dev-scala-spark-synapse-bigdata
Dev Scala, Apache Spark & Big Data
[[TOC]]
Spark
2023-02-07 Overview - Spark 3.3.1 Documentation https://spark.apache.org/docs/latest/
Spark Latest Official Documentation site Apache Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, pandas API on Spark for pandas workloads, MLlib for machine learning, GraphX for graph processing, and Structured Streaming for incremental computation and stream processing.
Programming Guides:
2023-11-05 MrPowers/spark-style-guide: Spark style guide
Spark is an amazingly powerful big data engine that's written in Scala.
This document draws on the Spark source code, the Spark examples, and popular open source Spark libraries to outline coding conventions and best practices.
2023-01-26 GitHub - apache/spark: Apache Spark - A unified analytics engine for large-scale data processing
Apache Spark Github Repository
2023-01-26 GitHub - awesome-spark/awesome-spark
A curated list of awesome Apache Spark packages and resources.
2023-01-26 GitHub - dotnet/spark
.NET for Apache Spark makes Apache Spark easily accessible to .NET developers.
2023-05-03 Databricks Scala Spark API - org.apache.spark.sql.Dataset
Java Docs
Examples
2017 trK54Ylmz/kafka-spark-streaming-example: Simple examle for Spark Streaming over Kafka topic Github
A bit old sample for Spark streaming, but it has some good bash/command line examples
2020 nitinware/spark-starter: spark starter java project
Spark Java Maven Simple starter project
Links
2023-03-13 Add ALL the Things: Abstract Algebra Meets Analytics
2013-03-07 AK Tech Blog 2023-03-14 GitHub - avibryant/simmer: Reduce your data. A unix filter for algebird-powered aggregation. 2023-03-14 GitHub - twitter/algebird: Abstract Algebra for Scala
2023-03-13 Apache Spark Fundamentals | Pluralsight
2023-02-12 awesome-spark/awesome-spark: A curated list of awesome Apache Spark packages and resources.

Videos
2023-02-12 🎥 Apache Spark Core—Deep Dive—Proper Optimization Daniel Tomes Databricks - YouTube
21:14:

2023-02-12 Spark SQL Shuffle Partitions - Spark By {Examples}

spark.sql.shuffle.partitions
Azure Synapse Analytics
Overview
Azure Synapse is a big data analytics service provided by Microsoft that integrates big data and data warehousing into a single platform. It allows organizations to analyze large amounts of data from various sources including structured, semi-structured and unstructured data.
People use Azure Synapse for tasks such as data warehousing, data lake storage, big data analytics, and machine learning.
Main features of Azure Synapse include:
- Seamless integration of big data and data warehousing
- Serverless big data analytics through Spark
- Advanced security and data protection
- Hybrid data management and analytics
- Automated data ingestion and data preparation
- Advanced data visualization and exploration tools.
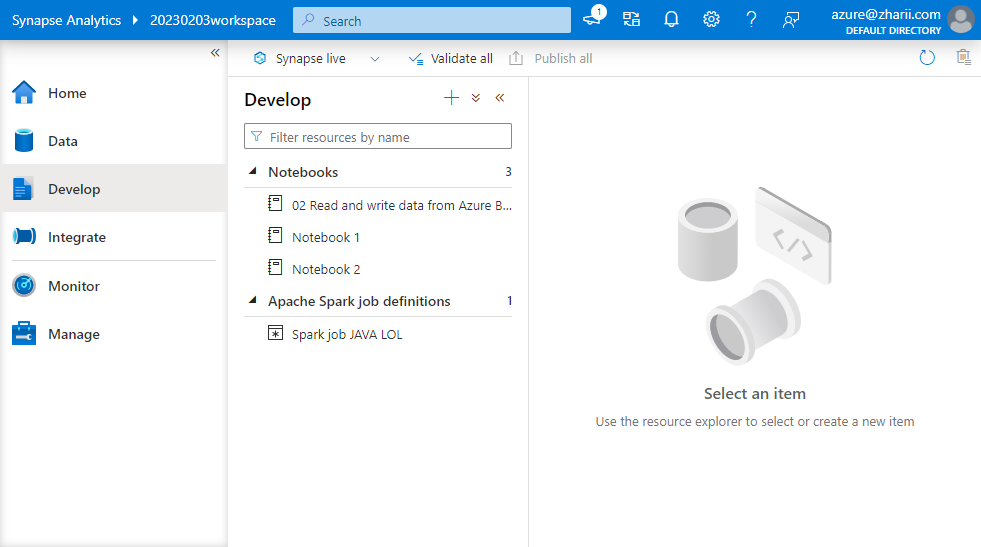
Where the things are:
- Home -- No place like it!
- Data -- Manage / Create internal Hadoop / Spark tables
- Develop -- Upload Spark Jobs, create, import, export and run Notebooks (Python, C#, SQL, Scala)
- Integrate -- Create data ingestion / data processing pipelines with visual editor
- Monitor -- Spark Logs and Metrics
- Manage -- Create Spark Pools, manage resources, create linked resources (link external resources like Cosmos DB, SQL Server, Blob Containers etc.)
Samples
2023-02-07 💖 Azure-Samples/Synapse: Samples for Azure Synapse Analytics GitHub
MSFT: This is a very comprehensive repository with tons of Notebooks and Spark Jobs samples. The best place to start. Contents
2023-02-07 💖 microsoft/SynapseML: Simple and Distributed Machine Learning Github
MSFT: Synapse Machine Learning specific repository.
2023-02-07 Azure Synapse Analytics Workshop (level 400, 4 days) solliancenet/azure-synapse-analytics-workshop-400 Github, Slides
External. Workshop Slides and materials

2023-02-07 💖 Azure Analytics End to End with Azure Synapse - Deployment Accelerator Azure/azure-synapse-analytics-end2end Github
Slides and diagrams and Bicep / ARM Templates for an End to End Solution sample
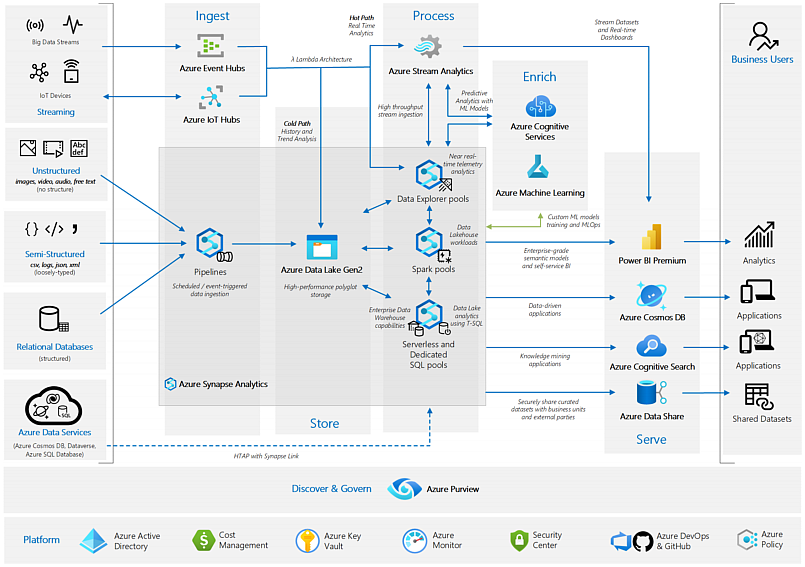
2023-02-07 microsoft/AzureSynapseEndToEndDemo Github
This repository provides one-click infrastructure and artifact deployment for Azure Synapse Analytics to get you started with Big Data Analytics on a large sized Health Care sample data. You will learn how to ingest, process and serve large volumes of data using various components of Synapse.
2023-04-09 Azure Synapse Spark with Scala | DUSTIN VANNOY
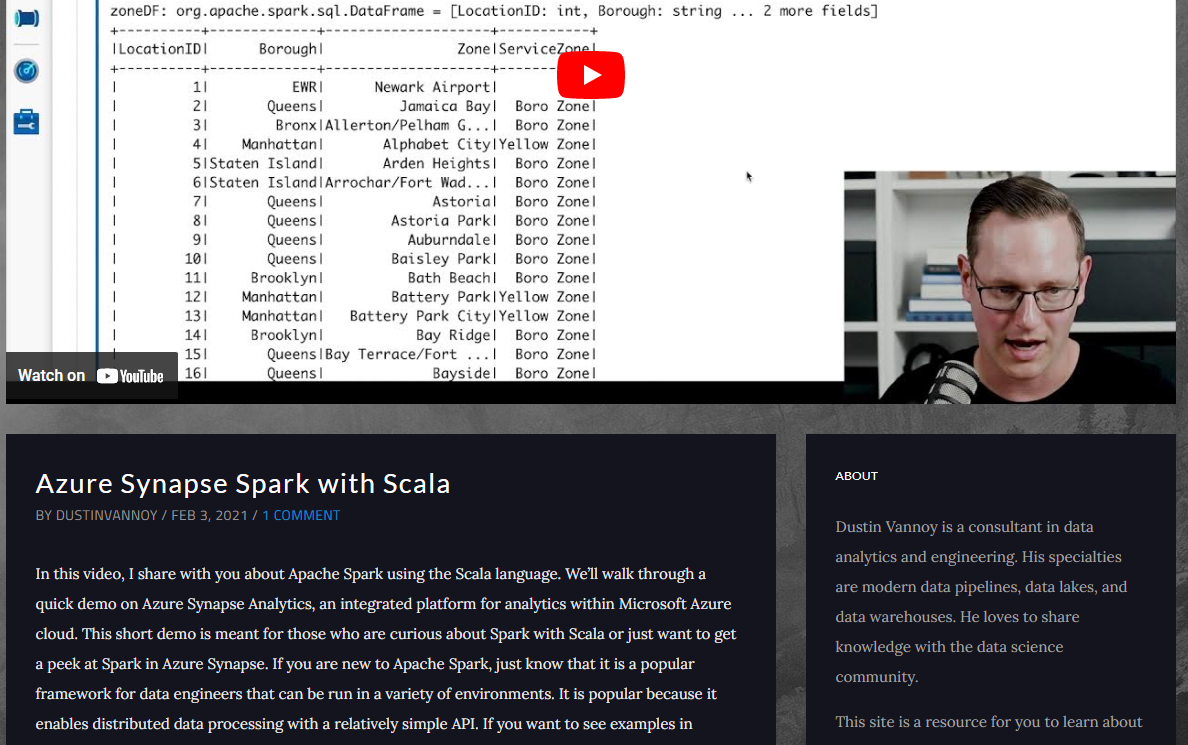
val inputDF = spark.read.parquet(yellowSourcePath)
// Take your pick on how to transform, withColumn or SQL Expressions. Only one of these is needed.
// Option A
// val transformedDF = {
// inputDF
// .withColumn("yearMonth", regexp_replace(substring("tpepPickupDatetime",1,7), '-', '_'))
// .withColumn("pickupDt", to_date("tpepPickupDatetime", dateFormat))
// .withColumn("dropoffDt", to_date("tpepDropoffDatetime", dateFormat))
// .withColumn("tipPct", col("tipAmount") / col("totalAmount"))
// }
// Option B
val transformedDF = inputDF.selectExpr(
"*",
"replace(left(tpepPickupDatetime, 7),'-','_') as yearMonth",
s"to_date(tpepPickupDatetime, '$dateFormat') as pickupDt",
s"to_date(tpepDropoffDatetime, '$dateFormat') as dropoffDt",
"tipAmount/totalAmount as tipPct")
val zoneDF = spark.read.format("delta").load(taxiZonePath)
// Join to bring in Taxi Zone data
val tripDF = {
transformedDF.as("t")
.join(zoneDF.as("z"), expr("t.PULocationID == z.LocationID"), joinType="left").drop("LocationID")
.withColumnRenamed("Burough", "PickupBurrough")
.withColumnRenamed("Zone", "PickupZone")
.withColumnRenamed("ServiceZone", "PickupServiceZone")
}
tripDF.write.mode("overwrite").partitionBy("yearMonth").format("delta").save(yellowDeltaPath)
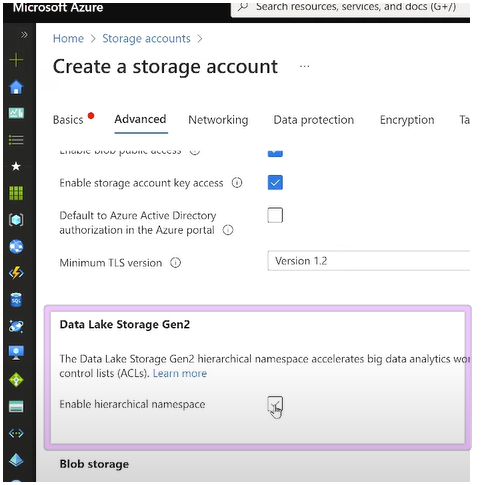
Azure Data Lake Storage Gen 2
2023-02-03 Azure Data Lake Storage Gen 2 Overview - YouTube

Gen2 is build on top of Storage Account with this option enabled (Enable hierarchical namespace):
HNS enables real folder structure in blob storage containers.
Azure Data Lake URIs
wasbs://is Windows Azure Storage Blob (WASB) + S (Secure) example:wasbs://8f871c14-f903-42a8-9011-7d6fb48896af@cl3p8zpng3juv1ahtsv6cpl2.blob.core.windows.net/events/...used as URI in Hadoop / Yarn / Sparkabfss://stands for Azure Blob File System + S (Secure) and Microsoft recommends it for big data workloads as it is optimized for it. Sample:abfss://myfstest@datalakestorealpha.dfs.core.windows.net/synapse/workspaces/20230203workspace/...
Scala and Spark
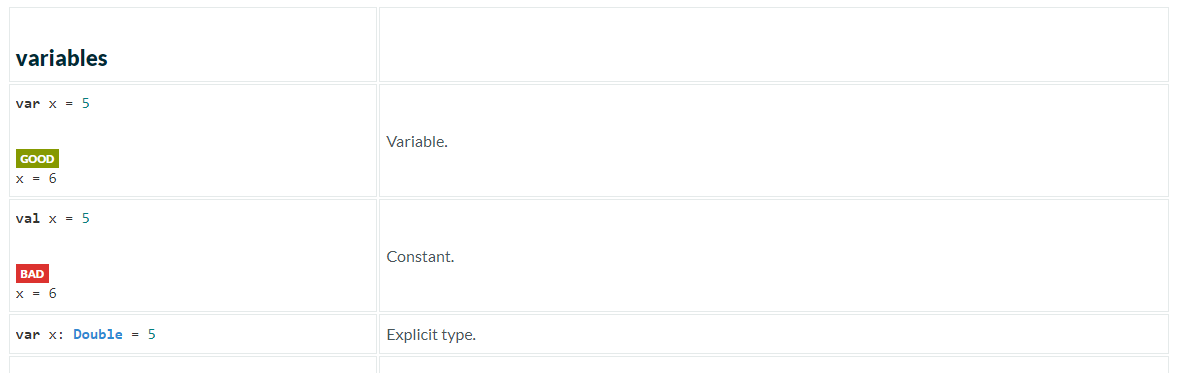
2023-02-26 🔥 Scala Cheatsheet Scala Documentation
2023-04-11 #Scala Crash Course by a Scala Veteran (with some JavaScript flavor) - YouTube
2023-04-10 Scala Tutorial - YouTube
Derek Banas Cheatsheet: 2023-04-10 Learn Scala in One Video
Scala Syntax cheat sheet
// Shorthand notation (No randInt++, or randInt--)
randInt += 1
"randInt += 1" + randInt
2023-04-10 Getting Started | Scala Documentation
cs install scala:2.11.12 && cs install scalac:2.11.12
2023-04-03 implicits Object — Implicits Conversions · The Internals of Spark SQL
The Internals of Spark SQL (Apache Spark 2.4.5)
Welcome to The Internals of Spark SQL online book!
I’m Jacek Laskowski, a freelance IT consultant, software engineer and technical instructor specializing in Apache Spark, Apache Kafka, Delta Lake and Kafka Streams (with Scala and sbt).
2023-04-03 The Internals of Apache Spark
Spark Notes



2023-02-12 Spark SQL Shuffle Partitions - Spark By {Examples}
In this Apache Spark Tutorial, you will learn Spark with Scala code examples and every sample example explained here is available at Spark Examples Github Project for reference. All Spark examples provided in this Apache Spark Tutorial are basic, simple, and easy to practice for beginners who are enthusiastic to learn Spark, and these sample examples were tested in our development environment.
2023-02-12 SQL Window Functions: Ranking
This is an excerpt from my book SQL Window Functions Explained. The book is a clear and visual introduction to the topic with lots of practical exercises.
Ranking means coming up with all kinds of ratings, starting from the winners of the World Swimming Championships and ending with the Forbes 500.
We will rank records from the toy
employeestable:┌────┬───────┬────────┬────────────┬────────┐
│ id │ name │ city │ department │ salary │
├────┼───────┼────────┼────────────┼────────┤
│ 11 │ Diane │ London │ hr │ 70 │
│ 12 │ Bob │ London │ hr │ 78 │
│ 21 │ Emma │ London │ it │ 84 │
│ 22 │ Grace │ Berlin │ it │ 90 │
│ 23 │ Henry │ London │ it │ 104 │
│ 24 │ Irene │ Berlin │ it │ 104 │
│ 25 │ Frank │ Berlin │ it │ 120 │
│ 31 │ Cindy │ Berlin │ sales │ 96 │
│ 32 │ Dave │ London │ sales │ 96 │
│ 33 │ Alice │ Berlin │ sales │ 100 │
└────┴───────┴────────┴────────────┴────────┘Table of contents:
2023-02-12 Apache Spark Core—Deep Dive—Proper Optimization Daniel Tomes Databricks - YouTube
Optimizing spark jobs through a true understanding of spark core. Learn: What is a partition? What is the difference between read/shuffle/write partitions? How to increase parallelism and decrease output files? Where does shuffle data go between stages? What is the "right" size for your spark partitions and files? Why does a job slow down with only a few tasks left and never finish? Why doesn't adding nodes decrease my compute time?

2023-02-11 How to Train Really Large Models on Many GPUs? Lil'Log
In recent years, we are seeing better results on many NLP benchmark tasks with larger pre-trained language models. How to train large and deep neural networks is challenging, as it demands a large amount of GPU memory and a long horizon of training time.
However an individual GPU worker has limited memory and the sizes of many large models have grown beyond a single GPU. There are several parallelism paradigms to enable model training across multiple GPUs, as well as a variety of model architecture and memory saving designs to help make it possible to train very large neural networks.
2023-01-25 Event Hubs ingestion performance and throughput Vincent-Philippe Lauzon’s
Here are some recommendations in the light of the performance and throughput results:
If we send many events: always reuse connections, i.e. do not create a connection only for one event. This is valid for both AMQP and HTTP. A simple Connection Pool pattern makes this easy.
If we send many events & throughput is a concern: use AMQP.
If we send few events and latency is a concern: use HTTP / REST.
If events naturally comes in batch of many events: use batch API.
If events do not naturally comes in batch of many events: simply stream events. Do not try to batch them unless network IO is constrained.
If a latency of 0.1 seconds is a concern: move the call to Event Hubs away from your critical performance path.
Let’s now look at the tests we did to come up with those recommendations.
2023-02-16 From ES6 to Scala: Basics - Scala.js
2023-02-15 GitHub - alexandru/scala-best-practices: A collection of Scala best practices
2023-02-15 lauris/awesome-scala: A community driven list of useful Scala libraries, frameworks and software.
2023-02-15 Scalafix · Refactoring and linting tool for Scala
2023-02-14 zouzias/spark-hello-world: A simple hello world using Apache Spark
2023-02-14 sbt Reference Manual — Installing sbt on Windows
2023-02-14 lolski/sbt-cheatsheet: Simple, no-nonsense guide to getting your Scala project up and running
2023-02-14 marconilanna/scala-boilerplate: Starting point for Scala projects
2023-02-13 Hyperspace indexes for Apache Spark - Azure Synapse Analytics Microsoft Learn
2023-02-13 The Azure Spark Showdown - Databricks VS Synapse Analytics - Simon Whiteley - YouTube
2023-02-06 ossu/computer-science: Path to a free self-taught education in Computer Science!
Parquet
2023-04-04 Parquet: more than just "Turbo CSV"