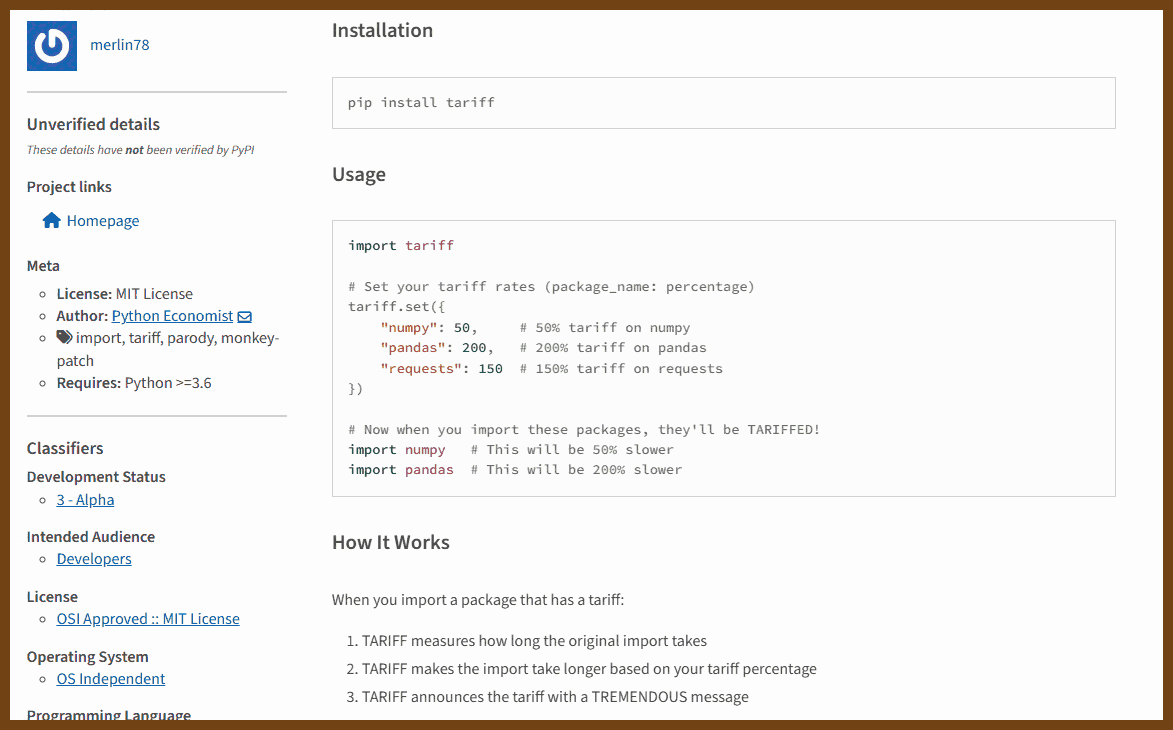
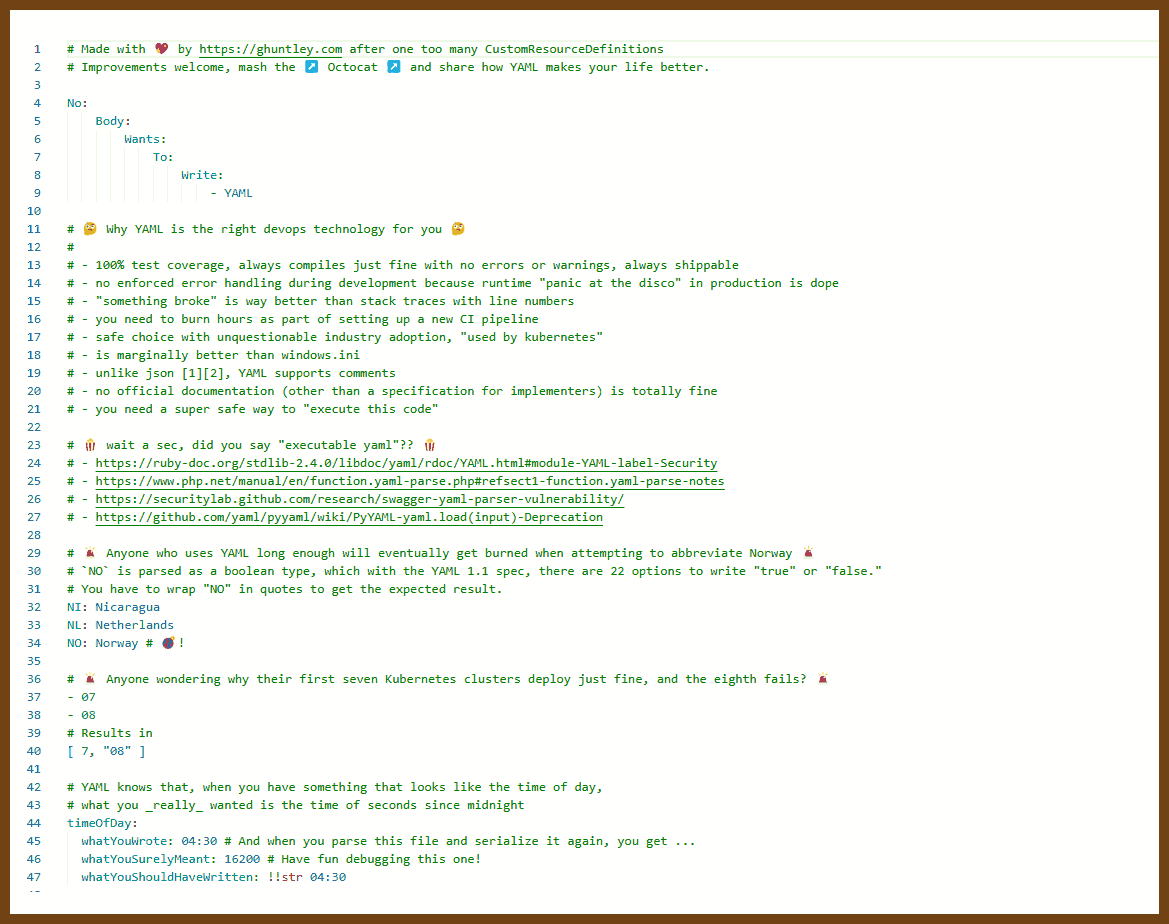

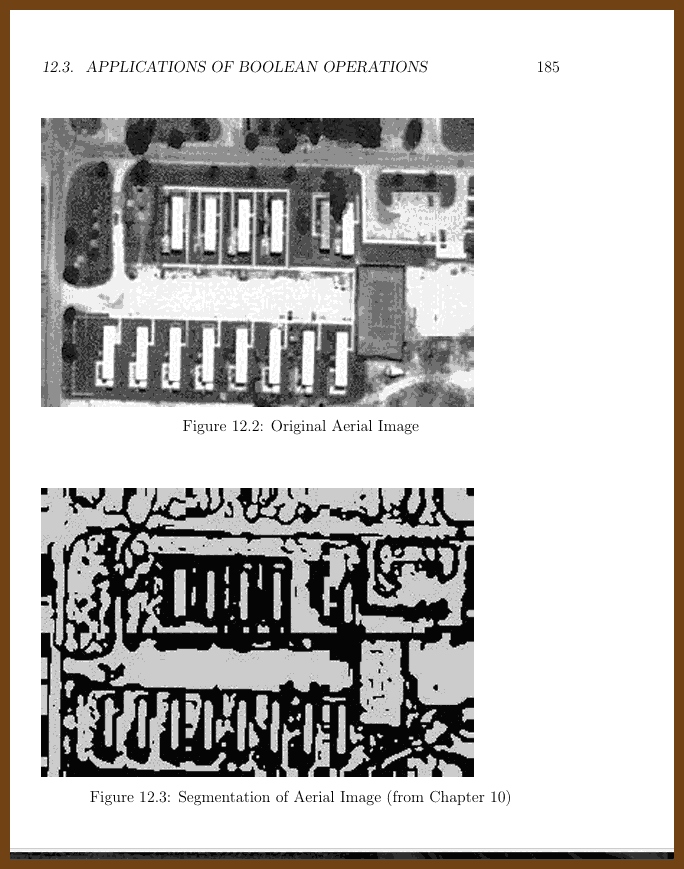
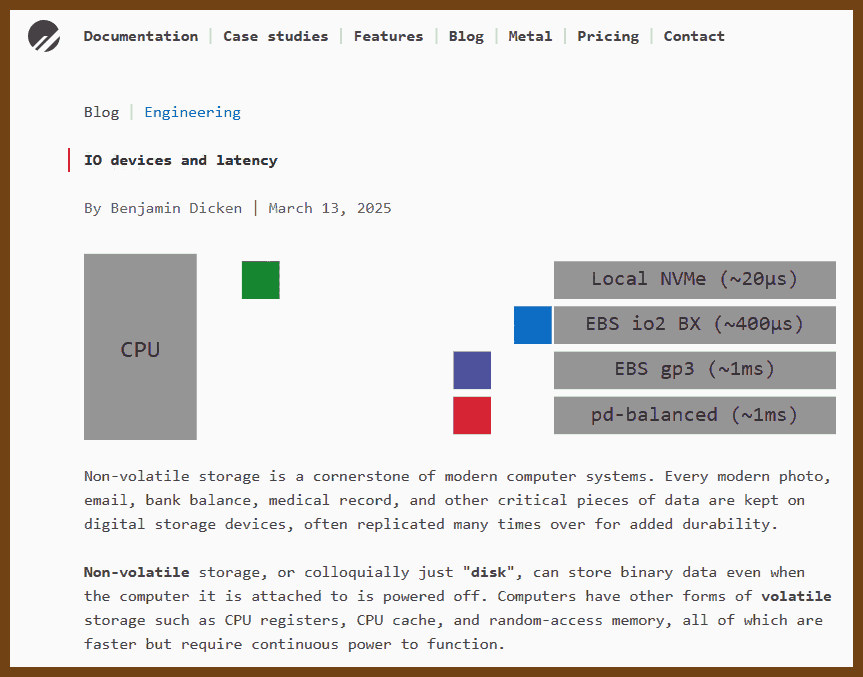

 Tauri 2.0 is a framework designed for creating small, fast, and secure cross-platform applications. It supports a wide range of operating systems, including Linux, macOS, Windows, Android, and iOS, enabling developers to build from a single codebase. Tauri is frontend-independent, allowing integration with any web stack, and uses inter-process communication to seamlessly combine JavaScript for the frontend and Rust for application logic. It prioritizes security, optimizes for minimal application size (as small as 600KB), and leverages Rust's performance and safety features to provide next-generation app solutions.
Tauri 2.0 is a framework designed for creating small, fast, and secure cross-platform applications. It supports a wide range of operating systems, including Linux, macOS, Windows, Android, and iOS, enabling developers to build from a single codebase. Tauri is frontend-independent, allowing integration with any web stack, and uses inter-process communication to seamlessly combine JavaScript for the frontend and Rust for application logic. It prioritizes security, optimizes for minimal application size (as small as 600KB), and leverages Rust's performance and safety features to provide next-generation app solutions.
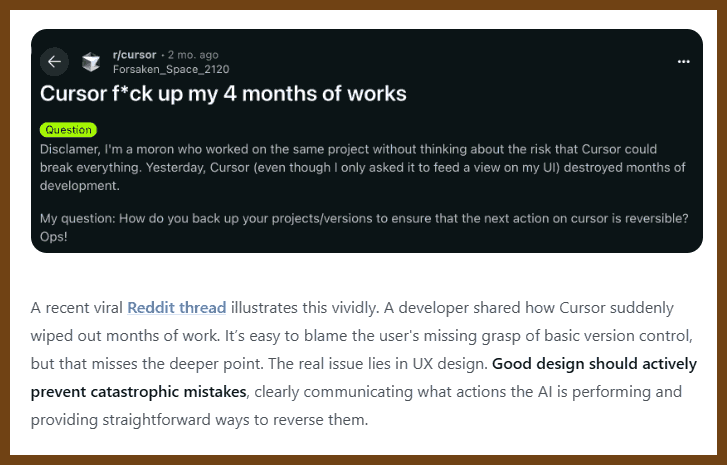
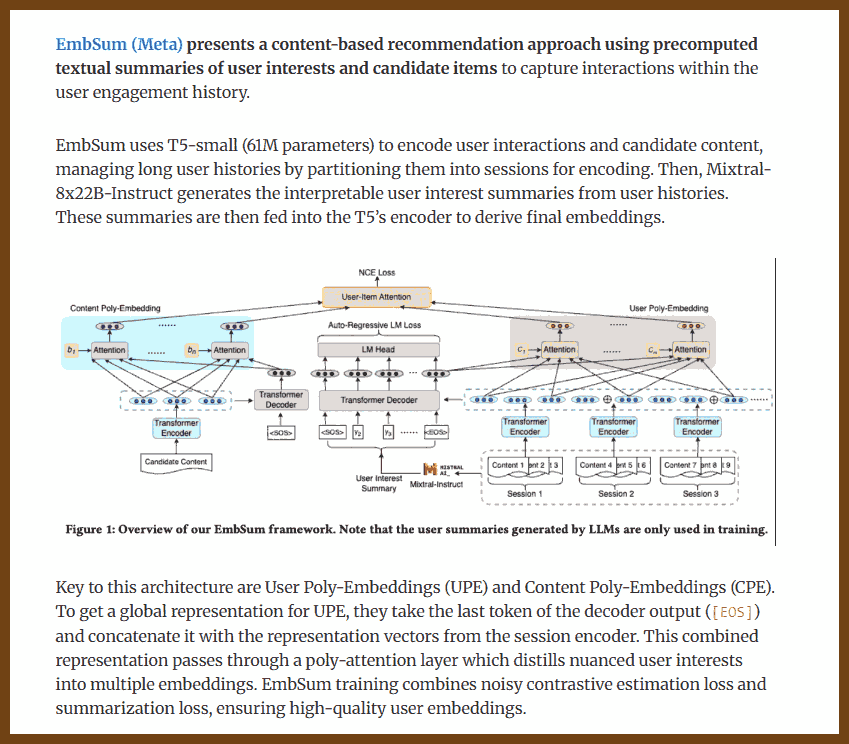
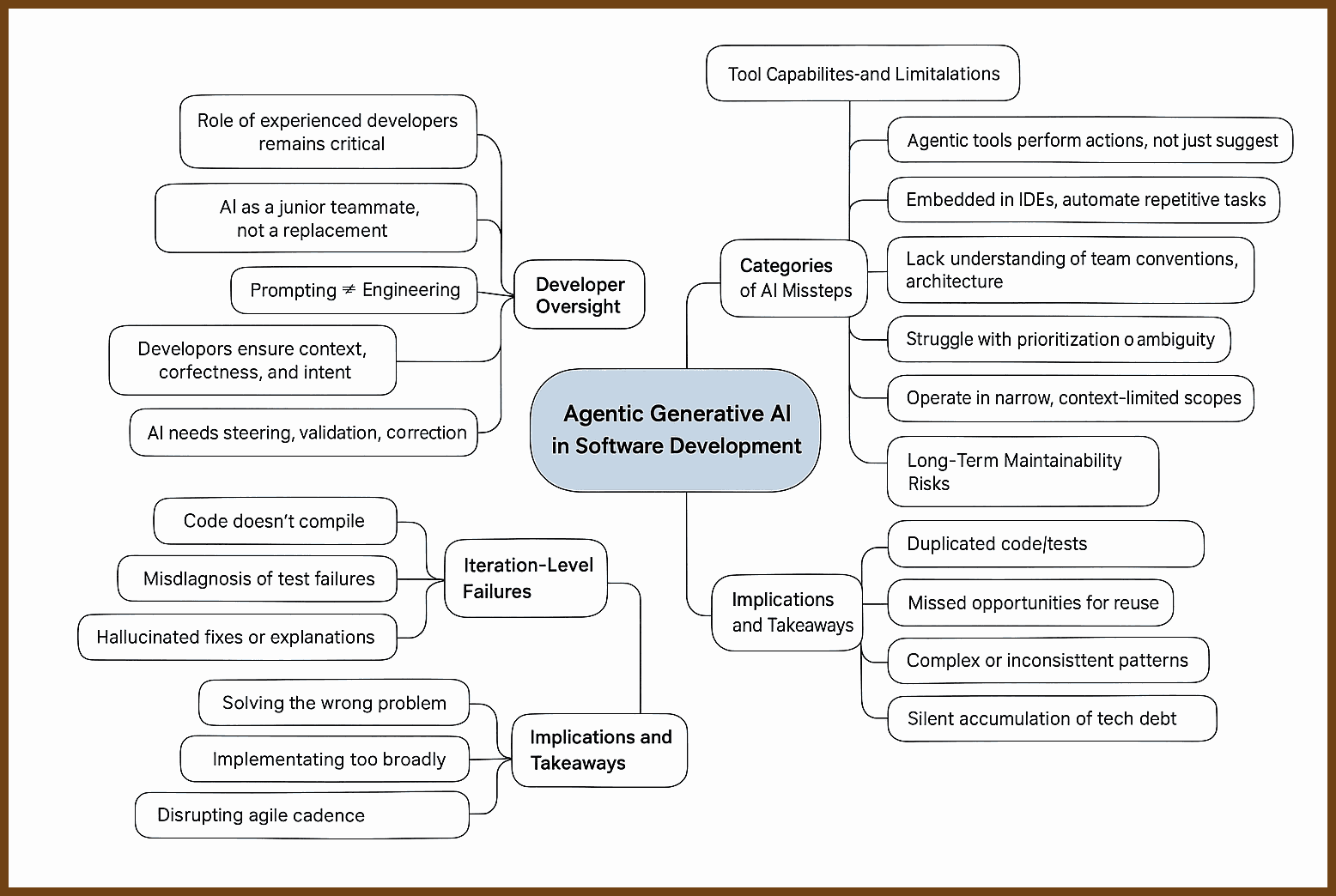
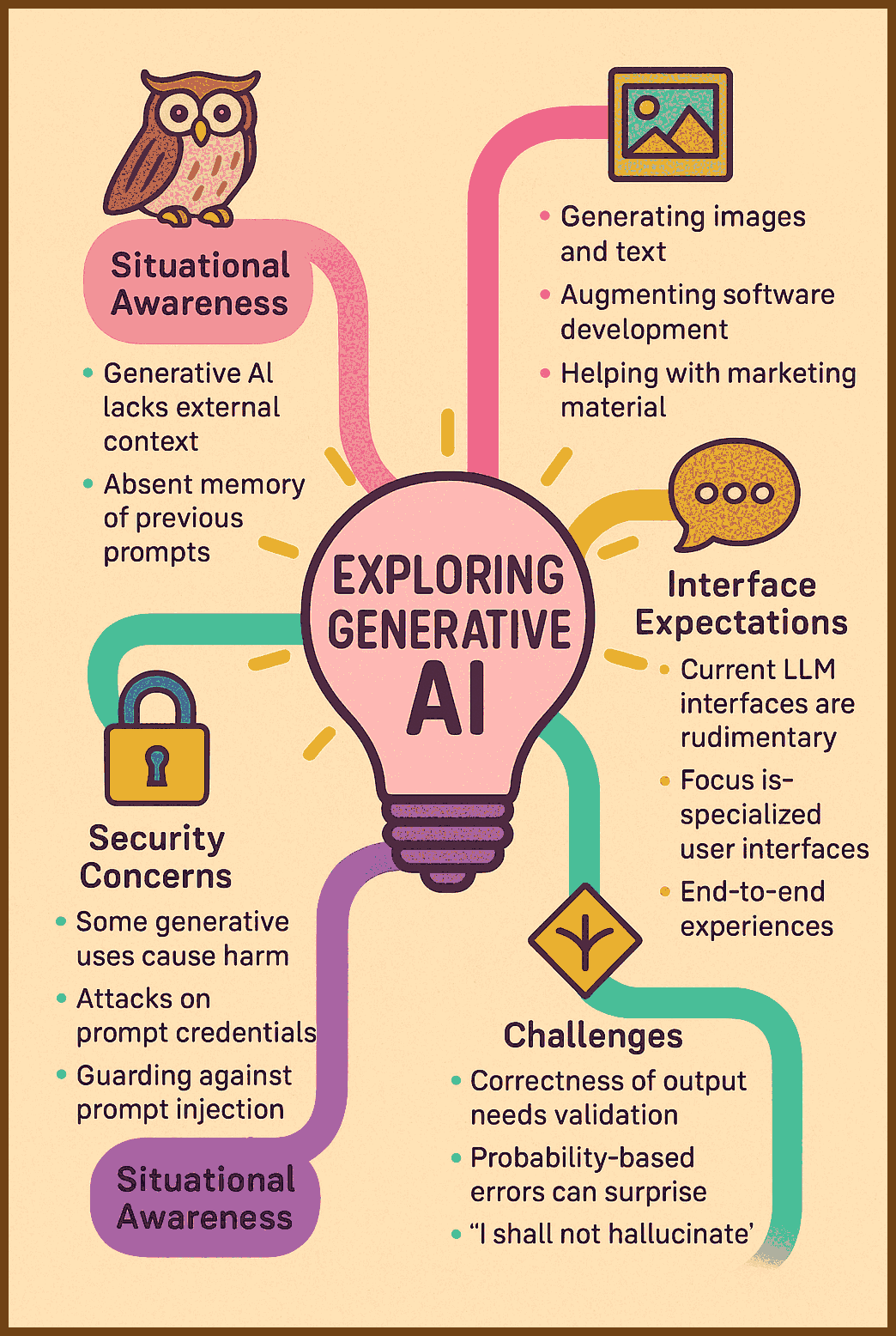
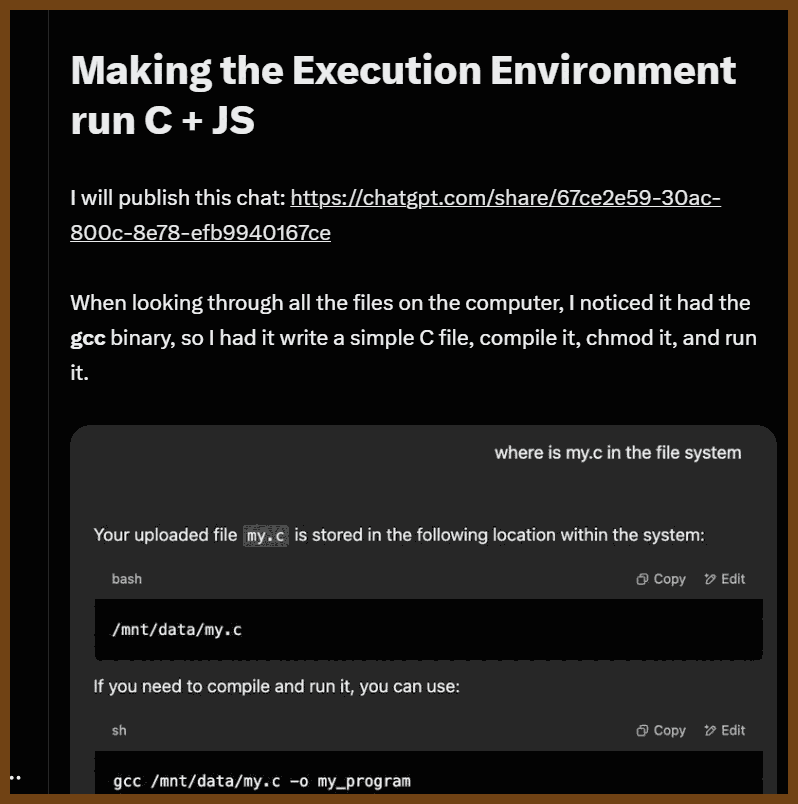
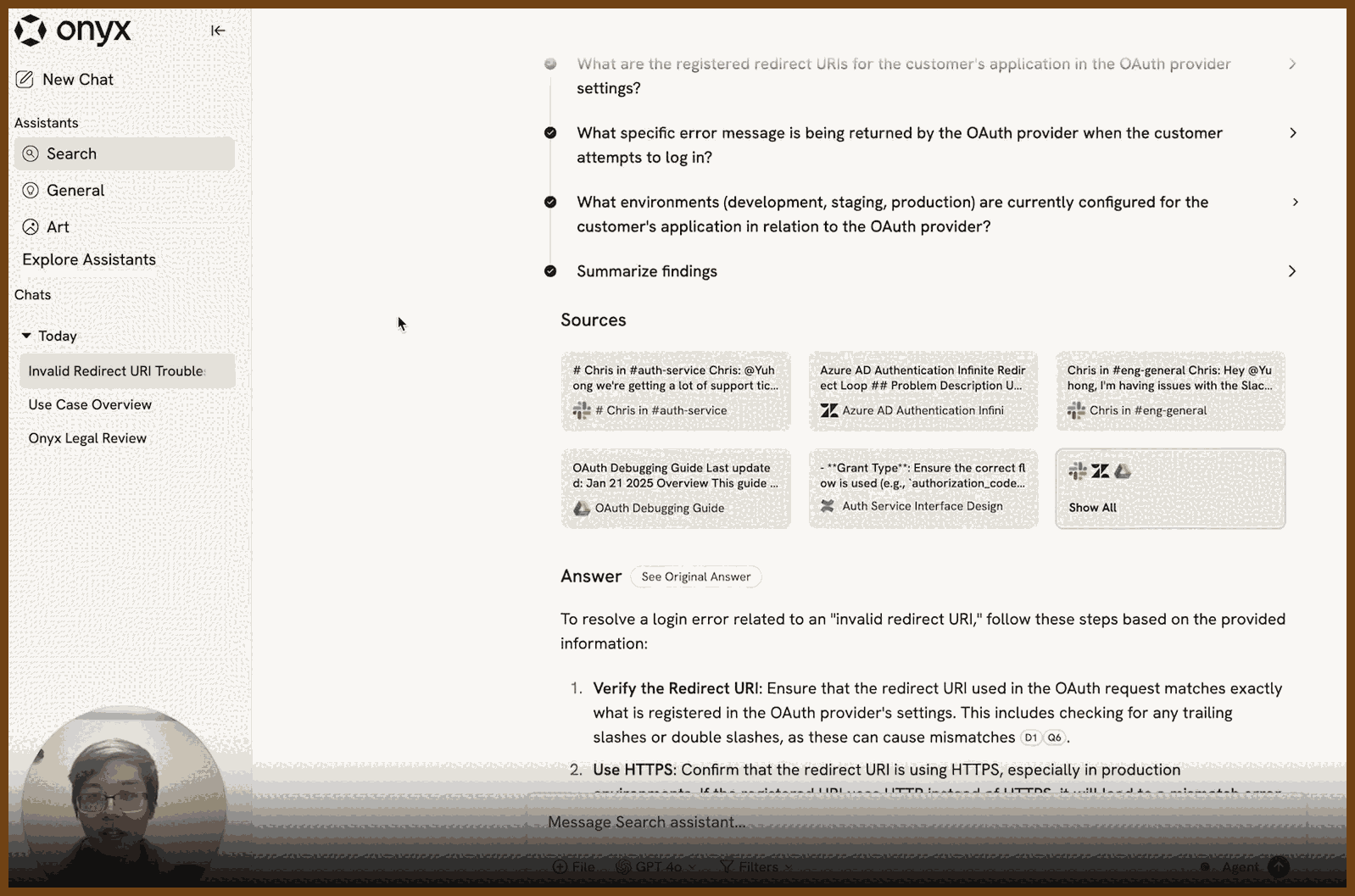


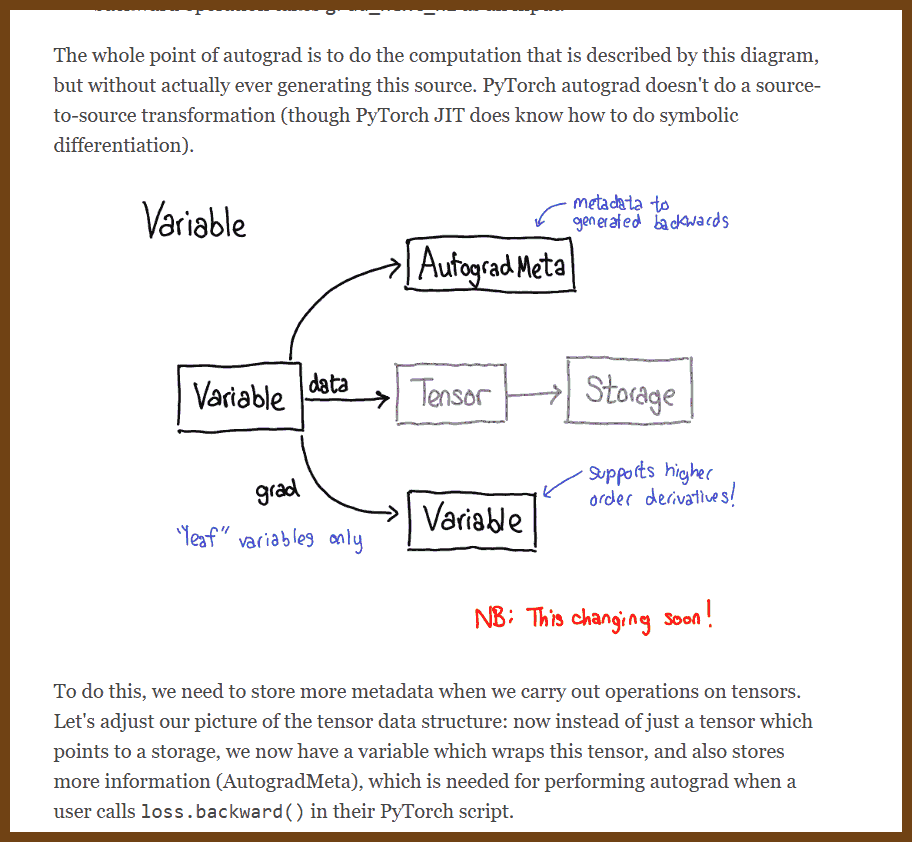
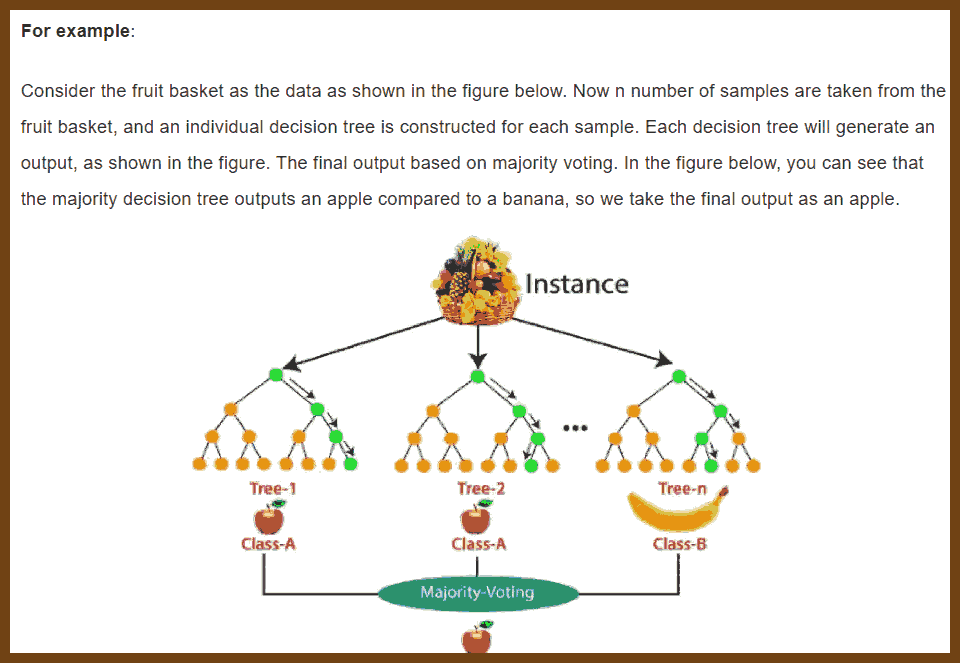

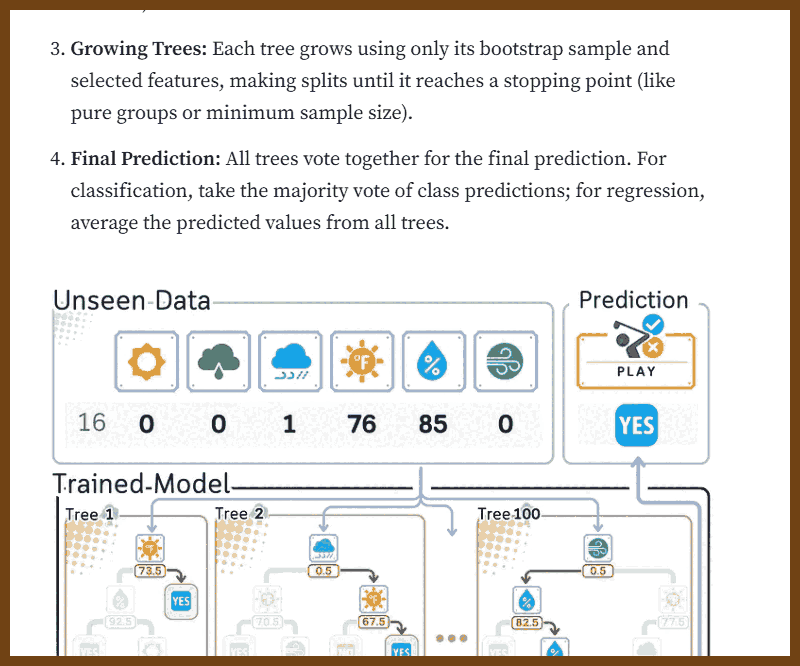

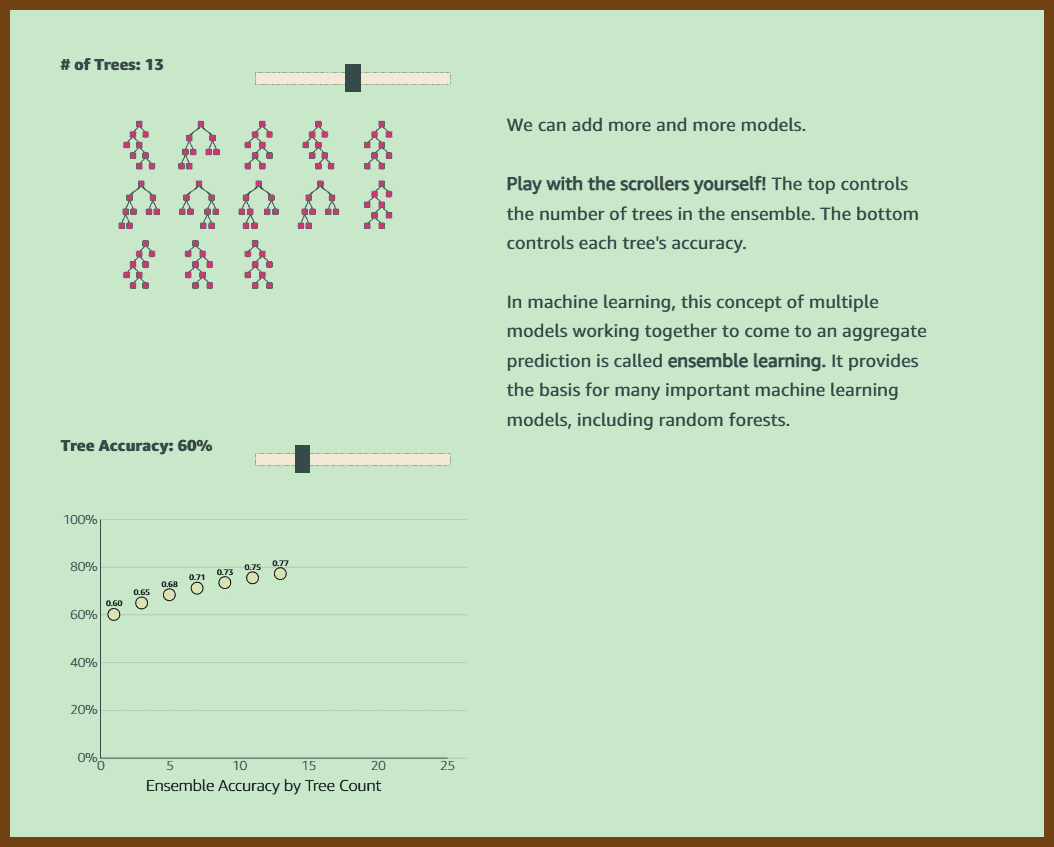
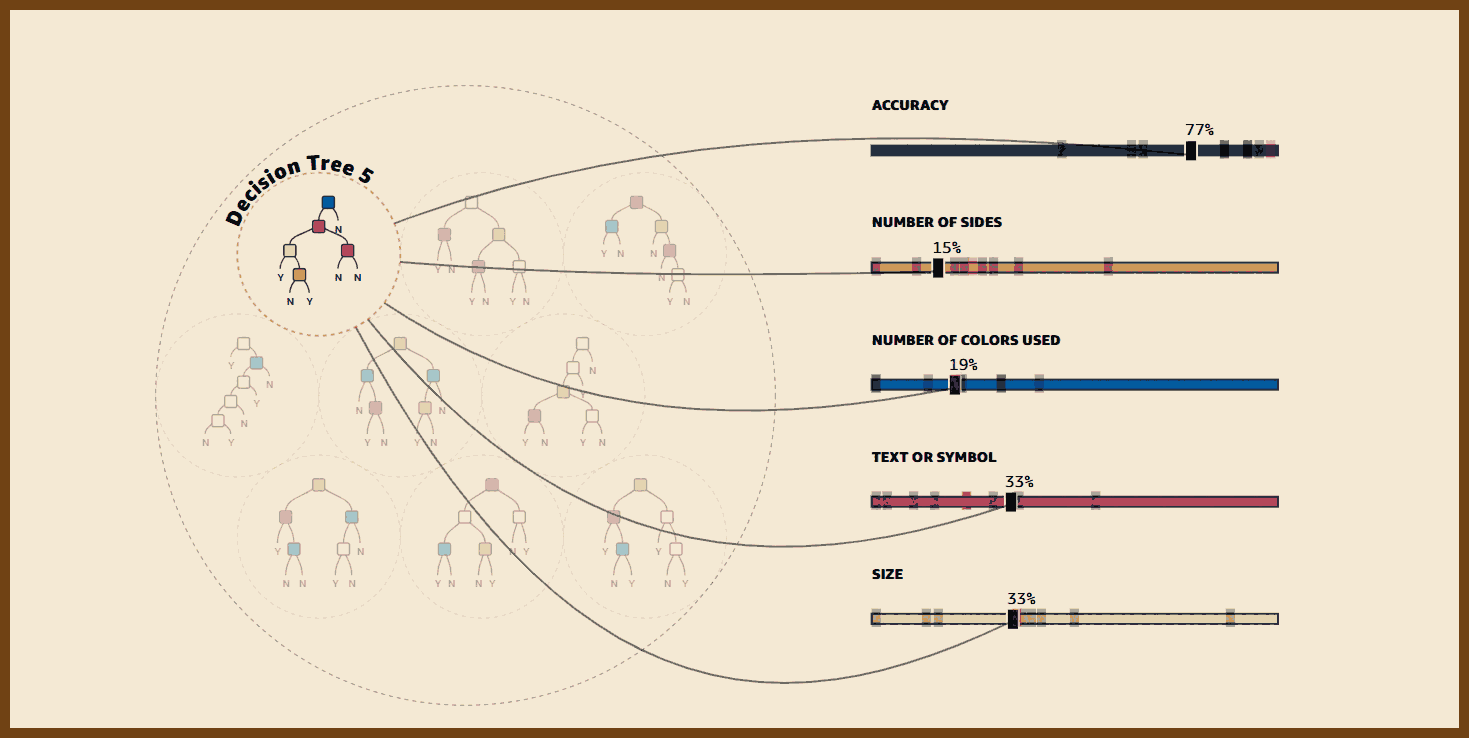
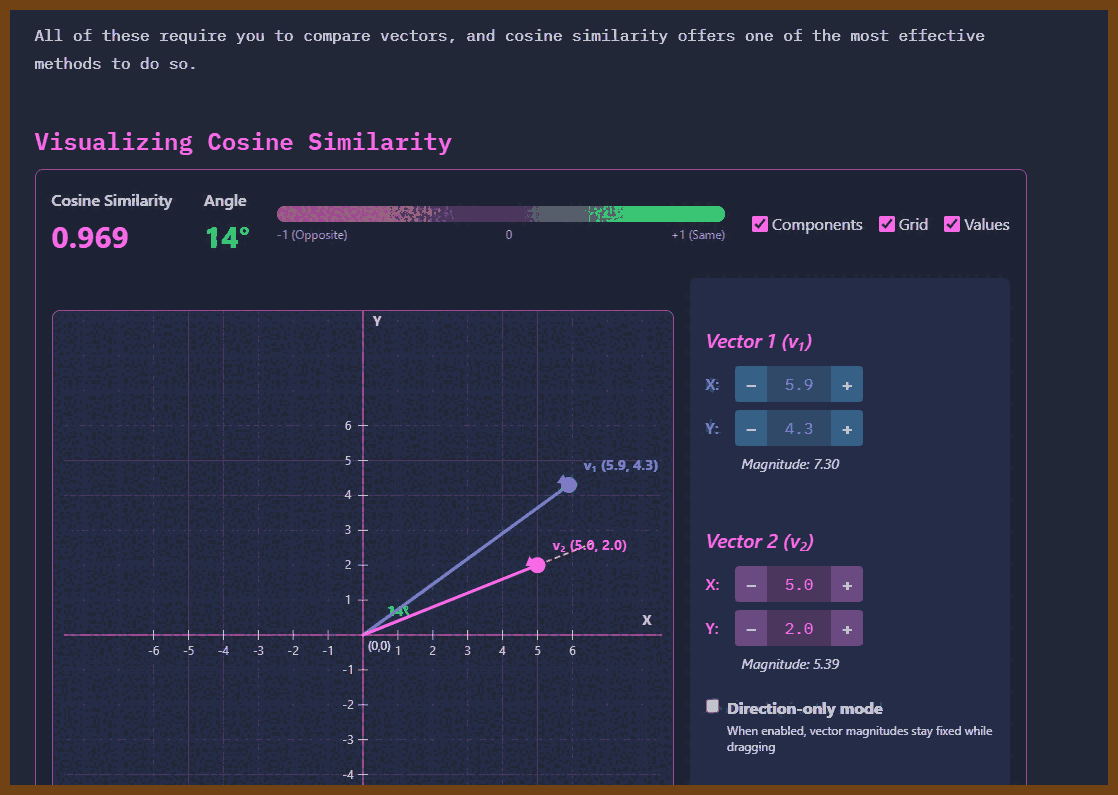
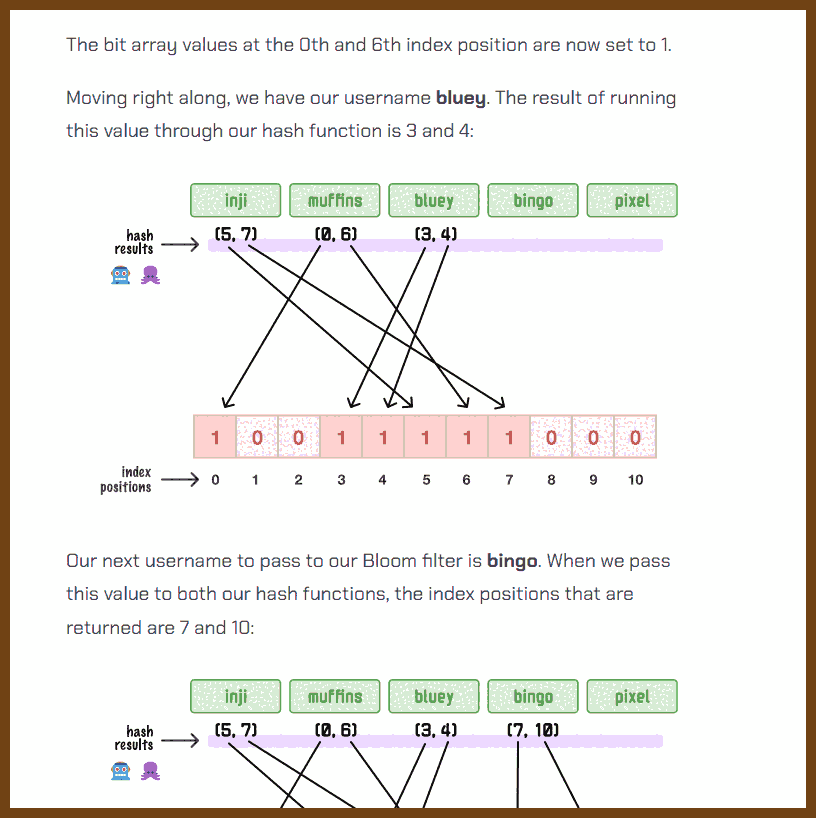





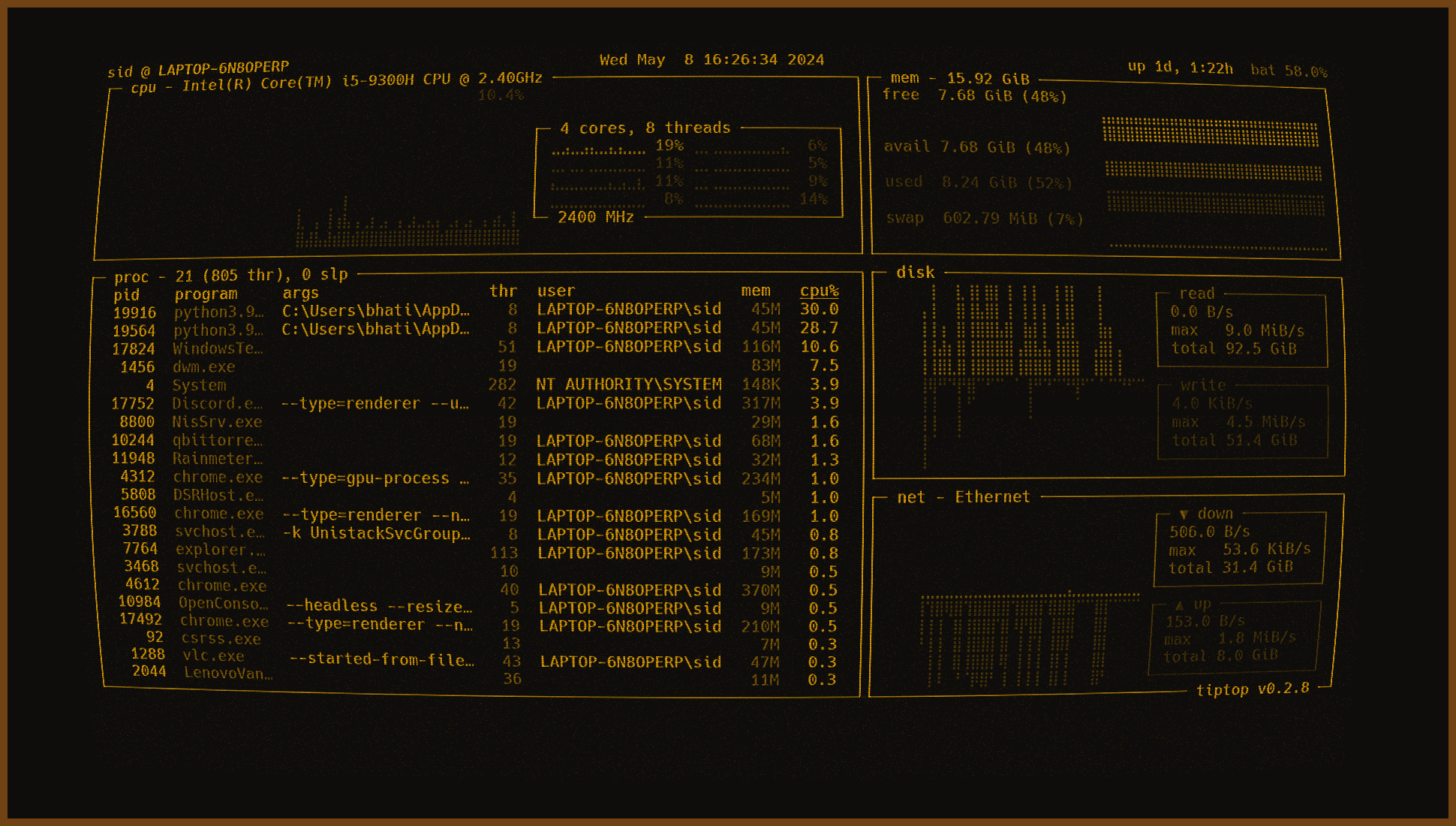


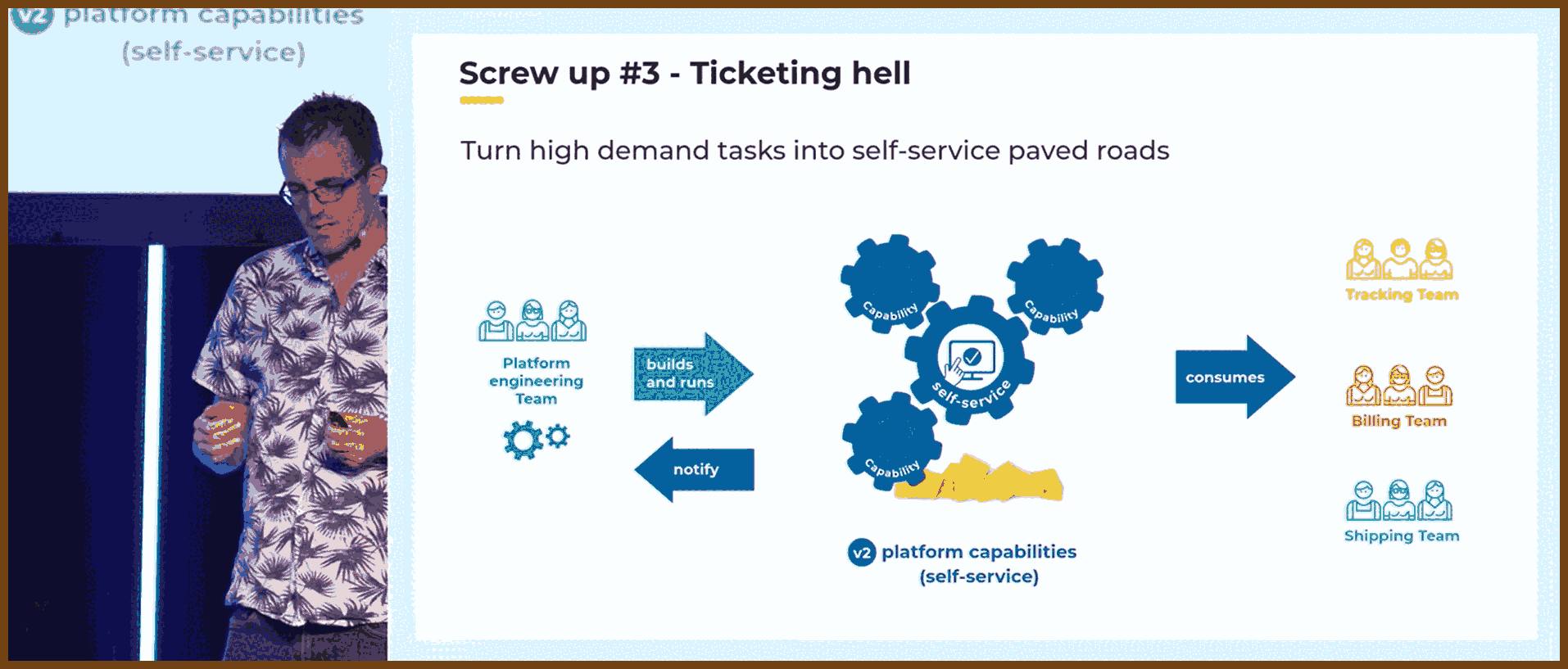
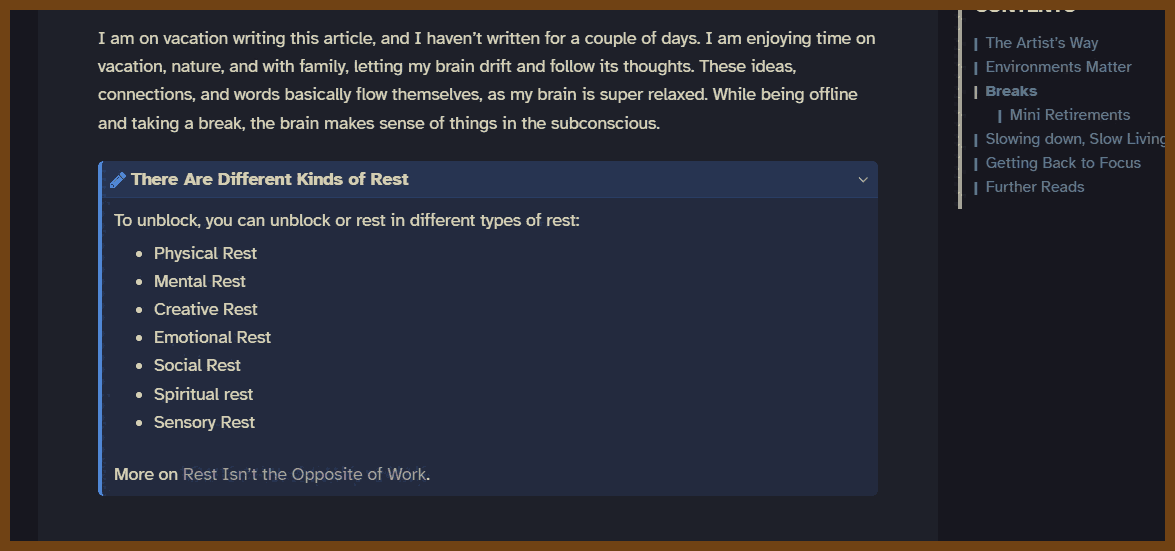
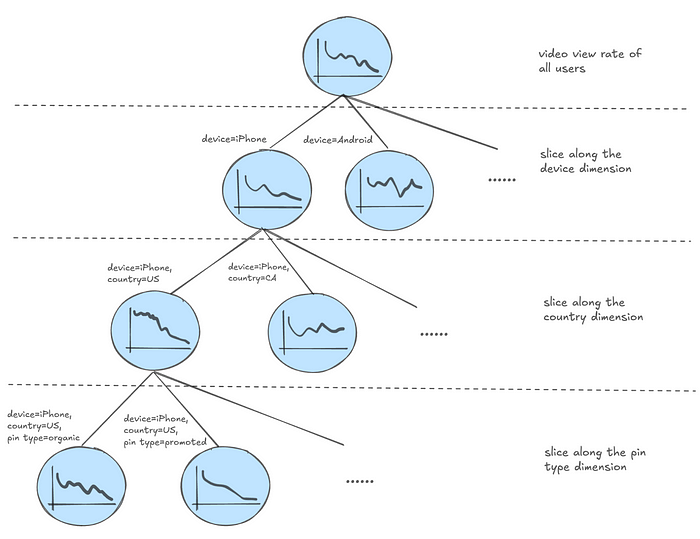 Quotes:
Quotes:
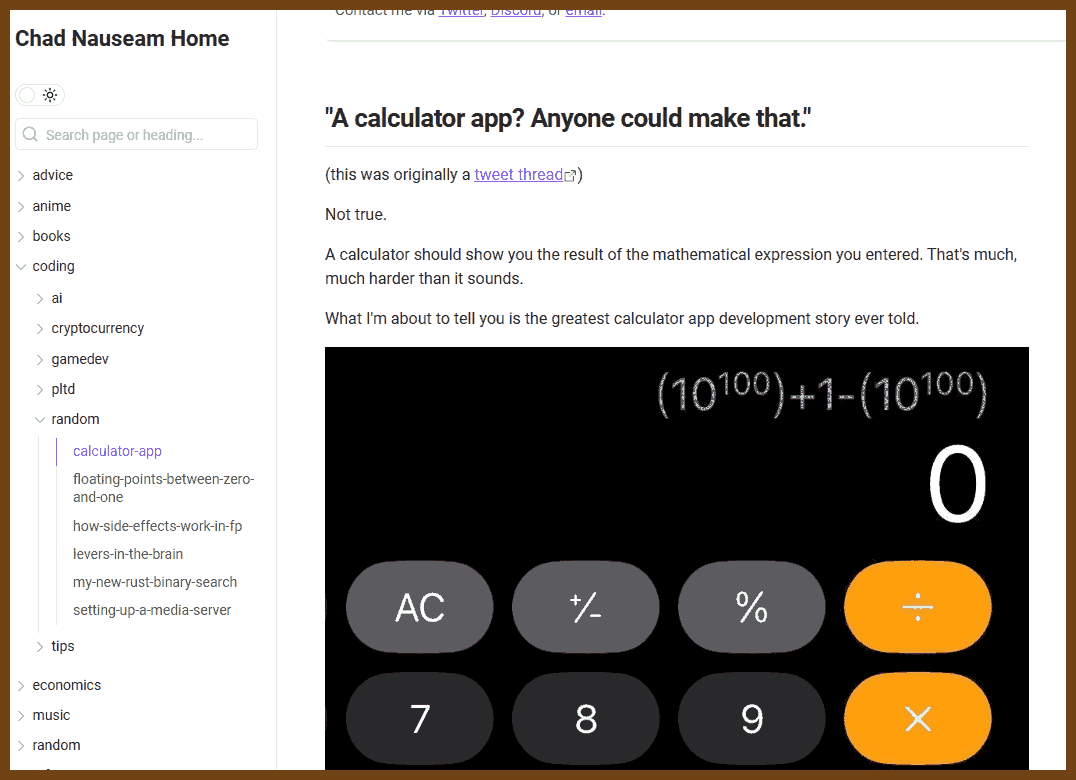






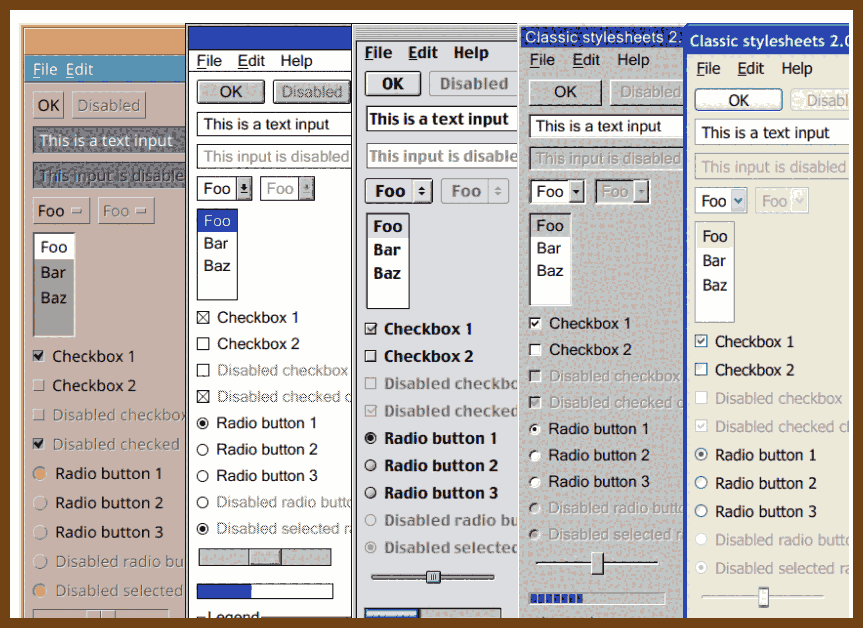
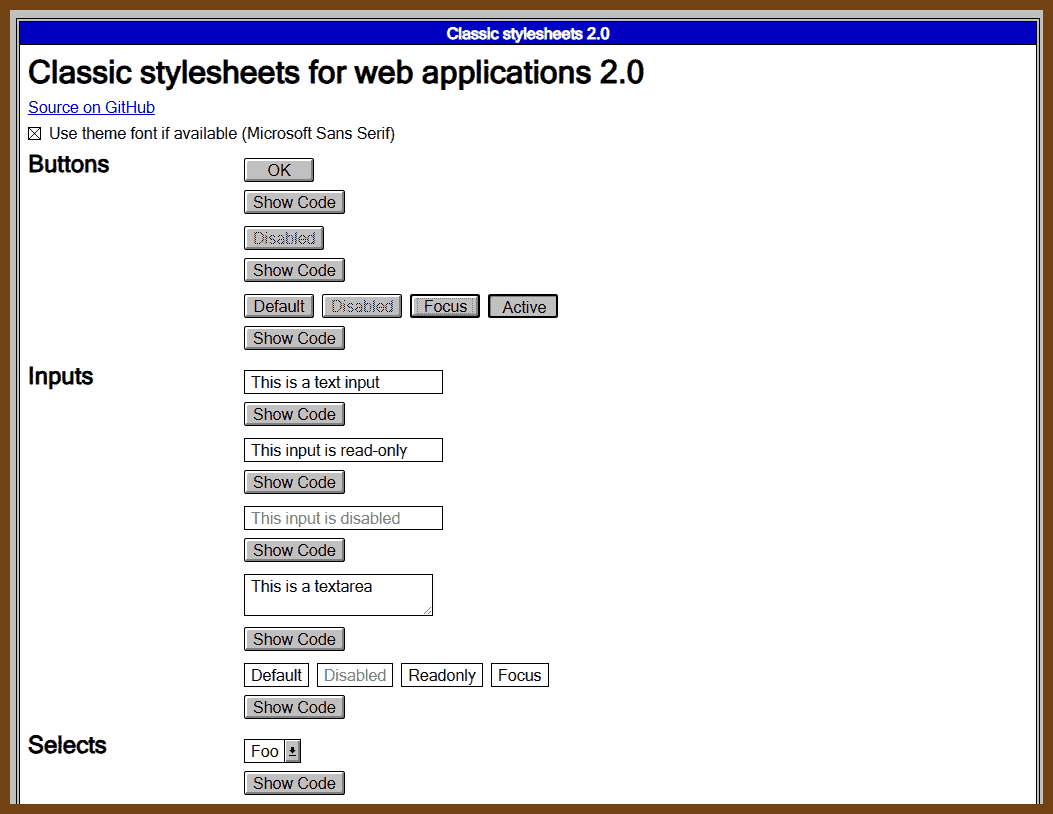
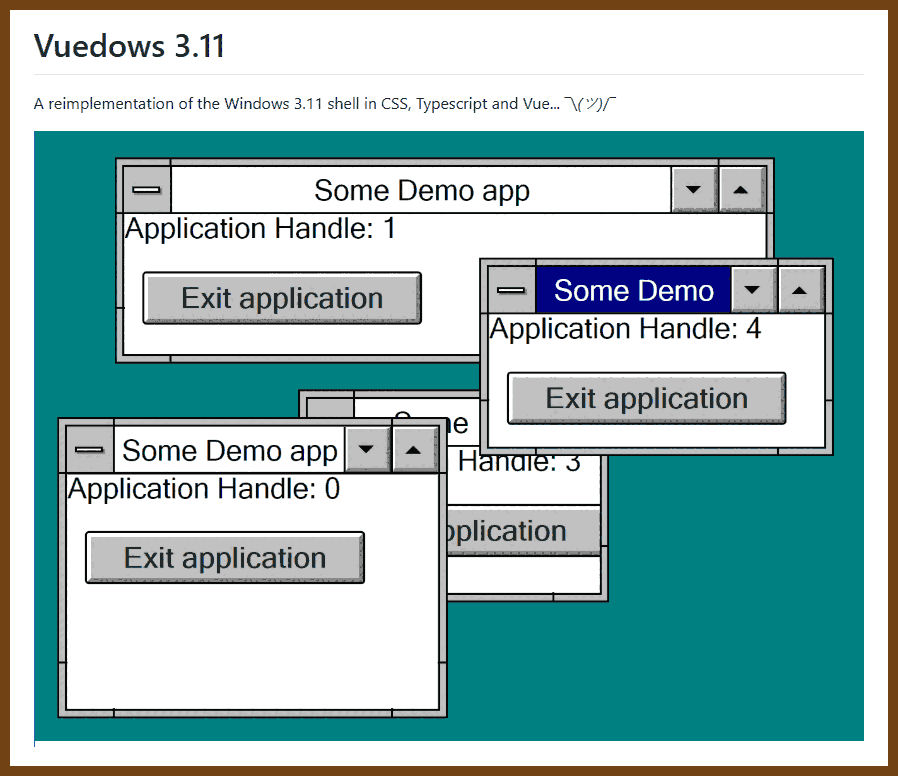

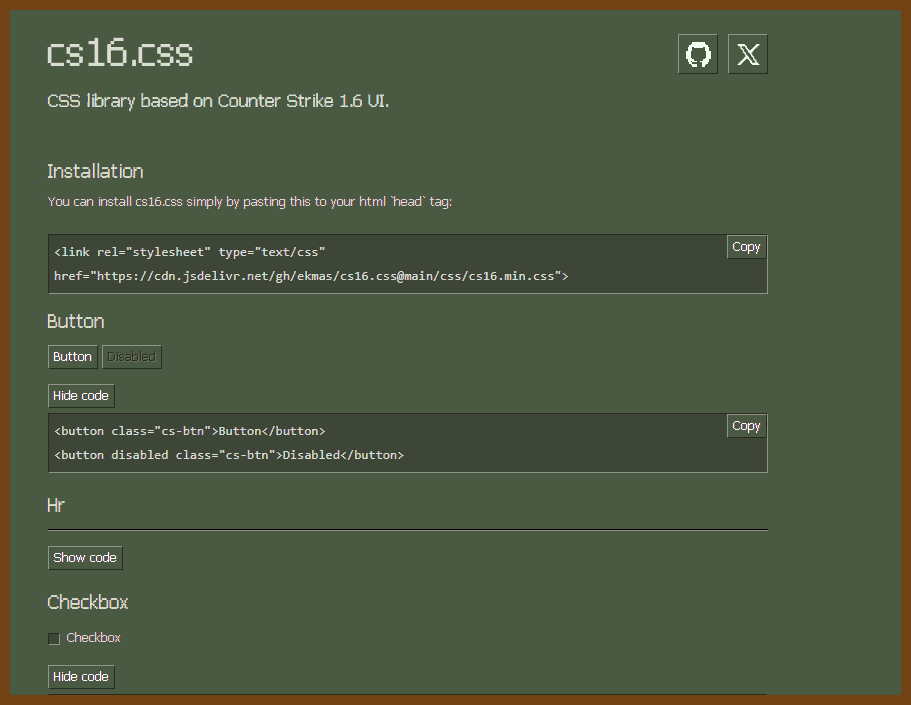


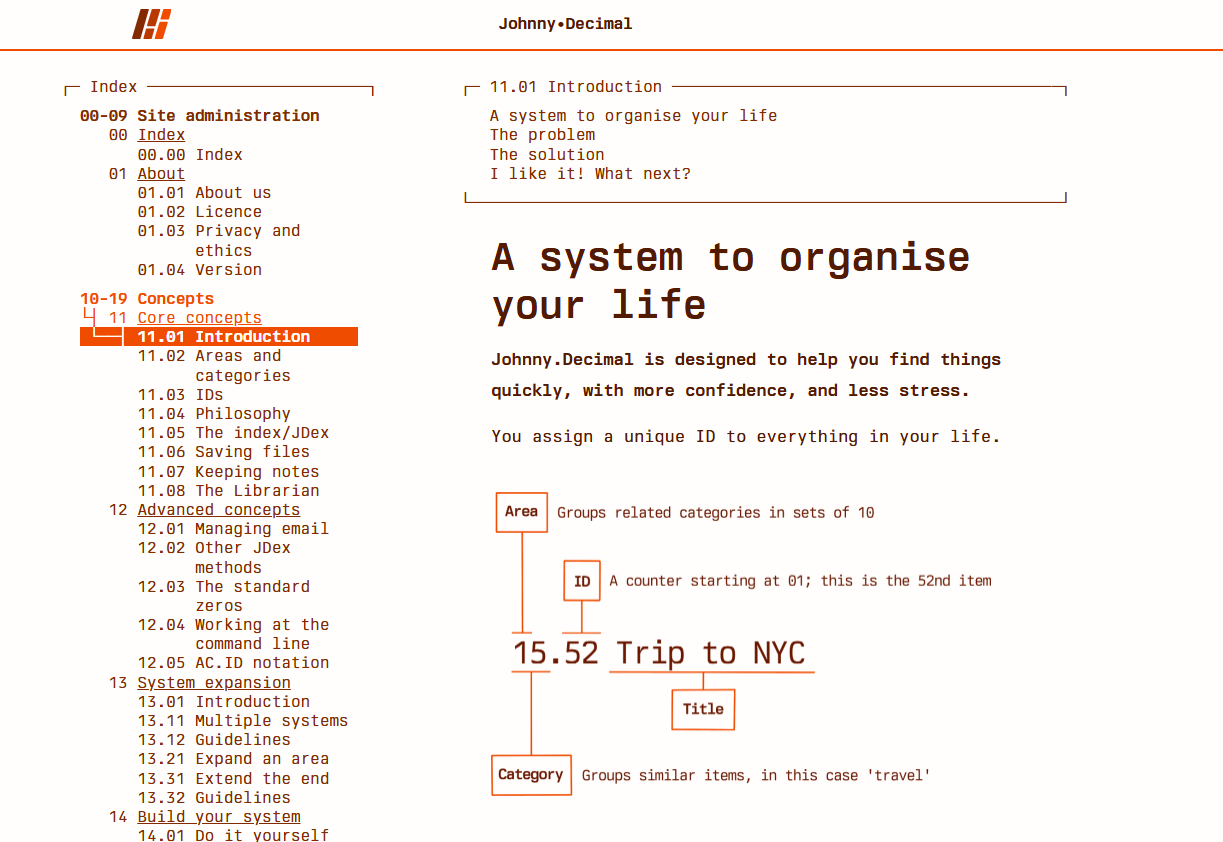
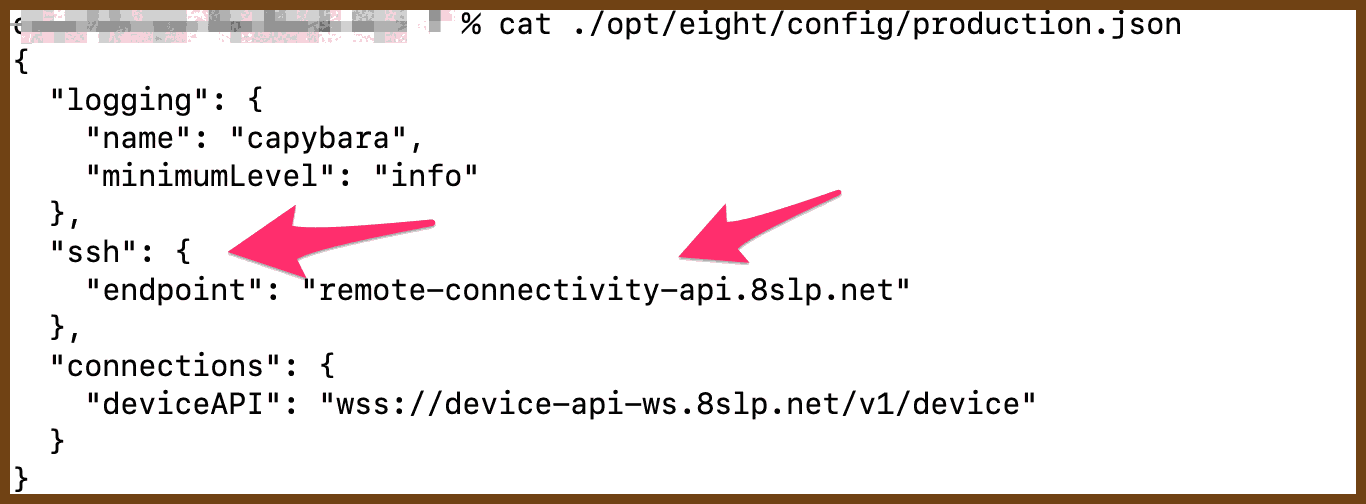

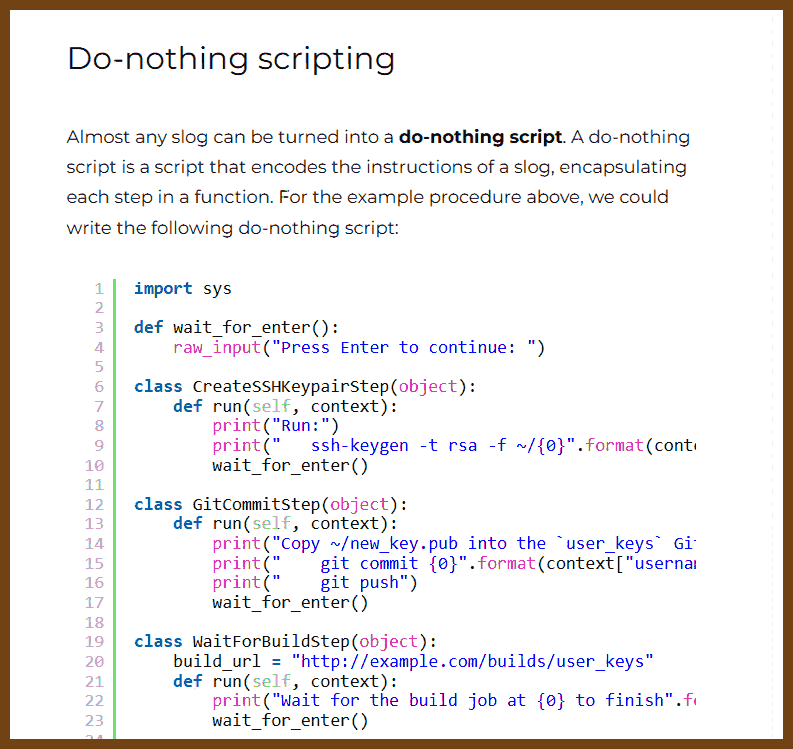 At first glance, it might not be obvious that this script provides value. Maybe it looks like all we’ve done is make the instructions harder to read. But the value of a do-nothing script is immense:
At first glance, it might not be obvious that this script provides value. Maybe it looks like all we’ve done is make the instructions harder to read. But the value of a do-nothing script is immense: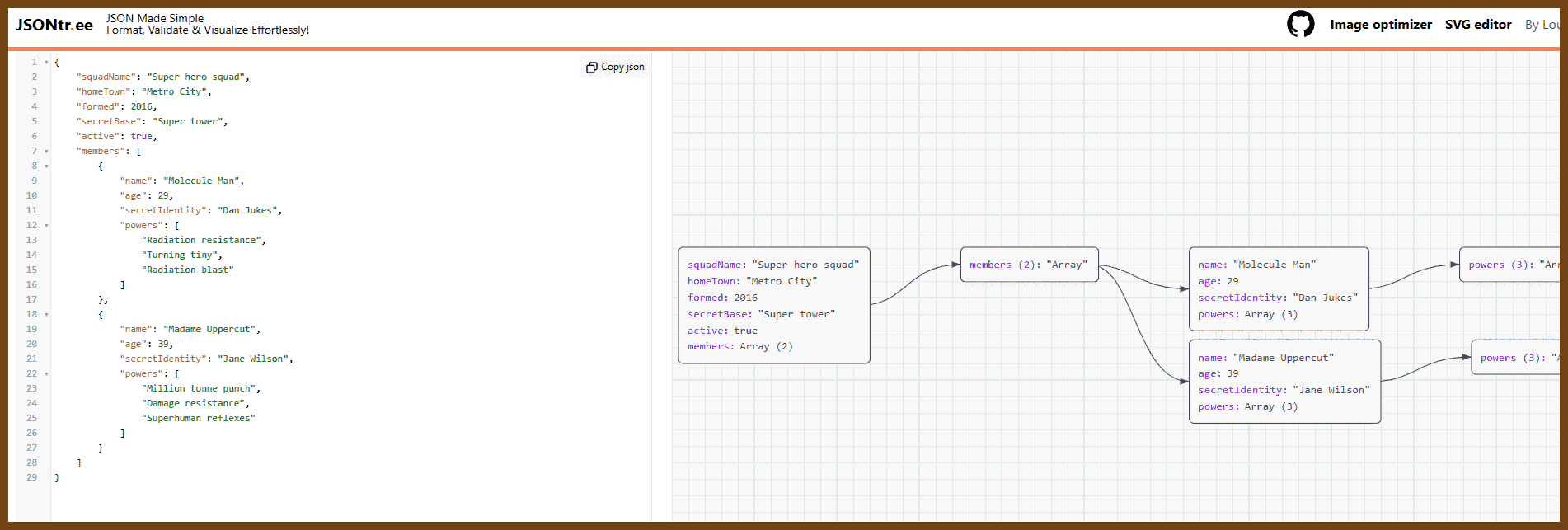
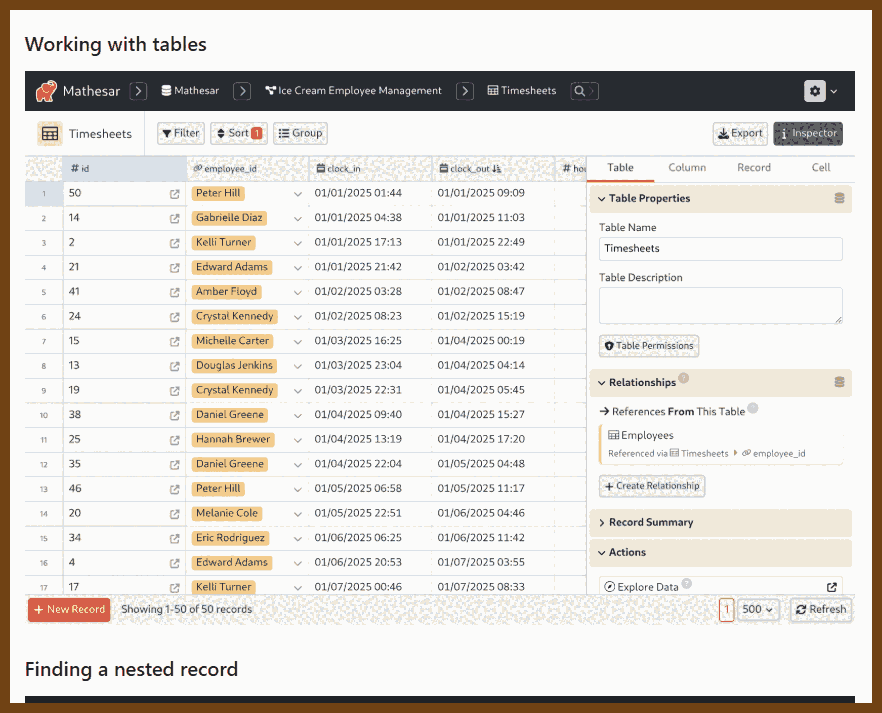

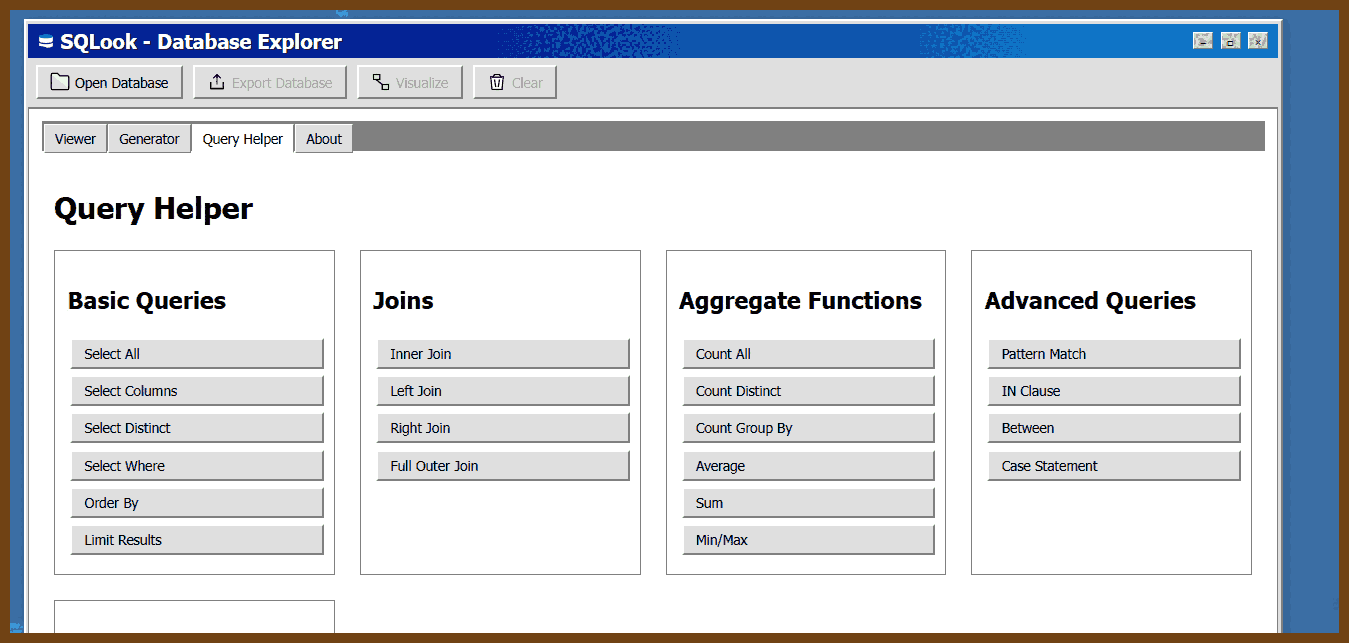
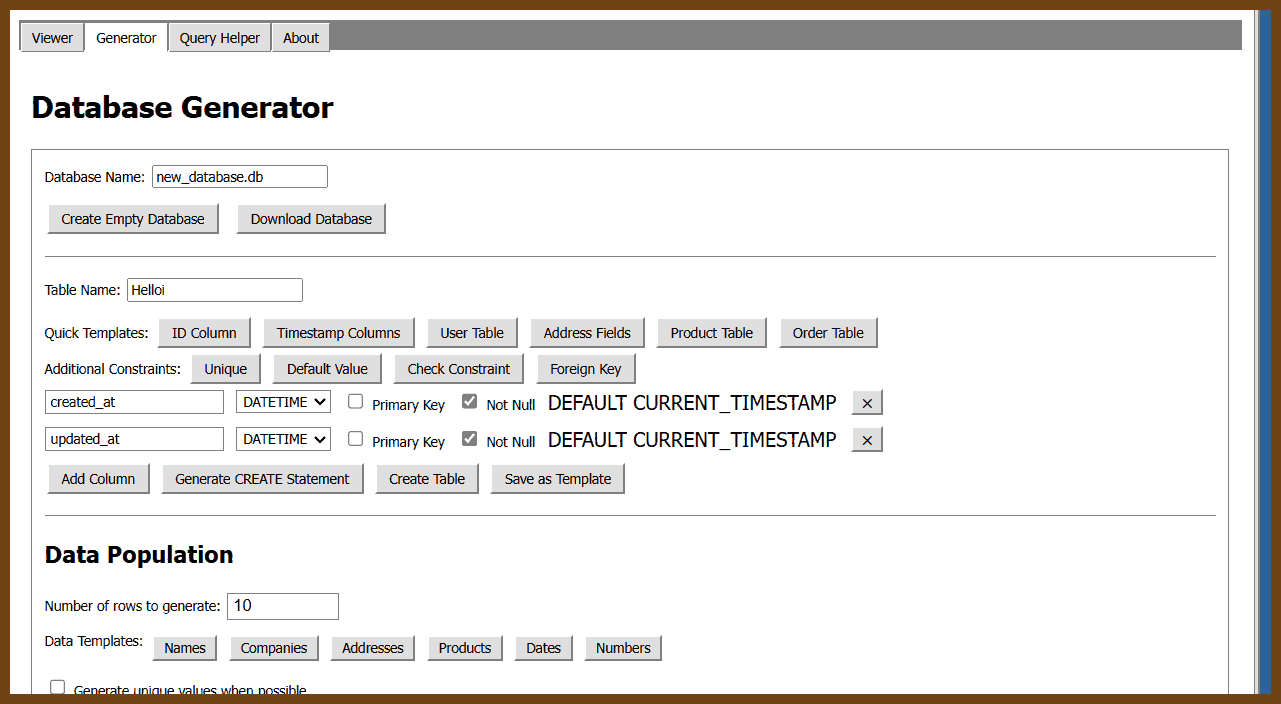
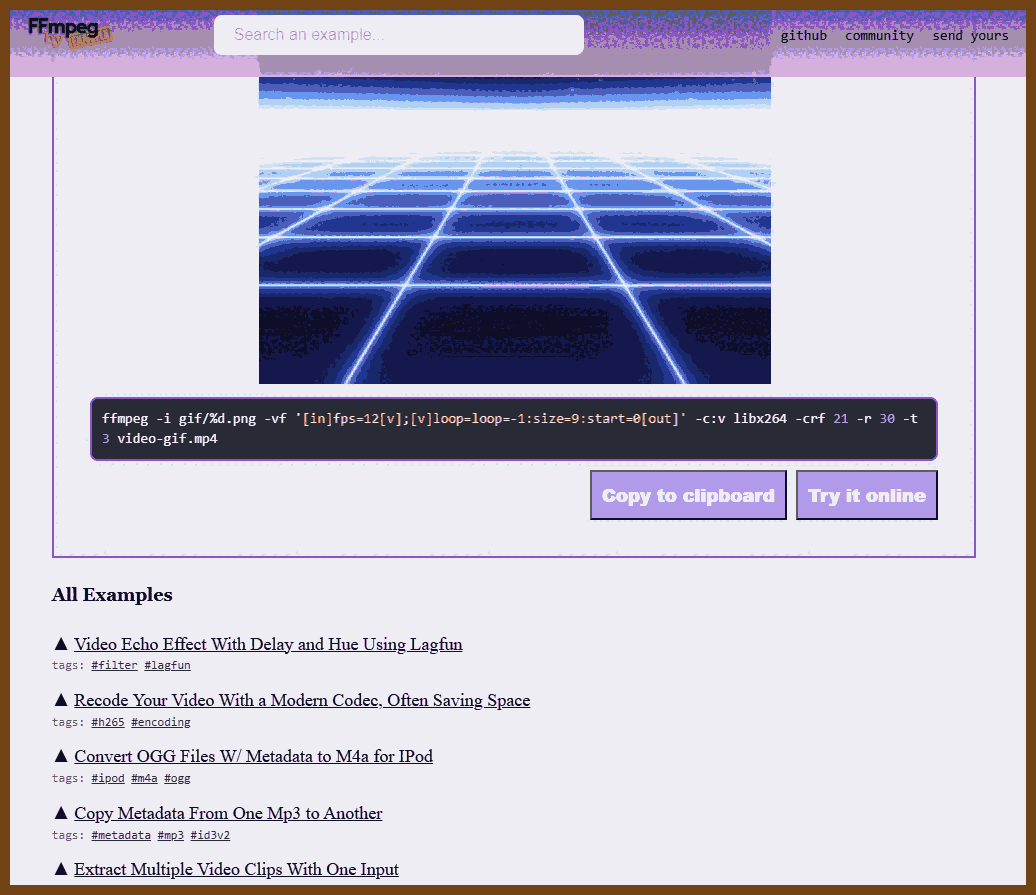
 The goal of font pairing is to select fonts that share an overarching theme yet have a pleasing contrast. Which fonts work together is largely a matter of intuition, but we approach this problem with a neural net. See GitHub for more technical details.
The goal of font pairing is to select fonts that share an overarching theme yet have a pleasing contrast. Which fonts work together is largely a matter of intuition, but we approach this problem with a neural net. See GitHub for more technical details.